大数据技术原理与应用 第一篇 大数据基础 笔记
目录
第一章 大数据概述
一、 大数据时代
1.1 三次信息化浪潮
1.2 信息科技发展
1.3 数据产生方式的变革
1.4 大数据的影响
二、 大数据的概念
2.1 大数据的特征
2.2 大数据关键技术
2.3 大数据计算模式、
2.4 大数据产业
三、 大数据与云计算、物联网
3.1 云计算
3.2 物联网
3.3 大数据与云计算、物联网的关系
第二章 大数据处理架构Hadoop
一、 概述
1.1 Hadoop简介
1.2 Hadoop特性
1.3 Hadoop版本问题
1.4 Hadoop生态
大数据技术原理与应用 第一篇 大数据基础 中 第一章大数据概述和第二章大数据处理架构 知识点总结与理解
第一章 大数据概述
一、 大数据时代
1.1 三次信息化浪潮
| 信息化浪潮 |
发生时间 |
标志 |
解决问题 |
| 第一次信息化浪潮 |
1980年前后 |
个人计算机普及 |
信息处理 |
| 第二次信息化浪潮 |
1995年前后 |
互联网时代 |
信息传输 |
| 第三次信息化浪潮 |
2010年前后 |
大数据时代(大数据,云计算和物联网) |
信息爆炸 |
1.2 信息科技发展
三大核心问题:信息存储、信息处理、信息传输
| 核心问题 |
特点 |
| 信息存储 |
存储设备容量不断增加 数据量对存储设备的容量提出了更高要求 存储设备容量增大加快了数据量的产生 |
| 信息传输 |
网络带宽不断增加 |
| 信息处理 |
CPU处理性能大幅提升 摩尔定律:每18个月性能提升一倍,价格下降一半 |
1.3 数据产生方式的变革
数据产生经历了三个阶段:运营式系统阶段、用户原创内容阶段、感知式系统阶段
| 数据产生阶段 |
实例 |
特点 |
| 运营式系统阶段 |
医院医疗系统,银行交易系统... |
数据产生是被动的,每发生一笔业务时产生相关的记录并记入数据库 |
| 用户原创内容阶段 |
“web2.0时代”,以微博都应采用的自服务模式为主 |
数据传播不需要借助磁盘等物理介质,强调自服务 |
| 感知式系统阶段 |
物联网中包含的温度传感器等传感器 |
物联网设备自动在短时间内产生密集、大量数据 |
1.4 大数据的影响
科学研究:实验科学->理论科学->计算科学【先提出可能理论后通过数据验证】->数据密集型科学【通过大量数据直接得出未知理论】
思维方式的三大转变:全样而非抽样、效率而非精确、相关而非因果
社会发展:大数据决策,大数据与各产业融合、大数据推动新技术和新应用产生
二、 大数据的概念
2.1 大数据的特征
大数据的4个“V”:数据量大(Volume)、数据类型繁多(Variety)、处理速度快(Velocity)、价值密度低(Value)
2.2 大数据关键技术
大数据技术:指伴随大数据的采集、存储、分析和结果呈现的相关技术,是使用非传统的工具对大量结构化、半结构化、非结构化的数据进行处理,从而获得分析和预测结果的一系列数据处理和分析技术
两大核心技术:分布式存储和分布式处理
主要学习内容:分布式文件系统HDFS、分布式数据库BigTable、分布式并行处理技术MapReduce
| 大数据技术 |
功能 |
| 数据采集与预处理 |
利用数据仓库的ETL工具将分布在异构数据源中的数据【关系数据、平面数据文件...】,抽取到临时中间层进行清洗、转换、继承、最后加载到数据仓库或数据集市中,成为联机分析处理、数据挖掘的基础; 也可以利用日志采集工具,把实时采集的数据作为流输入计算机,进行实时处理分析 |
| 数据存储和管理 |
利用分布式文件系统、数据仓库、关系型数据库、NoSQL数据库等,实现对结构化、半结构化、非结构化海量数据的存储和管理 |
| 数据处理和分析 |
利用分布式并行编程模型和计算框架,结合机器学习和数据挖掘算法,实现对海量数据的处理和分析; 对分析结果进行可视化呈现,帮助人们更好地理解数据、分析数据 |
| 数据安全和隐私保护 |
从大数据中挖掘商业和学术价值的同时,构建数据安全体系和隐私数据保护体系,有效保护数据安全和个人隐私 |
P.s 数据库!=数据仓库
数据库:数据库是面向交易的处理系统(业务系统),它是针对具体业务在数据库联机的日常操作,通常对记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。传统的数据库系统作为数据管理的主要手段,主要用于操作型处理,也被称为联机事务处理 OLTP(On-Line Transaction Processing)。
数据仓库::数据仓库一般针对某些主题的历史数据进行分析,支持管理决策,又被称为联机分析处理 OLAP(On-Line Analytical Processing)。
ETL:把各个独立系统的数据抽取出来,经过一定的转换和过滤,存放到一个集中的地方,成为数据仓库。这个抽取,转换,加载的过程叫ETL(Extract, Transform,Load),目的是将企业中分散、零乱、标准不统一的数据整合到一起。
2.3 大数据计算模式、
常见的大数据处理技术MapReduce代表了 针对大规模数据的批量处理技术,除此之外,还有批处理计算、流计算、图计算、查询分析计算等多种大数据计算模式
| 大数据计算模式 |
解决问题 |
代表产品 |
| 批处理计算 |
针对大规模数据的批量处理 |
MapReduce、Spark等 |
| 流计算 |
针对流数据的实时计算 |
Flink,DStream等 |
| 图计算 |
针对大规模图结构数据的处理 |
GraphX,Pregel等 |
| 查询分析计算 |
大规模数据的存储管理和查询分析 |
Dremel、Hive等 |
2.4 大数据产业
大数据产业包括IT基础设施层、数据源层、数据管理层、数据分析层、数据平台层和数据应用层,在不同层面,都已经形成了一批引领市场的技术和企业
三、 大数据与云计算、物联网
3.1 云计算
云计算:云计算实现了通过网络提供可伸缩的、廉价的分布式计算能力,用户只需要在具备网络接入条件的地方,就可以随时随地获得所需的各种IT资源
云计算关键技术:云计算关键技术包括虚拟化、分布式存储、分布式计算、多租户等
| 三种服务模式 |
解释 |
三种类型 |
解释 |
| 基础设施即服务 |
出租基础设施如计算机资源和存储空间 |
公有云 |
面向所有注册用户提供服务 |
| 平台即服务 |
出租平台 |
私有云 |
只为特定用户提供服务,如企业自建私有云只为企业内部提供服务 |
| 软件即服务 |
出租软件 |
混合云 |
公有云和私有云搭配使用:出于安全考虑将数据放在私有云中,处于效率考虑利用公有云的计算机资源 |
3.2 物联网
物联网:物联网是物物相连的互联网,是互联网的延伸,它利用局部网络或互联网等通信技术把传感器、控制器、机器、人员和物等通过新的方式联在一起,形成人与物、物与物相联,实现信息化和远程管理控制
物联网关键技术:物联网中的关键技术包括识别和感知技术(二维码、RFID、传感器等)、网络与通信技术、数据挖掘与融合技术等
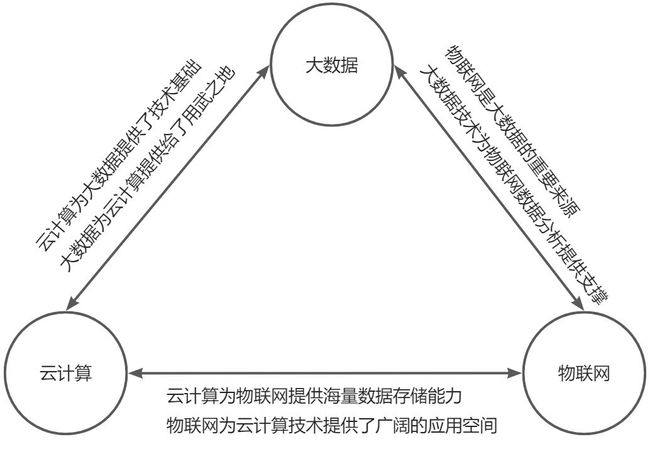
3.3 大数据与云计算、物联网的关系
云计算、大数据和物联网代表了IT领域最新的技术发展趋势,三者既有区别又有联系
第二章 大数据处理架构Hadoop
一、 概述
1.1 Hadoop简介
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供系统底层细节透明的分布式基础架构
Hadoop是基于java开发的,跨平台性强,可以部署在廉价的计算机集群中
Hadoop的核心是Hadoop分布式文件系统【HDFS】和MapReduce。
HDFS是针对谷歌文件系统【GFS】的开源实现,是面向普通硬件环境的分布式文件系统
MapReduce是针对谷歌MapReduce的开源实现,允许用户在不了解系统底层细节情况下开发big你选哪个应用程序
1.2 Hadoop特性
Hadoop是一个能对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的
特性:
高可靠性:采用冗余数据存储方式,有多个副本互相检查。
高效性:作为并行分布式计算平台,Hadoop采用分布式处理和分布式存储两大核心技术,可高效处理PB级数据
高可扩展性:Hadoop可以稳定高效地在廉价的计算机集群上运行,可以扩展到数以千计的计算机节点
高容错性:采用荣誉存储方式,自动保存数据的多个副本,并能自动将失败的任务重新分配
低成本:采用廉价计算机集群,个人计算机中也很容易搭建起Hadoop环境。
运行在Linux操作系统上
支持多种编程语言
1.3 Hadoop版本问题
第一代Hadoop包含三个版本,0.20.x最后演化成1.0.x,变成了稳定版,而0.21.x和0.22.x则增加了NameNode HA等新的重大特性
第二代是一套全新架构,均包含HDFS Federation和YARN两个系统,相比于0.23.x,2.x增加了NameNode HA和Wire-compatibility两个重大特性
Hadoop2.0基于JDK1.7开发(2015.4月停更),社区基于JDK1.8发布Hadoop3.0
1.4 Hadoop生态
Hadoop项目已非常成熟和完善,包括Zookeeper、HDFS、MapReduce、HBase、Hive、Pig等子项目,其中,HDFS和MapReduce是Hadoop的两大核心组件。
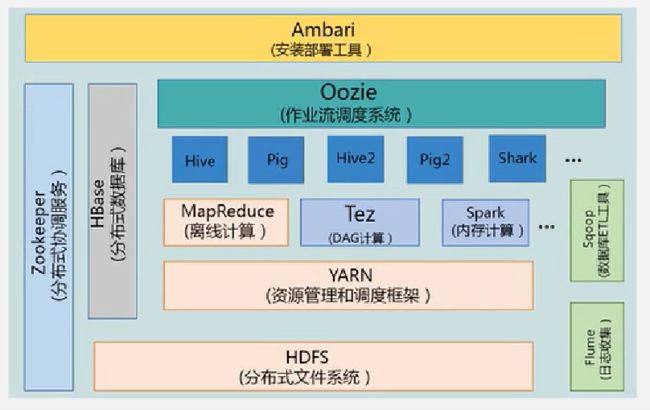
| 组件 |
功能 |
| HDFS |
分布式文件系统 |
| MapReduce |
分布式并行编程模型 |
| YARN |
资源管理和调度器 |
| Tez |
运行在YARN之上的下一代Hadoop查询处理框架 |
| Hive |
Hadoop上的数据仓库 |
| HBase |
Hadoop上的非关系型的分布式数据库 |
| Pig |
一个基于Hadoop的大规模数据分析平台,提供类似SQL的查询语言Pig Latin |
| Sqoop |
用于在Hadoop与传统数据库之间进行数据传递 |
| Oozie |
Hadoop上的工作流管理系统 |
| Zookeeper |
提供分布式协调一致性服务 |
| Storm |
流计算框架 |
| Flume |
一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统 |
| Ambari |
Hadoop快速部署工具,支持Apache Hadoop集群的供应、管理和监控 |
| Kafka |
一种高吞吐量的分布式发布订阅消息系统,可以处理消费者规模的网站中的所有动作流数据 |
| Spark |
类似于Hadoop MapReduce的通用并行框架 |