FaceForensics++读书笔记
- 1.FaceForensics++ is a dataset of facial forgeries that enables researchers to train deep-learning-based approaches in a supervised fashion.
- 2.Four state-of-the-art methods, namely, Face2Face, FaceSwap, DeepFakes, and NeuralTextures.
Abstruct
1.This paper
This paper examines the realism of state-of- the-art image manipulations, and how difficult it is to detect them, either automatically or by humans.
2.Automated benchmark
3.Use of additional domain specific knowledge
1.Intriduction
- Current facial manipulation methods can be separated into two categories: facial expression manipulation and facial identity manipulation
- Facial expression manipulation means changing expressions. One of the most prominent facial expression manipulation techniques is the method of Thies et al. [56] called Face2Face.It enables the transfer of facial expressions of one person to another person in real time using only commodity hardware. Follow-up work such as “Synthesizing Obama”

- Identity manipulation:replace the face of a person with the face of another person, Which known as face swapping. DeepFakes also performs face swapping, but via deep learning.

4. Training a neural network in a supervised fashion, We tackle the detection problem.
5. Our paper makes the following contributions:
- An automated benchmark
- A novel large-scale dataset
- An extensive evaluation
- A state-of-the-art forgery detection method
2.Related Work
We cover the most important related papers in the following paragraphs
1).Face Manipulation Methods:
- A comprehensive state-of-the-art report has been published by Zollho ̈fer et al. [64]
- In particular, Bregler et al. [12] presented an image-based approach called Video Rewrite to automatically create a new video of a person with generated mouth movements.
- With Video Face Replacement [19], Dale et al. presented one of the first automatic face swap methods. Using single-camera videos, they reconstruct a 3D model of both faces and exploit the corresponding 3D geometry to warp the source face to the target face.
- Gar- rido et al. [28] presented a similar system that replaces the face of an actor while preserving the original expressions.
- VDub [29] uses high-quality 3D face capturing techniques to photo-realistically alter the face of an actor to match the mouth movements of a dubber.
- Thies et al. [55] demonstrated the first real-time expression transfer for facial reenactment.
- Based on a consumer level RGB-D camera, they reconstruct and track a 3D model of the source and the target actor. The tracked deformations of the source face are applied to the target face model. As a final step, they blend the altered face on top of the original target video.
- Face2Face, proposed by Thies et al. [56], is an advanced real-time facial reenactment system, capable of altering facial movements in commodity video streams, e.g.videos from the internet. They combine 3D model reconstruction and image-based rendering techniques to generate their out put.
- The same principle can be also applied in Virtual Reality in combination with eye-tracking and reenactment [57] or be extended to the full body [58]
- Kim et al. [38] learn an image-to-image translation network to convert computer graphic renderings of faces to real images.
- Instead of a pure image-to-image translation network, NeuralTextures [54] optimizes a neural texture in conjunction with a rendering network to compute the reenactment result. In comparison to Deep Video Portraits [38], it shows sharper results, especially, in the mouth region.
- Suwajanakorn et al. [52] learned the mapping between audio and lip motions, while their compositing approach builds on similar techniques to Face2Face [56].
- Averbuch-Elor et al. [7] present a reenactment method, Bringing Portraits to Life, which employs 2D warps to deform the image to match the expressions of a source actor. They also compare to the Face2Face technique and achieve similar quality.
- ************* face image synthesis approaches using deep learning techniques *************
- Lu et al. [45] provide an overview.
- Generative adversarial networks (GANs) are used to apply Face Aging [6], to generate new viewpoints [33], or to alter face attributes like skin color [44].
- Deep Feature Interpolation [59] shows impres- sive results on altering face attributes like age, mustache, smiling etc.
- Similar results of attribute interpolations are achieved by Fader Networks [41]. Most of these deep learn- ing based image synthesis techniques suffer from low image resolutions.
- Recently, Karras et al. [36] have improved the image quality using progressive growing of GANs, producing high-quality synthesis of faces.
2).Multimedia Forensics
- Early methods are driven by hand- crafted features that capture expected statistical or physics- based artifacts that occur during image formation.
- More recent literature concentrates on CNN-based solutions, through both supervised and unsupervised learning
- For videos, the main body of work focuses on detecting manipulations that can be created with relatively low effort
- To this end, our dataset is designed to cover such realistic sce- narios
3).Forensic Analysis Datasets
- In contrast, we construct a database containing more than 1.8 million images from 4000 fake videos – an order of magnitude more than existing datasets.
3.Large-scale Facial Forgery Database
- To this end, we leverage four automated state-of-the-art face manipulation methods, which are applied to 1,000 pristine videos downloaded from the Internet.
- However, early experiments with all manipulation methods showed that the target face had to be nearly front-facing to prevent the manipulation methods from failing or producing strong artifacts.
- For our dataset, we chose two computer graphics-based approaches (Face2Face and FaceSwap) and two learning- based approaches (DeepFakes and NeuralTextures).
FaceSwap
- FaceSwap is a graphics-based approach to transfer the face region from a source video to a target video.
- Based on sparse detected facial landmarks the face region is extracted. Using these landmarks, the method fits a 3D template model using blendshapes.
- This model is back- projected to the target image by minimizing the difference between the projected shape and the localized landmarks using the textures of the input image. Finally, the rendered model is blended with the image and color correction is applied.
- We perform these steps for all pairs of source and target frames until one video ends. The implementation is computationally lightweight and can be efficiently run on the CPU.
DeepFake
- Becoming a synonym for face replacement based on deep learning.
- A face in a target sequence is replaced by a face that has been observed in a source video or image collection.
The method is based on two autoencoders with a shared encoder that are trained to reconstruct training images of the source and the target face, respectively.
A face detector is used to crop and to align the images. To create a fake image, the trained encoder and decoder of the source face are applied to the target face. The autoencoder output is then blended with the rest of the image using Poisson image editing [47].
Face2Face
- Transfers the expressions of a source video to a target video while maintaining the identity of the target person
- The original implementation is based on two video input streams, with manual keyframe selection. These frames are used to generate a dense reconstruction of the face which can be used to re-synthesize the face under different illumination and expressions.
- To process our video database, we adapt the Face2Face approach to fully-automatically create reenactment manipulations. We process each video in a preprocessing pass; here, we use the first frames in order to obtain a temporary face identity (i.e., a 3D model), and track the expressions over the remaining frames. In order to select the keyframes required by the approach, we automat- ically select the frames with the left- and right-most angle of the face. Based on this identity reconstruction, we track the whole video to compute per frame the expression, rigid pose, and lighting parameters as done in the original implementation of Face2Face.
- We generate the reenactment video outputs by transferring the source expression parameters of each frame (i.e., 76 Blendshape coefficients) to the target video.
NeuralTextures
- It uses the original video data to learn a neural texture of the target person, including a rendering network.This is trained with a photometric reconstruction loss in combination with an adversarial loss.
- In our implementation, we apply a patch-based GAN-loss as used in Pix2Pix [35].
- The NeuralTextures approach relies on tracked geometry that is used during train and test times. We use the tracking module of Face2Face to generate these information.
Postprocessing - Video Quality
we generate output videos with different quality levels.
4.Forgery Detection
For all experiments, we split the dataset into a fixed training, validation, and test set, consisting of 720, 140, and 140 videos respectively. All evaluations are reported using videos from the test set.
4.1 Forgery Detection of Human Observers
we conducted a user study with 204 par- ticipants consisting mostly of computer science university students

Face2Face and NeuralTextures were particularly difficult to detect by human observers.as they do not introduce a strong semantic change, introducing only subtle visual artifacts in contrast to the face replacement methods.
NeuralTextures texture seems particularly difficult to detect.
4.2 Automatic Forgery Detection Methods

In addition, we show that the classification based on XceptionNet [13] outperforms all other variants in detecting fakes.
4.2.1 Detection based on Steganalysis Features:
We provide a 128 × 128 central crop-out of the face as in- put to the method. While the hand-crafted method outper- forms human accuracy on raw images by a large margin, it struggles to cope with compression, which leads to an accu- racy below human performance for low quality videos
4.2.2 Detection based on Learned Features:
We evaluate five network architectures known from the literature to solve the classification task:
(1) Cozzolino et al.–hand-crafted Steganalysis features + a CNN-based net- work.
(2) Bayar and Stamm:[9] a constrained convolutional layer followed by two convolutional, two max-pooling and three fully-connected layers. The constrained convolutional layer is specifically designed to suppress the high-level content of the image.
(3) Rahmouni et al. [49] adopt different CNN architectures with a global pooling layer that computes four statis- tics (mean, variance, maximum and minimum). We con- sider the Stats-2L network that had the best performance.
(4) MesoInception-4 [4] is a CNN-based network inspired by InceptionNet [53] to detect face tampering in videos.
(5) XceptionNet [13] :is a traditional CNN trained on ImageNet based on separable convolutions with residual connections.We transfer it to our task by replacing the final fully connected layer with two outputs.
Comparison of our Forgery Detection Variants:
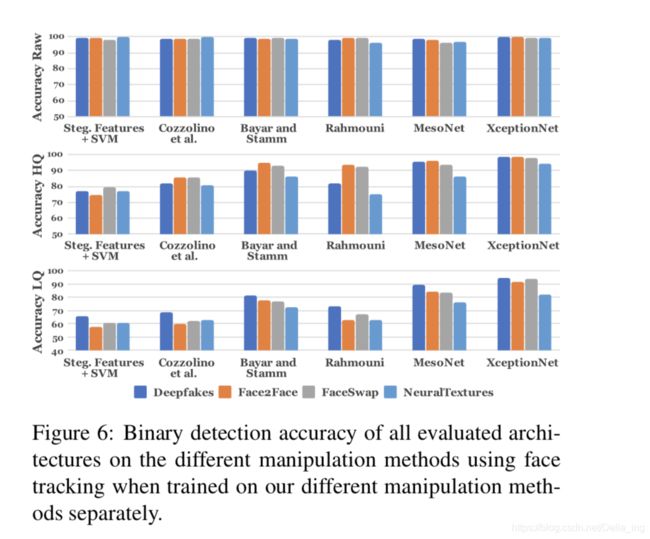
Fig. 6 shows the results of a binary forgery detection task using all network architectures evaluated separately on all four manipulation methods and at different video quality levels. All approaches achieve very high performance on raw input data. Performance drops for compressed videos, particu- larly for hand-crafted features and for shallow CNN archi- tectures [9, 16]. The neural networks are better at handling these situations, with XceptionNet able to achieve com- pelling results on weak compression while still maintaining reasonable performance on low quality images, as it benefits from its pre-training on ImageNet as well as larger network capacity.
Due to the lack of domain-specific information, the XceptionNet classifier has a significantly lower accuracy in this scenario.
To summarize, domain-specific information in combination with a XceptionNet classifier shows the best performance in each test. We use this network to further understand the influence of the training corpus size and its ability to distinguish between the different manipulation methods.
Forgery Detection of GAN-based methods
The experiments show that all detection approaches achieve a lower accuracy on the GAN-based NeuralTextures approach.
Evaluation of the Training Corpus Size:
we trained the XceptionNet classifier with different training corpus sizes on all three video quality level separately.
5. Benchmark
We collected 1000 additional videos and manipulated a subset of those in a similar fashion as in Section 3 for each of our four manipulation methods.
The major changes being the randomized quality level as well as possible tracking errors during test. Since our proposed method relies on face detections, we predict fake as default in case of a tracking failure.
6. Discussion & Conclusion
It is particularly encouraging that also the challenging case of low-quality video can be tackled by learning-based approaches, where humans and hand-crafted features exhibit difficulties. To train detectors using domain-specific knowledge, we introduce a novel dataset of videos of manipulated faces that exceeds all existing publicly available forensic datasets by an order of magnitude.
As new manipulation meth- ods appear by the day, methods must be developed that are able to detect fakes with little to no training data.
Our database is already used for this forensic transfer learning task, where knowledge of one source manipulation domain is transferred to another target domain, as shown by Coz- zolino et al [17].