【A Unified Model for Multi-class Anomaly Detection, NeurIPS 2022】
paper link: https://arxiv.org/abs/2206.03687
code: https://github.com/zhiyuanyou/UniAD
Abstract
以前的无监督异常检测方法对不同的物体需要训练不同的模型进行异常检测。针对这个问题,我们提出的UniAD为多类别异常检测提供了一个统一的架构。在这种具有挑战性的场景下,流行的重建网络会陷入”同等捷径“困境,所谓”同等捷径“即是无论是正常的还是异常的样本都会被很好地重建恢复,因此也就无法发现异常了。为了解决这个困境,我们做了三点改进。首先,我们重新审视了全连接层、卷积层以及注意层,并确认了query embedding(例如,注意层中的)在预防网络学习捷径的关键作用。因此,我们提出了一个逐层的query decoder来帮助对多类别分布进行建模。第二,我们使用一个局部掩码注意力模块来进一步地预防从输入特征到重建后的输出特征的信息泄露。第三,我们提出了一个feature jittering策略来促进模型在输入有噪音的情况下仍能恢复正确的信息。我们在MVTec-AD和CIFAR-10数据集上评估了我们的算法。在用同一个模型对MVTec-AD的15种类别进行预测的场景下,我们无论是在异常检测任务(从88.1%提高到96.5%)还是异常定位任务上(从88.1%提高到96.5%)的结果都远超我们的竞争对象。
1 Introduction
考虑到异常种类的多样性,异常检测常见的做法是对正常样本的分布进行建模,然后通过查找异常点识别出异常样本。因此,如图1a所示,为正常数据学习一个紧凑的边界对此类方法至关重要。为了实现这一目标,现存的方法都是如图1c所示的,分别为不同类别的物体训练不同的模型。然而,这种一个类别一个模型的机制是很消耗内存的,尤其是当类别的数量增加时,并且也不适用于正常样本表现出大的类内多样性的情况(一个物体有多种型号)。
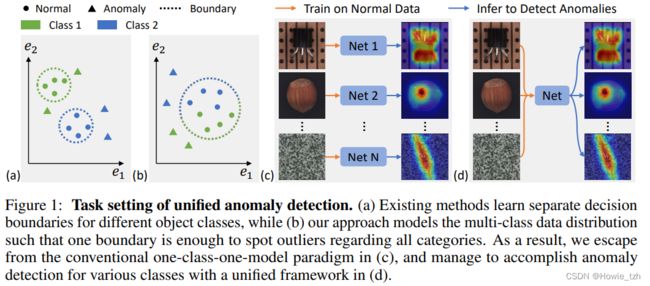
本工作致力于面向一个更实际的任务,用统一的框架从不同的物体类别中检测异常。任务设置如图1d所示,其中训练数据包含各种类别物体的正常样本,习得的模型被要求在没有任何微调的情况下对所有类别的物体进行异常检测。值得注意的是,类别信息(比如,类别标签)无论是在训练阶段还是预测阶段均不可见,这极大地降低了数据制备的难度。尽管如此,解决这样的任务是相当困难的。还记得无监督异常检测的基本原理是对正常数据的分布进行建模,并找到一个如图1a所示的紧凑的决策边界吗?当涉及到多类别异常检测的情形时,我们期望模型可以如图1b所示,同时捕获所有类别的分布以便于所有类别共享同一个决策边界。但是,当我们关注某一个类别时,比如图1b所示的绿色样本,所有来自其它类别的样本都应该被视为异常,无论他们本身是正常的(蓝色圆圈)亦或是异常的(蓝色三角)样本。从这个角度出发,如何准确地对多类别分布进行建模变得至关重要。
一种广泛使用的对正常样本分布进行建模的方法是图像重构,它假定训练好的模型总是生成正常的样本,即便模型的输入中包含异常。这样一来,对于异常样本而言,他们的重构误差会比正常样本大很多,从而将其与正常样本区分开来。然而,我们发现当面临本工作研究的富有挑战性的场景时,流行的重建网络并不有效。他们通常会陷入”同等捷径“的困境,其表现为忽略输入的内容,直接返回其副本。其结果是即便是异常样本也得到了良好的重建,因此也就难以将他们检测出来了。除此之外,对于多类别的场景,正常样本的分布更为复杂,”同等捷径“问题也会被进一步的放大。直觉上,学习一个可以重建各种物体的统一模型,需要模型非常努力地去学习联合分布。从这个角度出发,学习一个”同等捷径“似乎是一个简单得多的方案。
为了解决这个问题,我们精心设计了一个特征重建框架以预防模型学习到捷径。首先,我们重新审视了神经网络中全连接层、卷积层以及注意层的公式,发现了全连接层和卷积层都面临着学习平凡解的风险。当在多类别的场景下,正常样本的分布更为复杂,这一风险会被进一步放大。对比而言,注意层得益于可学习的query embedding从而避免了这一风险。因此,我们提出了一个逐层的query decoder来增加query embedding的使用。第二,我们发现全注意(即,每个特征点都与其它的特征点相关)也会导致捷径问题, 因为它为直接将输入拷贝到输出提供了机会。为了避免信息泄露,我们使用了一种局部掩码注意力模块,它的特征点既不与自身相关,也不与邻点相关。第三,受Bengio等人的启发,我们提出了一个feature jittering策略来促进模型在输入有噪音的情况下仍能恢复正确的信息。所有这些设计都帮助了模型逃脱如图2b所示的”同等捷径“困境。
2 Related work
异常检测: 1)经典方法扩展了经典机器学习方法的单类分类,比如单类支持向量机(OC-SVM)和支持向量数据描述方法(SVDD)。补丁级嵌入,几何变换和弹性重量固结被纳入改进。2)Pseudo-anomaly 将异常检测转化为监督学习,包括分类、图像去噪和超球分割。然而,这些方法部分依赖于代表异常与未知的真实异常的匹配程度。3)Modeling then comparison假设预训练的网络能够提取判别特征进行异常检测。PaDiM和MDND提取预先训练的特征来模拟正常分布,然后利用距离度量来测量异常。然而,这些方法需要记忆和建模所有正常的特征,因此计算成本很高。4)Knowledge distillation认为在正常样本上由teacher蒸馏得到的student只能提取到正常特征。最近的工作集中在模型集成,特征金字塔和reverse distillation上。
基于重建的异常检测: 这些方法依赖于在正常样本上训练的重建模型只在正常区域成功,而在异常区域失败的假设。早期的尝试包括自动编码器(AE),变分自动编码器(VAE)和生成对抗网络(GAN)。但是,这些方法都面临着模型可能会学习到使异常也得到良好恢复的技巧。因此,研究人员采取了不同的策略来解决这一问题,如添加教学信息(即结构或语义)、记忆机制、迭代机制、图像掩蔽策略和伪异常。最近,DRAEM[53]算法首先将伪异常扰动的正常图像恢复表示,然后利用判别网对异常进行判别,取得了良好的性能。然而,DRAEM[53]在统一的情况下不再有效。此外,还有一个重要的方面还没有得到很好的研究,即什么样的结构是最好的重建模型?在本文中,我们首先比较和分析了三种流行的体系结构,包括MLP、CNN和transformer。在此基础上,进一步设计了三个改进方案,组成了我们的UniAD。
异常检测中的Transformer: 具有注意机制的Transformer[43]在自然语言处理中首次被提出,现已成功应用于计算机视觉[7,16]。有些尝试利用Transformer进行异常检测。InTra[32]采用Transformer,通过逐个恢复所有被遮罩的补丁来恢复图像。VT-ADL[29]和AnoVit[51]均采用Transformer编码器进行图像重建。但是,这些方法直接利用了朴素Transformer,并没有弄清楚为什么Transformer带来改进。与此相反,我们验证了查询嵌入在防止捷径方式上的有效性,并据此设计了一种逐层的查询解码器。同时,为了避免全注意的信息泄露,我们采用了邻居屏蔽注意模块。
3 Method
3.1 Revisiting feature reconstruction for anomaly detection
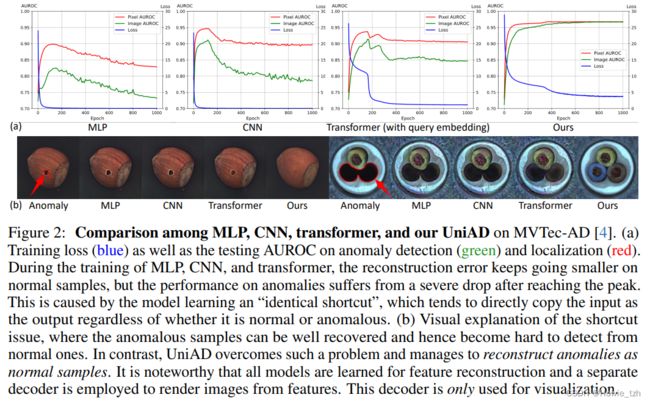
在图2中,按照特征重构范式[40],我们构建了MLP、CNN和Transformer(带有查询嵌入)来重构预训练的主干网络提取的特征。重构误差代表了异常的可能性。这三个网络的体系结构在附录中给出。指标每10个训练周期评估一次。注意,定期评估是不切实际的,因为在训练中无法获得异常。如图2a所示,经过一段时间的训练,三个网络的性能下降严重,损失极小。我们将其归结为“相同捷径”的问题,正常和异常区域都可以很好地恢复,从而无法发现异常。图2b的可视化结果验证了这一推测(更多结果见附录)。然而,与MLP和CNN相比,Transformer的性能下降要小得多,这表明只有轻微的捷径问题。这促使我们进行如下分析。
我们将正常图像的特征记为 x + ∈ R K × C x^+ \in \mathbb{R}^{K\times C} x+∈RK×C,其中 K K K是特征数量, C C C是通道维度。批量维度为了简介起见省略了。类似地,异常图像的特征记为 x − ∈ R K × C x^- \in \mathbb{R}^{K\times C} x−∈RK×C。重建损失选择MSE损失。
我们用一个在 x + x^+ x+上训练的简单的单层重建网络做 x − x^- x−的异常区域检测测试,以提供一个粗略的分析。
多层感知机中的全连接层: 将层中的权重和偏置分别记为 w ∈ R C × C w \in \mathbb{R}^{C\times C} w∈RC×C, b ∈ R C b\in \mathbb{R}^{C} b∈RC,该层可以表示为:
y = x + w + b ∈ R K × C y=x^+w+b \in \mathbb{R}^{K\times C} y=x+w+b∈RK×C
当MSE损失将 y y y推向 x + x^+ x+时,模型可能会采取捷径将 w → I w\rightarrow I w→I, b → 0 b\rightarrow 0 b→0。最终导致模型对 x − x^- x−也能良好重建,使异常检测失败。
卷积神经网络中的卷积层: 1 × 1 1\times1 1×1的卷积层等效为全连接层。 n × n ( n > 1 ) n\times n\space(n>1) n×n (n>1)的卷积核有更多的参数和更大的容量,并能完成 1 × 1 1\times1 1×1可以完成的所有事情。因此,该层也有可能学到捷径。
Transformer with query embedding: 在该模型中,有着一个可学习查询嵌入的注意力层, q ∈ R K × C q \in \mathbb{R}^{K\times C} q∈RK×C。当使用该层作为重建网络时,它表示为:
y = s o f t m a x ( q ( x + ) T / C ) x + ∈ R K × C y=softmax(q(x^+)^T/ \sqrt{C})x^+\in \mathbb{R}^{K\times C} y=softmax(q(x+)T/C)x+∈RK×C
为了将 y y y推向 x + x^+ x+,注意力图, s o f t m a x ( q ( x + ) T / C ) softmax(q(x^+)^T/ \sqrt{C}) softmax(q(x+)T/C)应该趋于单位矩阵 I I I,因此 q q q一定与 x + x^+ x+高度相关。考虑到训练模型中的 q q q与正常样本相关,模型不能良好地重建 x − x^- x−。第4.6节的烧蚀研究表明,如果没有查询嵌入,Transformer的性能在像素ROAUC和图像ROAUC上分别大幅下降13.4%和18.1%。因此,查询嵌入对正常分布的建模具有重要意义。
但是Transformer仍然存在捷径问题,这启发了我们的三个改进。1)根据查询嵌入可以防止异常重构的特点,设计了一种逐层查询译码器(Layerwise query Decoder, LQD),将查询嵌入添加到译码器的每一层,而不是只在普通转换器的第一层。2)我们怀疑,full attention增加了模型走捷径的可能性。因为一个token可以看到它自己和它的邻居区域,所以很容易通过简单的复制来重构它。因此,我们在计算注意力图时屏蔽了相邻的tokens,称之为邻域屏蔽注意(NMA)。3)我们采用特征抖动(FJ)策略对输入特征进行干扰,使模型从去噪中学习正常分布。得益于这些设计,我们的UniAD取得了令人满意的性能,如图2所示。
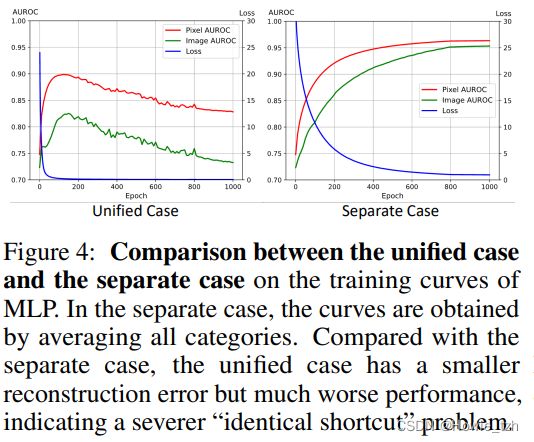
Relation between the “identical shortcut” problem and the unified case. 我们比较了MLP的统一方案和分别方案的训练曲线。如图4所示,准确率(红色为定位,绿色为检测)随着损失(蓝色)的减小持续增加。这揭示了“同等捷径”问题与统一方案的关系,即统一方案更具挑战性,并且会放大“同等捷径”问题。因此,既然我们的方法是专门为了解决“同等捷径”问题设计的,所以我们的方法在统一方案时非常有效。
3.2 Improving feature reconstruction for unified anomaly detection
Overview 如图3所示,我们的UniAD由一个局部遮掩编码器(NME)和一个逐层查询解码器(LQD)组成。首先,由固定的预训练主干网络提取的特征tokens进一步由NME集成后得到编码嵌入。然后,在LQD的每一层。一个可学习的查询嵌入连续地与编码嵌入及前一层的输出(对于第一层与它自己融合)进行融合。特征融合由局部遮掩注意力(NMA)完成。LQD的最终输出被视为重建后的特征。我们还提出了一个特征抖动策略(FJ)来增加对输入特征的扰动,使模型可以从有干扰的任务中学习正常样本的分布。最终,通过重建误差得到异常的定位和检测结果。
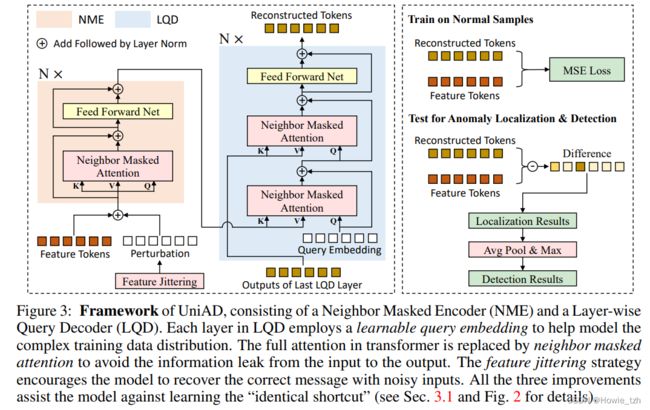
Neighbor masked attention. 我们认为普通Transformer的全注意力会导致"identical shortcut"问题。在全注意力中,token可以看到它自己,因此很容易通过直接复制的方式实现重建。此外,考虑到特征tokens是由CNN主干网络提取的,相邻的tokens肯定有很多相似性。因此,我们提出计算注意图时对相邻tokens进行遮掩的方法,我们称之为邻域遮掩注意力(NMA)。其中,邻域是在2D空间定义的,如图5所示。

Neighbor masked encoder. 编码器和普通transformer的标准架构一致,每一层都由一个注意力模块和一个前向传播网络(FFN)构成。不同点是,我们用NMA替代了全注意力,以防止信息泄露。
Layer-wise query encoder. 正如3.1节分析的那样,查询嵌入可以有效地阻止对异常也进行重建。然而,在普通transformer中只有一个查询嵌入,因此,我们设计了一个逐层查询解码器来强化对查询嵌入的使用,如图3所示。具体地,在LQD的每一层,一个可学习的查询嵌入首先和编码嵌入进行融合,再和前一层的输出(对于第一层与它自己进行整合)进行整合。特征融合由NMA进行。遵循普通transformer的架构,融合的特征进一步由两层前向传播网络处理,并用残差连接加速网络训练。LQD的最终输出被视为重建后的特征。
Feature jittering. 受降噪自动编码器(DAE)的启发,我们对特征tokens加入扰动,指导模型通过降噪任务学习正常样本的知识。具体地,对一个特征token, f t o k ∈ R C f_{tok} \in \mathbb{R}^C ftok∈RC,我们从高斯分布中采样得到一个扰动 D D D,
D ∼ N ( μ = 0 , σ 2 = ( α ∣ ∣ f t o k ∣ ∣ 2 C ) 2 ) ,( 3 ) D\sim N(\mu=0,\sigma^2=(\alpha\frac{||f_{tok}||_2}{C})^2),(3) D∼N(μ=0,σ2=(αC∣∣ftok∣∣2)2),(3)
其中 α \alpha α是抖动尺度用以控制噪声的大小。此外,采样的噪声是以抖动概率 p p p加到 f t o k f_{tok} ftok上的。
3.3 实施细节
特征提取。 我们使用在ImageNet上预训练的EfficientNet-b4作为特征提取器。选择阶段1~阶段4的特征。这里的阶段指的是特征图尺寸一致的模块组合。然后,将这些特征缩放到同一尺寸,并在通道维度上拼接起来得到特征图 f o r g ∈ R C o r g × H × W f_{org}\in\mathbb{R}^{C_{org}\times H\times W} forg∈RCorg×H×W。
特征重建。 特征图 f o r g f_{org} forg首先被转化为 H × W H\times W H×W的特征tokens,然后通过线性映射将通道数 C o r g C_{org} Corg降为 C C C。接着这些tokens进一步由NME和LQD处理。可学习的位置嵌入被引入注意力模块来告知空间信息。之后,使用另一个线性映射将通道数由 C C C恢复为 C o r g C_{org} Corg。在缩放后得到最终的重建后的特征图 f r e c ∈ R C o r g × H × W f_{rec}\in\mathbb{R}^{C_{org}\times H\times W} frec∈RCorg×H×W。
目标函数。 我们使用MSE损失训练模型:
L = 1 H × W ∣ ∣ f o r g − f r e c ∣ ∣ 2 2 . ( 4 ) \cal{L}=\frac{1}{H\times W}||f_{org}-f_{rec}||^2_2.(4) L=H×W1∣∣forg−frec∣∣22.(4)
异常定位推理。 异常定位的结果是一张异常得分图,图上像素值表示异常得分。具体地,异常得分图 s s s由重建误差的 L 2 L2 L2范数得到:
s = ∣ ∣ f o r g − f r e c ∣ ∣ 2 ∈ R H × W s=||f_{org}-f_{rec}||_2\in \mathbb{R}^{H\times W} s=∣∣forg−frec∣∣2∈RH×W
之后通过双线性插值将 s s s缩放回原图分辨率得到定位结果。
异常检测推理。 异常检测的目的是判断图像中是否含有异常区域。我们使用 s s s经过平均池化后的最大值作为整图异常的得分。
4 实验
4.1 数据集和指标
MVTec-AD 是一个综合性的,多目标的,多缺陷的工业异常检测数据集,包含15个类别。测试集中的每一个异常样本,真值标签包含图像标签和异常分割两部分。在现存的文献中,各类目标和缺陷的检测是分开研究的。在本文中我们引入了一个统一的框架,同时解决各类目标的异常检测。
CIFAR-10 是有10种类别的图像分类数据集。现存的模型主要以一对多的方式评估CIFAR-10,也就是将一个类别视为正常,其它类别视为异常。Semantic AD提出一种多对一的方式,将一种类别视为异常,其它类别视为正常。与两者不同,我们提出一种统一的框架(多对多的方式),详细描述见4.4节。
指标。 遵循前人的工作,使用AUROC作为异常检测的评估指标。
4.2 MVTec-AD上的异常检测
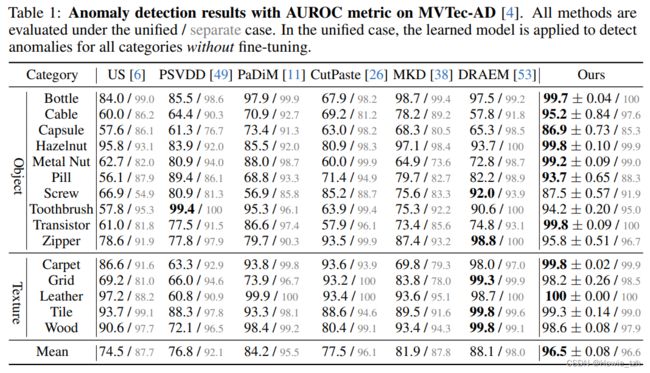
实验设置。 异常检测致力于检测图像是否含有异常区域。异常检测的表现在MVTec-AD数据集上进行评估。图像的尺寸设定为224x224,缩放后的特征图的尺寸设定为14x14。EfficientNet-b4阶段1到阶段4的特征图通过缩放和拼接后得到一个272通道的特征图。降维后的通道数设为256.使用权重衰减维1e-4的AdamW优化器。我们的模型在8块GPUs上以64的batch size训练了1000个epochs。初始学习率为1e-4,800个epochs后将为1e-5.邻域尺寸、抖动尺度和抖动概率分别设为7x7,20和1.评估随机5次。无论是单类还是统一架构,重建模型都是从头开始训练的。
基线。 我们的方法与以下基线进行对比:US,PSVDD,PaDiM,CutPaste,MKD和DRAEM。在单类模式下,基准的指标来自各自的论文。在统一模式下,US,PSVDD,PaDiM,CutPaste,MKD和DRAEM以其公开的实施运行。
MVTec-AD上异常检测的定量结果如表1所示。尽管所有基线都在单类模式下取得了优秀的表现,在统一模式下他们的表现却急剧下降。之前的SOTA,DRAEM一种通过伪异常训练的重建类方法,在统一模式下,表现急剧下降了10%。另一种强力的基线,CutPaste,一种伪异常方法,表现下降了高达18.6%。然而,我们的UniAD从单类模式(96.6%)到统一模式(96.5%)几乎没有表现下降。并且,我们以8.4%的优势击败了最佳的竞争模型DREAM,表明了我们方法的优越性。
4.3 MVTec-AD上的异常定位
实验设置与基线。 异常定位致力于在异常图像上对异常区域进行定位。选择MVTec-AD作为基准数据集。实验设置与4.2节一致。除了4.2节的竞争方法,另外引入了FCDD方法,在单类模式下,它的指标使用论文中的报导。在统一模式下使用其公开实施运行FCDD。
MVTec-AD上的异常定位定量结果如表2所示。与4.2节类似,从单类模式切换到统一模式时,所有的竞争方法的表现都出现了急剧下降的现象。

MVTec-AD上的异常定位定性结果如图6所示。

4.4 CIFAR-10上的异常检测
实验设置。 为了进一步验证我们的UniAD的有效性,我们扩展CIFAR-10到统一模式下,将CIFAR-10数据集分成4个组,每组5个类别为正常,剩下的5个类别为异常,各组的正常样本类别如下:{01234}、{56789}、{02468}、{13579}。模型的设置见附录。
基准。 US、FCDD、FCDD+OE、PANDA和MKD作为竞争方法,使用各自公开的实施运行。
CIFAR-10上异常检测的定量结果如表3所示。

4.5 与基于transformer的竞争者的对比
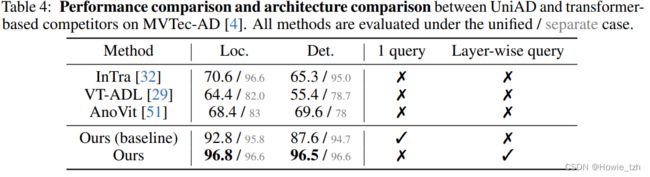
正如第2节所述的那样,一些人同样尝试使用transformer进行异常检测。这里,我们在MVTec-AD数据集上对比我们的UniAD和其它基于transformer模型的表现。回想我们使用tansformer作为重建模型的原因是它能有效避免"identical shortcut"问题。具体地,我们发现可学习查询嵌入对于避免shortcut问题至关重要,而很少在现存的基于transformer的方法中加以讨论。如表4所示,在仅仅引入一个查询嵌入的情况下我们的基线就已经在统一模式下远超其它方法了。我们提出的三个组件进一步提高了我们强有力的基线。
4.6 消融研究
为了验证所提模块的有效性,并选择合适的超参数,我们对MVTec-AD数据集在统一模式下进行了大量的消融研究。
逐层查询。 表5a证明了我们关于查询嵌入至关重要的假设。1)没有查询嵌入意味着编码嵌入直接输入解码器,其表现是最差的。2)在解码器的第一层加入查询嵌入将异常检测和异常定位任务的表现分别提高了13.4%和18.1%。3)在逐层查询的设置下,异常检测和异常定位的AUROC进一步提高了3.7%和7.4%。
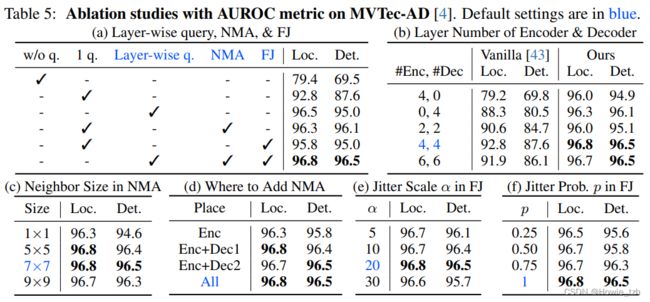
层数。 我们对层数的影响进行实验,如表5b所示。1)无论哪种组合,我们的模型都远好于普通transformer模型,显示了我们设计的有效性。2)最佳为4层编码器,4层解码器,更多的层数没有带来更好表现的原因可能是,更多层的网络难以训练。
邻域遮掩注意力。 1)NMA的有效性在表5a中得证。在只有一个查询嵌入的模式下,加入NMA带来3.5%的定位和8.5%的检测收益。2)NMA的邻域尺寸的选择如表5c所示,1x1最差,因为它无法阻止信息泄露,邻域的尺寸越大越好,最佳选择是7x7的邻域尺寸。3)在表5d中我们还探索了NMA的位置,只在编码器中加入NMA是不够的,在解码器的第一和第二注意力中也加入NMA可以稳定提高评估指标。这反映了解码器中的全注意力也导致了信息泄露。
特征抖动。 表5a证明了FJ的有效性。以单一查询嵌入为基准,引入FJ可以带来3.0%的定位和7.4%的检测指标提升。2)根据表5e,抖动尺度 α \alpha α选定为20.更高的扰动会过于干扰特征使结果下降。3)在表5f中,研究概率 p p p,当 p = 1 p=1 p=1时取得最佳结果。
5 结论
在本研究中,我们提出了一种统一多类异常检测的UniAD。对于这样一个具有挑战性的任务,我们通过三个改进来帮助模型避免学习“相同的捷径”。首先,我们确认了可学习查询嵌入的有效性,并精心定制了一个逐层查询解码器,以帮助建模多类数据的复杂分布。其次,我们提出了一个邻居屏蔽注意模块,以避免信息从输入到输出的泄漏。第三,我们提出了特征抖动,以帮助模型降低对输入扰动的敏感性。在统一任务设置下,我们的方法在MVTec-AD和CIFAR-10数据集上实现了最先进的性能,显著优于现有的替代方案。
讨论。 在这个作品中,不同种类的对象被处理而不被区分。我们没有使用可能帮助模型更好地拟合多类数据的类别标签。如何将统一模型与分类标签相结合,还有待进一步研究。在实际应用中,普通样本的一致性往往不如MVTec-AD中样本的一致性,往往表现出一定的多样性。我们的UniAD可以处理MVTec-AD中的所有15个类别,因此更适合真实场景。但异常检测可能用于视频监控,可能侵犯个人隐私。