本文整理自知乎专栏深度炼丹,转载请征求原作者同意。
本文的全部代码都在原作者GitHub仓库github
CS20SI是Stanford大学开设的基于Tensorflow的深度学习研究课程。
TensorFlow中的Linear Regression
我们用tensorflow实现一个线性回归的例子。
问题:希望找到城市中纵火案和盗窃案之间的关系,纵火案的数量是\(X\),盗窃案的数量是\(Y\),我们假设存在如下线性关系:\(Y=wX+b\)。
TensorFlow实现
首先定义输入\(X\)和目标\(Y\)的占位符(placeholder)
python X = tf.placeholder(tf.float32, shape=[], name='input') Y = tf.placeholder(tf.float32, shape=[], name='label')
里面shape=[]表示标量(scalar)定义需要更新和学习的参数\(w\)和\(b\)
python w = tf.get_variable('weight', shape=[], initializer=tf.truncated_normal_initializer()) b = tf.get_variable('bias', shape=[], initializer=tf.zeros_initializer())定义模型的输出和误差函数,这里使用均方误差\((Y-Y\_predicted)^2\)
python Y_predicted = w * X + b loss = tf.squre(Y - Y_predicted, name='loss')定义优化函数,这里使用简单梯度下降,这里的学习率可以是常量和tensor
python optimizer = tf.train.GradientDescentOptimizer(learning_rate=1e-3).minimizer(loss)
tensorflow如何判断哪些参数更新,哪些不更新呢?tf.Variable(trainable=False)表示不对该参数更新,默认为True。在
session中做运算python init = tf.global_variables_initializer() with tf.Session() as sess: writer = tf.summary.FileWriter('./linear_log', graph=sess.graph) sess.run(init) for i in range(100): total_loss=0 for x, y in data: _, l = sess.run([optimizer, loss], feed_dict={X:x, Y:y}) total_loss+=1 print('Epoch {0}: {1}'.format(i, total_loss/n_samples))
上述步骤源代码:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import xlrd
DATA_FILE = 'data/fire_theft.xls'
# step 1:加载数据
book = xlrd.open_workbook(DATA_FILE, encoding_override='utf-8')
sheet = book.sheet_by_index(0)
data = np.asarray([sheet.row_values(i) for i in range(1, sheet.nrows)], dtype=np.float32)
n_samples = sheet.nrows - 1
# step 2:定义输入输出的占位符
X = tf.placeholder(tf.float32, shape=[], name='input')
Y = tf.placeholder(tf.float32, shape=[], name='label')
# step 3:定义需要更新的参数w和b
w = tf.get_variable('weight',shape=[],initializer=tf.truncated_normal_initializer)
b = tf.get_variable('bias', shape=[], initializer=tf.zeros_initializer)
# step 4:定义模型输出和误差函数,这里使用均方误差
Y_predict = w * X + b;
loss = tf.square(Y - Y_predict, name='loss')
# step 5:定义优化函数,这里使用简单梯度下降
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1e-3).minimize(loss)
# step 6:在session中运算
init = tf.global_variables_initializer()
with tf.Session() as sess:
writer = tf.summary.FileWriter('./linear_log', graph=sess.graph)
sess.run(init)
for i in range(100):
total_loss = 0
for x, y in data:
_, l = sess.run([optimizer, loss], feed_dict={X: x, Y:y})
total_loss += l
print('Epoch {0}: {1}'.format(i, total_loss/n_samples))
w, b = sess.run([w, b])
writer.close()
# step 7:画出结果
X, Y = data.T[0], data.T[1]
plt.plot(X,Y, 'bo', label='Real data')
plt.plot(X,X*w+b, 'r', label='Predicted data')
plt.legend()
plt.show()可视化
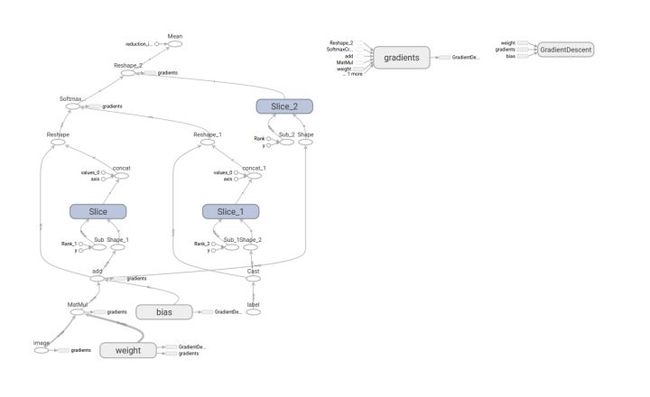
打开tensorboard查看我们的结构图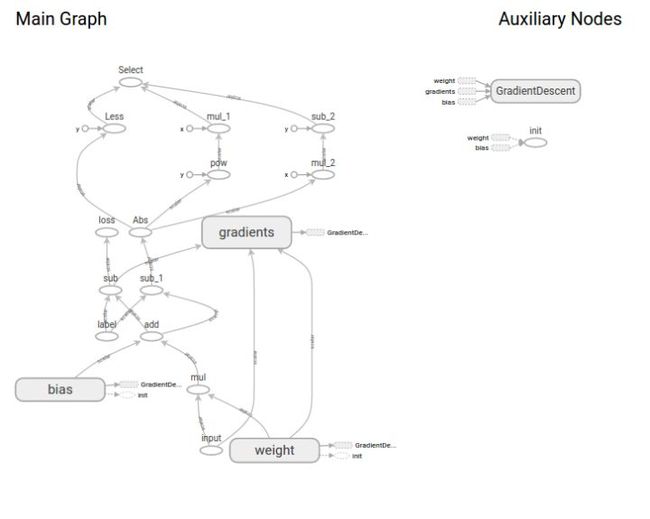
最后将数据点和预测直线画出来: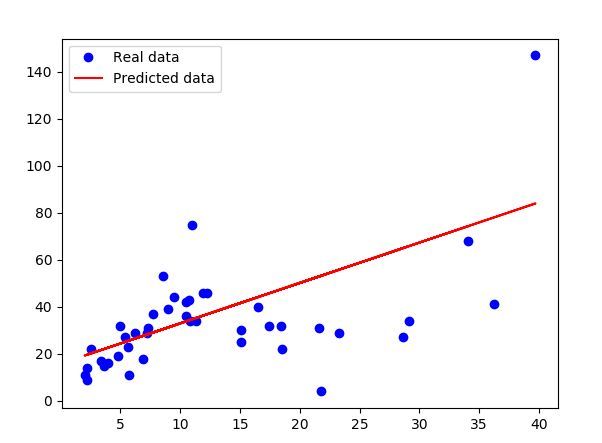
如何改善模型
- 增加维度,原始模型是\(Y=wX+b\),我们可以提升一维,使其变成\(Y=w_1X^2+w_2X+b\)
- 换一种计算loss的方法,比如huber loss,当误差小的时候用均方误差,误差大的时候使用绝对值误差
\[L_\delta(y,f(x))=\left\{\begin{array}{ll}\frac{1}{2}(y-f(x))^2&\textrm{for}|y-f(x)|\leq\delta \\ \delta|y-f(x)|-\frac{1}{2}\delta^2&\textrm{otherwise}\end{array} \right. \]
在实现huber loss的时候,因为tf是以图的形式来定义,所以不能使用逻辑语句,比如if等,我们可以使用TensorFlow中的条件判断语句,比如tf.where、tf.case等等,huber loss的实现方法如下:python def huber_loss(labels, predictions, delta=1.0): residual = tf.abs(prediction - labels) condition = tf.less(residual, delta) small_res = 0.5 * residual**2; large_res = delta * residual - 0.5 * delta**2 return tf.where(condition, small_res, large_res)
关于Optimizer
TensorFlow会自动求导,然后更新参数,使用一行代码:
tf.train.GradientDescentOptimizer(learning_rate=1e-3).minimize(loss)这里的过程我们分开来细讲。
自动梯度
- 首先是我们定义好优化函数:
python opt = tf.train.GradientDescentOptimizer(learning_rate) 定义好优化函数后,可以通过如下步骤计算梯度:
python grads_and_vars=opt.compute_gradients(loss,- )
第二个参数是一个list,该函数会计算loss对于变量列表里的每一个变量的梯度。得到的grads_and_vars是一个list of tuple,list中的每个tuple都是由(gradient, variable)对构成,我们可以通过使用如下代码提取出来:python get_grads_and_vars=[(gv[0],gv[1]) for gv in grads_and_vars]更新参数
python opt.apply_gradients(get_grads_and_vars)
举个例子:
import tensorflow as tf
x = tf.Variable(5, dtype=tf.float32)
y = tf.Variable(3, dtype=tf.float32)
z = x**2 + x * y + 3
sess = tf.Session()
# 初始化变量
sess.run(tf.global_variables_initializer())
# 定义优化函数
optimizer= tf.train.GradientDescentOptimizer(learning_rate=0.1)
# 计算z关于x,y的梯度
grads_and_vars = optimizer.compute_gradients(z, [x, y])
# 获取变量
get_grads_and_vars = [(gv[0], gv[1]) for gv in grads_and_vars]
# dz/dx = 2*x + y = 13
# dz/dy = x = 5
print('grads and variables')
print('x: grad {}, value {}'.format(sess.run(get_grads_and_vars[0][0]), sess.run(get_grads_and_vars[0][1])))
print('y: grad {}, value {}'.format(sess.run(get_grads_and_vars[1][0]), sess.run(get_grads_and_vars[1][1])))
print('Before optimization')
print('x: {}, y:{}'.format(sess.run(x), sess.run(y)))
# 优化参数
opt=optimizer.apply_gradients(get_grads_and_vars)
# x = x-0.1*dz/dx = 5-0.1*13=3.7
# y = y-0.1*dz/dy = 3-0.1*5 = 2.5
print('After optimization using learning rate 0.1')
sess.run(opt)
print('x: {:.3f}, y: {:.3f}'.format(sess.run(x), sess.run(y)))
sess.close()可得到结果: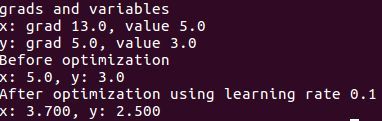
在实际操作中,不需要手动更新参数,optimizer类可以帮我们自动更新。另外还有一个函数也能够计算梯度。
tf.gradients(ys, xs, grad_ys=None, name='gradients', colocate_gradients_with_ops=False,gate_gradients=False, aggregation_method=None)该函数返回一个list,list的长度就是xs的长度,list中每个元素都是\(sum_{ys}(d(ys)/dx)\)。
实际运用: 这个方法对于只训练部分网络非常有用,我们能够使用上面的函数只对网络中一部分参数求梯度,然后对他们进行梯度的更新。
优化函数类型
SGD只是TF的一个小的更新方法,目前支持的更新方法如下:
tf.train.GradientDescentOptimizer
tf.train.AdadeltaOptimizer
tf.train.AdagradOptimizer
tf.train.AdagradDAOptimizer
tf.train.MomentumOptimizer
tf.train.AdamOptimizer
tf.train.FtrlOptimizer
tf.train.ProximalGradientDescentOptimizer
tf.train.ProximalAdagradOptimizer
tf.train.RMSPropOptimizerTensorFlow中的Logistic Regression
我们使用简单的logistic regression来解决分类问题,使用MNIST手写字体,模型公式如下:
\[\begin{array}{rl}logits &= X*w+b \\Y_{predicted} &={\bf softmax}(logits)\\ loss &= {\bf CrossEntropy}(Y, Y_{predicted})\end{array}\]
TensorFlow实现
- 读取MNIST数据集
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('./data/mnist', one_hot = True)定义占位符和权重参数
```python
x = tf.placeholder(tf.float32, shape=[None, 784], name='image')
y = tf.placeholder(tf.int32, shape=[None, 10], name='label')w = tf.get_variable('weight', shape=[784,10], initializer=tf.truncated_normal_initializer())
b = tf.get_variable('bias', shape=[10], initializer=tf.zeros_initializer())
``输入数据的shape=[None, 784]表示第一维接受任何长度的输入,第二维等于784因为$28\times 28=784$。权重w使用均值为0,方差为1的正太分布,偏置b`初始化为0.定义预测结果、loss和优化函数
python logits = tf.matmul(x, w)+b entropy = tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=logits) loss = tf.reduce_mean(entropy, axis=0) optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
使用tf.matmul做矩阵乘法,然后使用分类问题的loss函数交叉熵,最后将一个batch中的loss求均值,对其使用随机梯度下降法。数据集中有测试集,可以在测试集上验证准确率
python preds = tf.nn.softmax(logits) correct_preds = tf.equal(tf.argmax(preds, 1), tf.argmax(y, 1)) accuracy = tf.reduce_sum(tf.cast(correct_preds, tf.float32), axis=0)
首先对输出结果进行softmax得到概率分布,然后使用tf.argmax得到预测的label,使用tf.equal得到label和实际的label相同的个数,这是一个长为batch的0-1向量,然后使用tf.reduce_sum得到正确的总数。在session中运算
逻辑回归部分代码如下:
import tensorflow as tf
import time
# 模型参数
learning_rate = 0.01
batch_size = 128
n_epochs = 10
# step 1:读取数据集
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('./data/mnist', one_hot = True)
# step 2:定义占位符和更新变量
x = tf.placeholder(tf.float32, shape=[None, 784], name='image')
y = tf.placeholder(tf.int32, shape=[None, 10], name='label')
w = tf.get_variable('weight', shape=[784,10],initializer=tf.truncated_normal_initializer)
b = tf.get_variable('bias', shape=[10], initializer=tf.zeros_initializer)
# step 3:定义结果、loss和优化函数
logits = tf.matmul(x, w) + b
entropy = tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(entropy,axis=0)
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
preds = tf.nn.softmax(logits)
correct_preds = tf.equal(tf.argmax(preds, 1), tf.argmax(y, 1))
accuracy = tf.reduce_sum(tf.cast(correct_preds, tf.float32), axis=0)
with tf.Session() as sess:
writer = tf.summary.FileWriter('./logistic_log', graph=sess.graph)
start_time = time.time()
sess.run(tf.global_variables_initializer())
n_batches = int(mnist.train.num_examples / batch_size)
for i in range(n_epochs):
total_loss=0
for _ in range(n_batches):
X_batch, Y_batch = mnist.train.next_batch(batch_size)
_, loss_batch = sess.run([optimizer, loss], feed_dict={x: X_batch, y:Y_batch})
total_loss+=loss_batch
print('Average loss epoch {0}:{1}'.format(i, total_loss/n_batches))
print('Total time: {0} seconds'.format(time.time()-start_time))
print('Optimization Finished!')
# test model
n_batches = int(mnist.test.num_examples / batch_size)
total_correct_preds = 0
for i in range(n_batches):
X_batch, Y_batch = mnist.test.next_batch(batch_size)
accuracy_batch = sess.run(accuracy, feed_dict={x:X_batch,y:Y_batch})
total_correct_preds += accuracy_batch
print('Average {0}'.format(total_correct_preds/mnist.test.num_examples))
结果可视化
最后可以得到训练集的loss的验证集准确率如下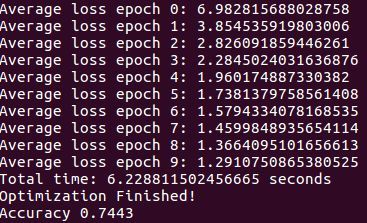
可以发现经过10 epochs,验证集能够实现74%的准确率。同时,我们还能够得到tensorboard可视化如下。