Pandas中read_excel函数参数使用详解+实例代码
目录
前言
一、数据展示
1.io
2.sheet_name
3.header
4.names
5.index_col
6.usecols
7.squeeze
8.dtype
9.engine
10.converters
11.true_values,false_values
12.skiprows
13.nrow
14.na_values
15.keep_default_na
16.na_filter
17.verbose
18.parse_dates
19.data_parser
20.mangle_dupe_cols
参阅:
前言
使用Pandas进行数据预处理时需要了解Pandas的基础数据结构Series和DataFrame。若是还不清楚的可以再去看看我之前的三篇博客详细介绍这两种数据结构的处理方法:
一文速学-数据分析之Pandas数据结构和基本操作代码
DataFrame行列表查询操作详解+代码实战
DataFrame多表合并拼接函数concat、merge参数详解+代码操作展示
以上三篇均为基础知识,没有比较难的实战,比较容易学会。
首先说明一点,关于包含在异常值里面的空值和重复值均有两篇博客专门详细介绍了处理他们的方法:
一文速学-Pandas处理重复值操作各类方法详解+代码展示
一文速学-Pandas处理缺失值操作各类方法详解
该篇博客主要详解读取Excel表函数read的各种参数的用法
此篇博客基于Jupyter之上进行演示,本篇博客的愿景是希望我或者读者通过阅读这篇博客能够学会方法并能实际运用,而且能够记录到你的思想之中。希望读者看完能够提出错误或者看法,博主会长期维护博客做及时更新。纯分享,希望大家喜欢。
一、数据展示
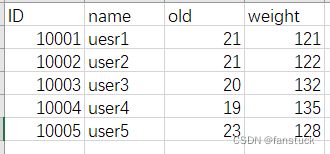
为方便演示函数效果这里创建一个excel文件,其中创建了两个表格:
sheet1:
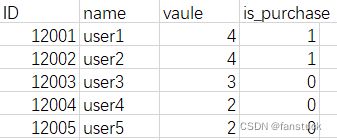
sheet2:
二、read_excel默认参数
def read_excel(io,
sheet_name=0,
header=0,
names=None,
index_col=None,
parse_cols=None,
usecols=None,
squeeze=False,
dtype=None,
engine=None,
converters=None,
true_values=None,
false_values=None,
skiprows=None,
nrows=None,
na_values=None,
keep_default_na=True,
na_filter=True,
verbose=False,
parse_dates=False,
date_parser=None,
thousands=None,
comment=None,
skip_footer=0,
skipfooter=0,
convert_float=True,
mangle_dupe_cols=True,
**kwds)
1.io
io为文件类对象,一般作为读取文件的路径:
excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx") 
2.sheet_name
该参数为指定读取excel的表格名
Sheet_name参数莫仍从零开始,也就是想读第二张表则将参数改为1即可:
excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",sheet_name=1) 
也可以设定值为列表,则一次返回一个字典:
excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",header=1) 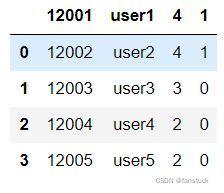
3.header
该参数为指定列表中从第几行作为列索引:
excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",header=1) 
如果设定为1则以第二行的数据作为列索引的值。
4.names
此参数接收一个数组,将列名重定义赋值:
excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",names=['value','old','1','2']) 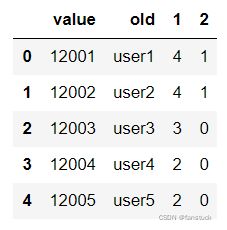
5.index_col
此参数为指定从第几列开始索引:
excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",index_col=1) 
6.usecols
该参数为返回指定的列,usecols=[A,C]表示只选取A列和C列。usecols=[A,C:E]表示选择A列,C列、D列和E列;:
excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",usecols="A,C") 
excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",usecols="A,C:D") 
也可以传入列表:
excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",usecols=[0,2]) 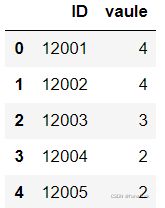
excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",usecols=['ID','vaule']) 
7.squeeze
若处理excel仅仅只有一列时,此时设定为True将转换为Series:
excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",usecols=['ID'],squeeze=True) 
8.dtype
指定读取列的数据类型,可接收字典:
excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",dtype={"ID":str,"vaule":np.float64}) 
若指定了“converters”参数,则dtype函数失效。
9.engine
该参数为指定Excel处理引擎,一般Excel处理引擎为xlrd,openpyxl,odf:
excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",engine='xlrd')10.converters
指定列数据类型转换函数,包括了dtype的功能,也可以对某一列使用Lambda函数,进行某种运算:
excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",converters={"ID":str,"vaule":np.float64})
excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",dtype={"ID":str},converters={"name":lambda x:"沪"+x,"vaule":lambda x: x+1}) 

11.true_values,false_values
传输一个列表判断为true或是false:
excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",sheet_name=1,true_values=['female'],false_values=['male'])
12.skiprows
此参数为跳过行操作:
excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",skiprows=[1,3])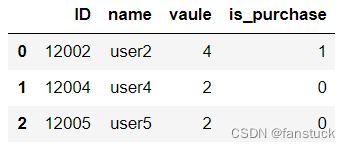
仅取偶数行:
excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",skiprows=lambda x:x%2==0) 
13.nrow
指定需要读取前多少行,通常用于较大的数据文件中。
excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",nrows=3)

14.na_values
将指定的值或者传入中的列表中的值设置为NaN:
excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",sheet_name=1,na_values='male') 
15.keep_default_na
作用:处理数据是否包含默认的NaN值
依赖于na_values参数是否被传递,默认为True,即自动识别空值导入。
16.na_filter
作用:检测缺少的值标记。当数据中没有任何NA值时,na_filter设置为False可以提高处理速度,特别是处理大文件时。
17.verbose
作用:指示放置在非数字列中NA值的数目
18.parse_dates
作用:处理日期类数据
这个参数蛮有意思,这里我重新创建个表:

excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",sheet_name=2,parse_dates={"日期":[0,1,2]}) 
19.data_parser
作用:设置处理日期数据的函数,利用lambda函数,将某个字符串列,解析为日期格式;
excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",sheet_name=3,parse_dates=[0],date_parser=lambda x:pd.to_datetime(x,format='%Y年%m月%d日'))
20.mangle_dupe_cols
可以使用此是参数处理重复的列:
这里改动一下sheet2:

excel=pd.read_excel(r"D:\Python\pythonlearn\test1.xlsx",sheet_name=4,mangle_dupe_cols=False)结果:
ValueError: Setting mangle_dupe_cols=False is not supported yet
现在还不支持这个函数貌似
参阅:
一个参数一张Excel表,玩转Pandas的read_excel()表格读取
Pandas read_excel()参数详解
easy excel date 类型解析报错_最新Pandas.read_excel()全参数详解(案例实操,如何利用python导入excel)...