transformer笔记
attention式子
self-attention=softmax(QK) V :
a t t e n t i o n 1 = s o f t m a x [ q ( x 1 ) k ( x 1 ) , q ( x 1 ) k ( x 2 ) , . . . , q ( x 1 ) k ( x n ) ] v ( x 1 , x 2 , . . . , x n ) attention_1= softmax[ q(x_1) k(x_1) , q(x_1) k(x_2) , ... , q(x_1) k(x_n) ] v(x_1,x_2,...,x_n) attention1=softmax[q(x1)k(x1),q(x1)k(x2),...,q(x1)k(xn)]v(x1,x2,...,xn)
输入句子是单词序列: x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn
v是对原词向量的重新表示, 上式意思是 此句子中的 第i个词向量xi 是 对该句子的各个词 进行加权平均.
上式中 q, k, v都是线性变换函数:如下:
q ( x ) = W q x q(x) = W_q x q(x)=Wqx
k ( x ) = W k x k(x) = W_k x k(x)=Wkx
v ( x ) = W v x v(x) = W_v x v(x)=Wvx
解码器出q,编码器出k、v,为何?
k,v都是全量的. 而q是当前词的. 所以解码器中 用了解码器的q, 而用了编码器的k,v 。 如下图所示:
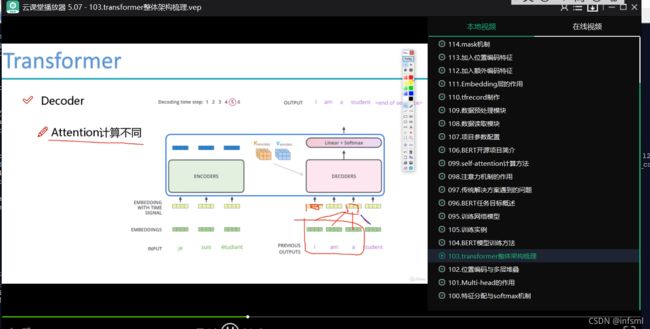
全量:整个句子的所有词
整个句子的所有词都可以用,即全量的,而k、v是全量的。
所以当 整个句子的所有词都可以用的时候 , 可以用k、v。
encoder中的每个词都可以用,全量,即可以用encoder的k、v。
而decoder中的剩余词是待预测的 是未知的,所以decoder并不是每个词都在 ,非全量,因此 不能使用decoder的k、v。
如果硬用decoder的包括剩余词的所有词,这是作弊。
todo: MASK???
bert
bert : Bidirectional Encoders Representation from Transformers.
bert 即 transformer中的 encoder
bert训练
-
方法1: 随机mask句子中的词, 要求bert预测被mask掉的词

-
给bert输入两个句子,问bert这两个句子是否应该连在一起?

bert 阅读理解
bert阅读理解如下图:
其中的 : s 向量 是 开始位置 的意思, e向量 是 结束位置 的意思。
当训练完, 对所有问题 :
- s 向量只是一个向量,
- 对每个问题 有一个不同的s向量
我理解 应该是情况1 而不是情况2
如果 是情况1 : 对所有问题,s向量是一个向量, 那么 :
s向量表示的 是 开始标志。 同样 e向量 表示的 是 结束标志。
开始标志: 答案的 开始标志
结束标志:答案的 结束标志
当预测的时候,只需要使用 开始标记向量s 和 结束标记向量e 即可。
