如何使用Pandas操作数据
Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
一、数据结构
pandas的主要数据结构包括Series和DataFrame。
(1)Series
它是一种类似于一维数组的对象,是由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series对象。Series的字符串表现形式为:索引位于左边,数据位于右边: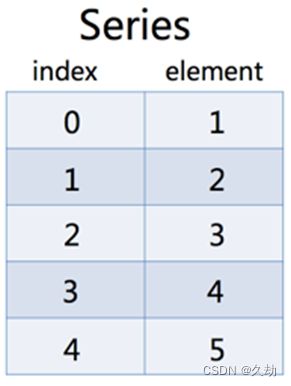
Pandas的Series类对象可以使用以下构造方法创建:
class pandas.Series(data = None,index = None,dtype = None,name = None,copy = False,fastpath = False)data:表示传入的数据。 index:表示索引,唯一且与数据长度相等,默认会自动创建一个从0~N的整数索引。
1、通过传入一个列表来创建一个Series类对象:
2、除了使用列表构建Series类对象外,还可以使用dict进行构建:
为了能方便地操作Series对象中的索引和数据,所以该对象提供了两个属性index和values分别进行获取。当某个索引对应的数据进行运算以后,其运算的结果会替换原数据,仍然与这个索引保持着对应的关系。
(2)DataFrame
DataFrame是一个类似于二维数组或表格(如excel)的对象,它每列的数据可以是不同的数据类型。DataFrame的索引不仅有行索引,还有列索引,数据可以有多列: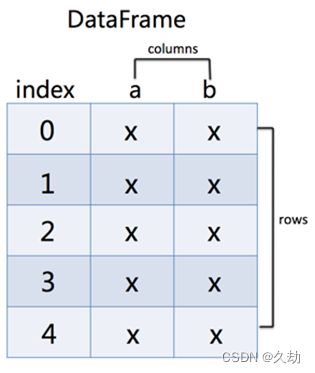
Pandas的DataFrame类对象可以使用以下构造方法创建:pandas.DataFrame(data = None,index = None,columns = None,dtype = None,copy = False )index:表示行标签。若不设置该参数,则默认会自动创建一个从0~N的整数索引。columns:列标签。
1、通过传入数组来创建DataFrame类对象:
在创建DataFrame类对象时,如果为其指定了列索引,则DataFrame的列会按照指定索引的顺序进行排列。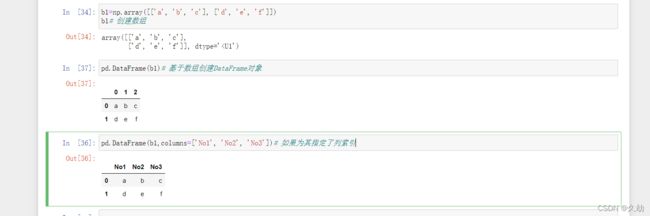
我们可以使用列索引的方式来获取一列数据,返回的结果是一个Series对象。我们还可以使用访问属性的方式来获取一列数据,返回的结果依然是一个Series对象。
要想为DataFrame增加一列数据,则可以通过给列索引或者列名称赋值的方式实现。
增加No4一列数据
df_obj['No4'] = ['g', 'h']
要想删除某一列数据,则可以使用del语句实现。
删除No3一列数据
del df_obj['No3']
二、索引对象
Pandas中的索引都是Index类对象,又称为索引对象,该对象是不可以进行修改的,以保障数据的安全。Pandas中提供了一个重要的方法是reindex(),该方法的作用是对原索引和新索引进行匹配,也就是说,新索引含有原索引的数据,而原索引数据按照新索引排序。
如果新索引中没有原索引数据,那么程序不仅不会报错,而且会添加新的索引,并将值填充为NaN或者使用fill_vlues()填充其他值。
reindex()方法的语法格式如下:
DataFrame.reindex(labels = None,index = None,
columns = None,axis = None,method = None,
copy = True,level = None,fill_value = nan,limit = None,tolerance = None )

如果使用的是位置索引进行切片,则切片结果是不包含结束位置;如果使用索引名称进行切片,则切片结果是包含结束位置的。
如果希望获取的是不连续的数据,则可以通过不连续索引来实现。

布尔型索引同样适用于Pandas,具体的用法跟数组的用法一样,将布尔型的数组索引作为模板筛选数据,返回与模板中True位置对应的元素。

DataFrame结构既包含行索引,也包含列索引。其中,行索引是通过index属性进行获取的,列索引是通过columns属性进行获取的。Pandas库中提供了操作索引的方法来访问数据,具体包括:loc:基于标签索引(索引名称),用于按标签选取数据。当执行切片操作时,既包含起始索引,也包含结束索引。
Pandas执行算术运算时,会先按照索引进行对齐,对齐以后再进行相应的运算,没有对齐的位置会用NaN进行补齐。如果希望不使用NAN填充缺失数据,则可以在调用add方法时提供fill_value参数的值,fill_value将会使用对象中存在的数据进行补充。
四、数据排序
Pandas中按索引排序使用的是sort_index()方法,该方法可以用行索引或者列索引进行排序

axis:轴索引,0表示index(按行),1表示columns(按列)。
level:若不为None,则对指定索引级别的值进行排序。

2、按索引对DataFrame进行分别排序,示例如下。

3、Pandas中用来按值排序的方法为sort_values(),该方法的语法格式如下。

by参数表示排序的列,na_position参数只有两个值:first和last,若设为first,则会将NaN值放在开头;若设为False,则会将NaN值放在最后。
5、按值的大小对Series进行排序的示例如下:
在DataFrame中,sort_values()方法可以根据一个或多个列中的值进行排序,但是需要在排序时,将一个或多个列的索引传递给by参数才行。
五、统计计算与描述
Pandas为我们提供了非常多的描述性统计分析的指标方法,比如总和、均值、最小值、最大值等。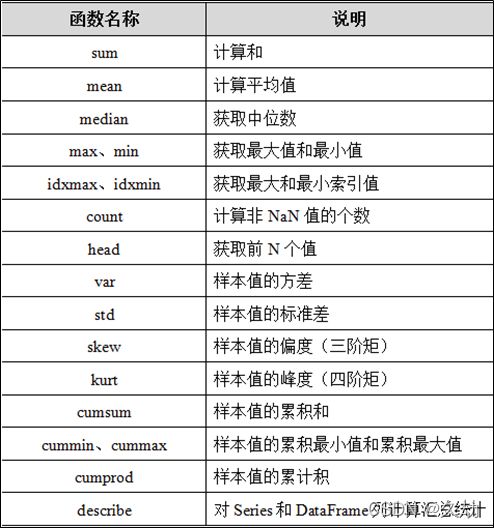
如果希望一次性输出多个统计指标,则我们可以调用describe()方法实现,语法格式如下
percentiles:输出中包含的百分数,位于[0,1]之间。如果不设置该参数,则默认为[0.25,0.5,0.75],返回25%,50%,75%分位数。
六、层次化索引
层次化索引可以理解为单层索引的延伸,即在一个轴方向上具有多层索引。对于两层索引结构来说,它可以分为内层索引和外层索引。
Series和DataFrame均可以实现层次化索引,最常见的方式是在构造方法的index参数中传入一个嵌套列表。
还可以通过MultiIndex类的方法构建一个层次化索引,该类提供了3种创建层次化索引的方法:
from_arrays()方法是将数组列表转换为MultiIndex对象,其中嵌套的第一个列表将作为外层索引,嵌套的第二个列表将作为内层索引。
from_product()方法表示从多个集合的笛卡尔乘积中创建一个MultiIndex对象。