贝叶斯聂曼准则matlab程序,基于朴素贝叶斯算法的情感分类
环境
win8, python3.7, jupyter notebook
正文
什么是情感分析?(以下引用百度百科定义)
情感分析(Sentiment analysis),又称倾向性分析,意见抽取(Opinion extraction),意见挖掘(Opinion mining),情感挖掘(Sentiment mining),主观分析(Subjectivity analysis),它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程,如从评论文本中分析用户对“数码相机”的“变焦、价格、大小、重量、闪光、易用性”等属性的情感倾向。
简单来说, 就是从文本中总结归纳出个人对某一话题的主观态度(褒义或贬义的两种或者更多种类型). 对于情感分析的方法中, 目前基于监督学习(已知分类标签)是主流, 我们选择监督学习算法中的朴素贝叶斯进行分析介绍.
1. 朴素贝叶斯
朴素贝叶斯中的朴素是指特征条件独立假设, 贝叶斯是指贝叶斯定理, 我们从贝叶斯定理开始说起吧.
1.1 贝叶斯定理
贝叶斯定理是用来描述两个条件概率之间的关系
1). 什么是条件概率?
如果有两个事件A和B, 条件概率就是指在事件B发生的条件下, 事件A发生的概率, 记作P(A|B).
若P(A)>0, 则满足以下公式

若P(B) > 0, 同理.
通过条件概率公式我们可以直接推出概率的乘法公式.
2). 概率的乘法公式
![]()
进而通过概率的乘法公式, 可以推出贝叶斯公式.
3). 贝叶斯公式
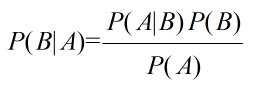
贝叶斯公式同样满足条件P(A)>0, P(B)>0, 在该公式中, A和B均代表单个事件, 但是当B代表一个事件组时, 公式又是如何呢?在介绍之前, 引出全概公式
4). 全概公式
当事件组B1, B2, B3, ....Bn是完备事件组(两两互不相容, 其和为全集), 并且当P(Bn) >0时, 对于任意一个事件A, 满足全概公式:
![]()
推导过程如下:

那么, 此时的完备事件组B1, B2, B3, ...Bn对于任意事件A的贝叶斯公式可写成:
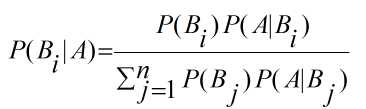
上式中P(Bi)被称为先验概率, P(Bi|A)被称为后验概率.
5). 先验概率, 后验概率分别指什么呢? (举例说明)
某地区10月份下大暴雨的概率为0.9. 下大暴雨时, 发洪水的概率是0.6; 不下大暴雨时, 发洪水的概率为0.02, 试求该地区已发洪水, 下暴雨的概率?
记A1=下大暴雨, B1=发洪水, A2=不下大暴雨, B2=不发洪水, 由题意知, P(A1) = 0.9, P(B1|A1) = 0.6, P(B1|A2) = 0.02, 根据贝叶斯公式得: P(A1|B1)=0.9*0.6/[0.9*0.6 + (1-0.9)*0.02] = 0.996.
从上述例子中, 先验概率(下大暴雨的概率)很容易从现有条件中得出, 而后验概率(已经发洪水时下大暴雨的概率)需要根据附加信息用贝叶斯公式去计算得出, 下面引出百度百科对于这两者的定义.
先验概率(prior probability)是指根据以往经验和分析得到的概率,如全概率公式,它往往作为"由因求果"问题中的"因"出现的概率
后验概率是指在得到“结果”的信息后重新修正的概率,是“执果寻因”问题中的"果"。先验概率与后验概率有不可分割的联系,后验概率的计算要以先验概率为基础.
事情还没有发生,要求这件事情发生的可能性的大小,是先验概率。事情已经发生,要求这件事情发生的原因是由某个因素引起的可能性的大小,是后验概率。
将定义与例题相结合就能更好的理解先验概率和后验概率.
6). 如果A也是事件组时, 公式又是如何呢?
假设现有两个事件A1和A2, 公式则可改写为:

要想求满足条件A1和A2时Bi的概率, 关键在于求P(A1, A2|Bi)的概率, 在这之前需要了解事件的独立性:
通常情况下, 条件概率P(A|B)与无条件概率P(A)是不相等的, 如果P(A|B)=P(A), 则说明事件B对事件A的发生没有任何影响, 也就是说事件A与B是相互独立的, 又根据我们上面的概率乘法公式可以推出P(AB)=P(A|B)P(B)=P(A)P(B).
现假设事件A1和事件A2关于事件B独立, 根据事件的独立性, 则有P[(A1|B)(A2|B)]=P(A1|B)P(A2|B), 又由于只有在事件B这个共同条件下事件A1才会与事件A2独立, 我们不妨将式子改写为P(A1, A2|B) = P(A1|B)P(A2|B), 从而可以将我们的贝叶斯公式改写为:

假设事件组Am中的所有事件关于完备事件组Bn中任意一个事件两两相互独立, 进而公式可以推广为:

要想上式成立, 则必须要满足前提条件: 事件组Am中的所有事件关于事件组Bn的任意一个事件两两相互独立, 到这里贝叶斯定理部分就介绍完毕了,
1.2 特征条件独立假设
将上面的公式应用到分类问题中, Am表示m个特征, Bn表示n个分类标签, 而要想上式成立, 要满足前提条件: m个特征关于n个分类标签中任意一个两两相互独立, 也就是特征条件独立, 而"朴素"二字表示特征条件独立假设, 即假设特征条件独立(前提条件), 想必这也就是为什么"朴素"二字恰好在贝叶斯之前.
1.3 朴素贝叶斯模型
朴素贝叶斯分类模型要做的事就是在先验概率的基础上将数据集归为n个标签中后验概率最大的标签(基于最小错误率贝叶斯决策原则).
由于数据集的特征个数m和分类标签总数n是固定不变的, 即贝叶斯定理中分母不变, 所以要求最大值, 只需求出分子中的最大值, 即下式中的最大值

又可利用argmax()函数, 表示为最大值的类别, 比如X1 = argmax(f(x))表示当f(x)中的自变量x=X1时, f(x)取最大值

即求自变量Bi的值, 当Bn = Bi时, 后验概率最大, 上式也称为朴素贝叶斯推导式
通过上式, 影响最终结果的有先验概率和条件概率, 另外满足特征条件独立假设时, 上式才会成立.即当先验概率, 条件概率和特征条件独立假设均成立时, 根据朴素贝叶斯推导式得出的结果具有真正最小错误率..
1) 先验概率
当先验概率已知时, 可以直接通过公式计算.
当先验概率未知时, 基于最小最大损失准则(让其在最糟糕的情况下, 带来的损失最小)或者N-P(聂曼-皮尔逊)决策准则来进行分类
2) 条件概率(举例说明)
现需对某产品评价中"质量好, 价格便宜, 颜值高"这三个词语作出统计, 假设它们之间两两相互独立. 已知某论坛上关于该产品的1000条评价中未购买用户概率为0.2, 未购买用户的评价中"质量好"出现0次, "价格便宜"出现100次, "颜值高"出现150次; 已购买用户的评价中"质量好"出现600次, "价格便宜"出现500次, "颜值高"出现700次, 试问评价中同时出现"质量好, 价格便宜, 颜值高"这三个词语的用户是未购买用户的概率.
首先, 特征条件相互独立, 且先验概率已知, 可直接列举出我们的公式:

事件B1表示未购买用户, 事件B2表示已购买用户, 事件A1, A2, A3则分别表示"质量好, 价格便宜, 颜值高".
由题知, P(A1|B1)=0, 分子为0, P(B1|A1, A2, A3)也就为0, 如果我们根据计算结果直接就下定义: 做出"质量好, 价格便宜, 颜值高"这个评价的用户不可能是未购买用户, 会有点以偏概全了, 比如现新有一条包含这三个词语的新评价且为未购买用户, 经询问, 该用户在体验朋友(已购买用户)的产品一段时间后, 进而在论坛作此评价. 对于此种情况, 重新计算吗?假设该用户在半个月, 一个月...后才出现, 我们要等半个月, 一个月..再计算的话, 有点不切合实际.
对于此种情况, 法国数学家拉普拉斯最早提出用加1的方法估计没有出现过的现象的概率, 所以加法平滑也叫做拉普拉斯平滑. 假定训练样本很大时, 每个分量计数加1造成的估计概率变化可以忽略不计,但可以方便有效的避免零概率问题。(参考自博文:https://www.cnblogs.com/bqtang/p/3693827.html)
应用在我们的示例中就是, P(A1|B1)=1/203, P(A2|B1)=101/203, P(A3|B1)=151/203, 进而求解即可
3) 特征条件独立假设
假设特征条件独立, 但是实际中往往不是真正独立甚至有时特征之间存在某种联系(比如年龄和星座), 这时就需通过特征选择, 主成分分析等方法尽可能让特征之间独立.
到这里, 朴素贝叶斯分类模型就介绍完了, 下面就是应用了, 决定将朴素贝叶斯应用在某电视剧的评论上进行情感分类
2. 爬取评论文本
由于我本人想对爬虫再练习练习, 所以先从爬虫开始介绍(哈哈, 有点自私了.., 对这部分内容不感兴趣的朋友可以跳过)
2.1 目标站点分析
分析的目的是为了找出真正的url, 请求方式等信息
2.2 新建爬虫项目
1. 在cmd命令行中执行以下命令, 新建youku项目文件
scrapy startproject yok
2. 进入yok项目中, 新建spider文件
cd yok
scrapy genspider pinglun yok.com
3. 新建main.py文件, 用来执行项目
2.3 定义要爬取的字段
在items.py文件中编辑如下代码
importscrapyfrom scrapy.item importItem, FieldclassYoukuItem(Item):content=Field()
2.4 编辑爬虫主程序
在pinglun.py文件中编辑
importscrapyimportjsonfrom yok.items importYokItemclassPinglunSpider(scrapy.Spider):
name= ‘pinglun‘allowed_domains= [‘yok.com‘]
episodes= [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]
defstart_requests(self):for ep inself.episodes:
url= ‘https://p.Id={0}&Page=1&pageSize=30‘.format(str(ep))yield scrapy.Request(url=url, callback=self.parse_pages, meta={‘ep‘:ep}, dont_filter=True)defparse_pages(self,response):‘‘‘获取总页数‘‘‘ep, results= response.meta[‘ep‘], response.text
results= results.replace(‘n_commentList(‘, ‘‘).replace(‘)‘, ‘‘)
results= json.loads(results, strict=False)if results.get(‘code‘) ==0:
pages= results.get(‘data‘).get(‘totalPage‘)for page in range(1, int(pages)+1):
url= ‘https://p.Id={0}Page={1}&pageSize=30‘.format(str(ep), str(page))yield scrapy.Request(url=url, callback=self.parse, dont_filter=True)defparse(self, response):‘‘‘解析内容‘‘‘results=response.text
results= results.replace(‘n_commentList(‘, ‘‘).replace(‘)‘, ‘‘)#strict表示对json语法要求不严格
results = json.loads(results, strict =False)
item=YoukuItem()if results.get(‘data‘):if results.get(‘data‘).get(‘comment‘):
comments= results.get(‘data‘).get(‘comment‘)for comment incomments:item[‘content‘] =comment.get(‘content‘).strip().replace(r‘\n‘,‘‘)yield item
2.5 保存到Mysql数据库
在pipelines.py中编辑
importpymysqlclassYokPipeline(object):def __init__(self):
self.db=pymysql.connect(
host=‘localhost‘,
user=‘root‘,
password=‘1234‘,
db=‘yok‘,
port=3306,
charset=‘utf8‘)
self.cursor=self.db.cursor()defprocess_item(self, item, spider):
sql= "INSERT INTO pinglun(content) values(%s)"data= (item["content"])try:
self.cursor.execute(sql, data)
self.db.commit()except:print(‘存储失败‘)
self.db.rollback()defclosed_spider(self, spider):
self.cursor.close()
self.db.close()
2.6 配置settings
BOT_NAME = ‘yok‘SPIDER_MODULES= [‘yok.spiders‘]
NEWSPIDER_MODULE= ‘yok.spiders‘USER_AGENT= ‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36‘ROBOTSTXT_OBEY=False
DOWNLOAD_DELAY= 2COOKIES_ENABLED=False
DEFAULT_REQUEST_HEADERS={‘:authority‘: ‘p.comments.yok.com‘,‘:method‘: ‘GET‘,‘:scheme‘: ‘https‘,‘accept‘: ‘*/*‘,‘accept-encoding‘: ‘gzip, deflate, br‘,‘accept-language‘: ‘zh-CN,zh;q=0.9‘,‘referer‘: ‘https://www.yok.com/id.html‘}
ITEM_PIPELINES={‘yok.pipelines.YokPipeline‘: 300,
}
2.7 执行程序
在main.py中编辑
from scrapy importcmdline
cmdline.execute(‘scrapy crawl pinglun‘.split())
最终爬取到1万5千多条数据.
3. 朴素贝叶斯分类
通过爬虫分析过程了解到我们的数据是无标签的, 但朴素贝叶斯是有监督的学习, 因此我又爬取了一些同类型电视剧评论的标签数据, 将问题转化为情感分类问题, 即通过这些标签数据进行训练模型, 进而对无标签数据进行分类.
3.1 从数据库中读取数据
importpandas as pdimportpymysql#连接数据库
conn = pymysql.connect(host=‘localhost‘, user=‘root‘, password=‘1234‘, port=3306, db=‘dn‘, charset=‘utf8‘)
sql= ‘select * from pinglun‘
#读取数据
df =pd.read_sql(sql, conn)#删除重复记录
df.drop_duplicates(inplace =True)#设置行的最大显示为2条
pd.set_option(‘display.max_rows‘, 2)
df

3.2 对数据进行分类
我们依据评分进行情感分类, 大于3分为积极情感, 小于3分为消极情感, 积极情感用1表示, 消极情感用0表示.
importnumpy as np#转换数据类型
df.score =df.score.astype(int)
teleplay_0= df[df.score <3]#通过比对,发现消极情感的总数较少,随机抽取同数量的积极情感
teleplay_1 = df[df.score > 3].sample(n=teleplay_0.shape[0])#对两者进行拼接
teleplay = pd.concat([teleplay_1, teleplay_0], axis=0)#对情感进行分类, 0消极,1积极
teleplay[‘emotion‘] = np.where(teleplay.score > 3, 1, 0)
teleplay

3.3 对评论进行分词处理
我这里采用两种库, 一个jieba, 一个是snownlp
1. 安装两个库
pip install jieba
pip install snownlp
2. 对评论进行分词
from snownlp importSnowNLPimportjieba#对评论进行分词, 并以空格隔开
teleplay[‘cut_jieba‘] = teleplay.content.apply(lambda x: ‘ ‘.join(jieba.cut(x)))
teleplay[‘cut_snownlp‘] = teleplay.content.apply(lambda x: ‘ ‘.join(SnowNLP(x).words))
teleplay
可以看到两者的分词结果还是有区别的

3.4 停用词处理
什么是停用词? 我们把"看到", "和", "的", "基本"等这类可忽略的词汇, 称为停用词. 它们的存在反而影响处理效率, 因此将它们除去.
defget_stopwords(path):‘‘‘读取停用词‘‘‘with open(path) as f:
stopwords= [i.strip() for i inf.readlines()]returnstopwords
path= r‘D:\aPython\Data\stopword.txt‘stopwords=get_stopwords(path)#分别去除cut_jieba和cut_snownlp中的停用词
teleplay[‘cut_jieba‘] = teleplay.cut_jieba.apply(lambda x: ‘ ‘.join([w for w in (x.split(‘ ‘)) if w not instopwords]))
teleplay[‘cut_snownlp‘] = teleplay.cut_snownlp.apply(lambda x: ‘ ‘.join([w for w in (x.split(‘ ‘)) if w not instopwords]))
teleplay

3.5 特征向量化
特征向量化的目的就是将mX1的矩阵转化为mXn的矩阵(其中1表示1维文本, n表示1维文本中的n个词汇), 分别计算n个特征词汇在m行中出现的频数
1. 在特征向量化之前按照2:8的比例将数据集随机划分为训练集和测试集.
from sklearn.model_selection importtrain_test_split#分别对cut_jieba和cut_snownlp进行划分
X1, X2, y = teleplay[[‘cut_jieba‘]], teleplay[[‘cut_snownlp‘]], teleplay.emotion
X1_train, X1_test, y1_train, y1_test= train_test_split(X1, y, test_size=0.2)
X2_train, X2_test, y2_train, y2_test= train_test_split(X2, y, test_size=0.2)
2. 特征向量化(只对训练集进行向量化)
from sklearn.feature_extraction.text importCountVectorizer#初始化
vect =CountVectorizer()#分别对cut_jieba和cut_snownlp进行向量化, 并转化为dataframe.
vect_matrix_1 = pd.DataFrame(vect.fit_transform(X1_train.cut_jieba).toarray(), columns =vect.get_feature_names())
vect_matrix_2= pd.DataFrame(vect.fit_transform(X2_train.cut_snownlp).toarray(), columns =vect.get_feature_names())
vect_matrix_1
vect_matrix_2


可以看到向量化的结果中存在05, 07, 08...等数字, 而且这些数字对于分类的结果无太大作用, 需要剔除, 可以选择在向量化之前借助正则表达式进行剔除, 下面直接在CountVectorizer中筛选
#max_df的类型若为int, 则表示过滤掉文档中出现次数大于max_df的词汇, 若为float时, 则是百分比; min_df类似, token_pattern表示token的正则表达式
vect = CountVectorizer(max_df = 0.8,
min_df= 2,
token_pattern= r"(?u)\b[^\d\W]\w+\b")
vect_matrix_1= pd.DataFrame(vect.fit_transform(X1_train.cut_jieba).toarray(), columns =vect.get_feature_names())
vect_matrix_2= pd.DataFrame(vect.fit_transform(X2_train.cut_snownlp).toarray(), columns =vect.get_feature_names())
vect_matrix_1
vect_matrix_2
两种分词方式经过同样的处理之后均过滤掉一半以上.


3.6 构建模型
1. 构建模型与交叉验证
from sklearn.pipeline importmake_pipelinefrom sklearn.naive_bayes importMultinomialNBfrom sklearn.model_selection importcross_val_score#初始化朴素贝叶斯模型
nb =MultinomialNB()#利用pipeline管道进行特征向量化
pipe =make_pipeline(vect, nb)#交叉验证,将训练集分成10份,即计算10次,在每次计算中用10份中的一份当作验证集,对应的另外9份用作训练集,最后对10次计算出的准确率求平均值
score1 = cross_val_score(pipe, X1_train.cut_jieba, y1_train, cv=10, scoring=‘accuracy‘).mean()
score2= cross_val_score(pipe, X2_train.cut_snownlp, y2_train, cv=10, scoring=‘accuracy‘).mean()
score1
score2
0.8002292107510046
0.7559003695080964
在训练集上, jieba分词后的模型的准确率比snownlp能高些
2. 模型评估
from sklearn importmetrics#训练出模型
pipe1= pipe.fit(X1_train.cut_jieba, y1_train)
pipe2= pipe.fit(X2_train.cut_jieba, y2_train)#用训练的模型分别预测cut_jieba和cut_snownlp的测试集
y1_pre =pipe1.predict(X1_test.cut_jieba)
y2_pre=pipe2.predict(X2_test.cut_snownlp)#评价模型预测结果
metrics.accuracy_score(y1_test, y1_pre)
metrics.accuracy_score(y2_test, y2_pre)
0.8071278825995807
0.7631027253668763
在测试集上, jieba同样比snownlp的准确率高, 对于分类问题通常用混淆矩阵中的精准度和召回率进行评价.
1) 混淆矩阵

1和0表示真实值(1和0代表两个类别, 非数字意义), P和N表示预测值, T表示预测正确, F则错误
准确率: (TP+TN)/(1+0)
灵敏度: TP/1
精准度: TP/(TP+FP)
召回率: TP/(TP+FN)等价于灵敏度
2) 在朴素贝叶斯怎么才能得到混淆矩阵?
#分别求得cut_jieba和cut_snownlp的混淆矩阵
con_matrix1 =metrics.confusion_matrix(y1_test, y1_pre)
con_matrix2=metrics.confusion_matrix(y2_test, y2_pre)#分别计算精准率和召回率
accu_rate1, accu_rate2= con_matrix1[0][0]/(con_matrix1[1][0]+con_matrix1[0][0]), con_matrix2[0][0]/(con_matrix2[1][0]+con_matrix2[0][0])
recall_rate1, recall_rate2= con_matrix1[0][0]/(con_matrix1[0][1]+con_matrix1[0][0]), con_matrix2[0][0]/(con_matrix2[0][1]+con_matrix2[0][0])print(‘jieba_confused_matrix:‘)print(con_matrix1)print(‘accurate_rate:{0}, recall_rate:{1}‘.format(accu_rate1, recall_rate1))print()print(‘snownlp_confused_matrix:‘)print(con_matrix2)print(‘accurate_rate:{0}, recall_rate:{1}‘.format(accu_rate2, recall_rate2))
jieba_confused_matrix:
[[351 130]
[ 54 419]]
accurate_rate:0.8666666666666667, recall_rate:0.7297297297297297
snownlp_confused_matrix:
[[353 146]
[ 80 375]]
accurate_rate:0.815242494226328, recall_rate:0.7074148296593187
在精准度和召回率上jieba同样表现更佳, 也从另一个层面上说明了特征的重要性, snownlp还有情感分类功能, 不妨看看结果如何
3) snownlp情感分类
y_pred_snow = X1_test.cut_jieba.apply(lambdax: SnowNLP(x).sentiments)
y_pred_snow= np.where(y_pred_snow > 0.5, 1, 0)
metrics.accuracy_score(y1_test, y_pred_snow)
metrics.confusion_matrix(y1_test, y_pred_snow)
0.640461215932914
array([[179, 299],
[ 44, 432]], dtype=int64)
可以看到在电视剧的评论上准确率不高, 但是精确率还是很高的: 0.80, 召回率: 0.37
下面将利用训练出的模型对新数据集进行情感分类
4. 情感分类
通过以上可以看到通过jieba分词后训练的朴素贝叶斯模型还是相当不错的, 那么现在就用该模型对新数据集进行分类
#读取数据, 删除重复项以及jieba分词
conn = pymysql.connect(host = ‘localhost‘, user=‘root‘, password = ‘1234‘, port=3306,db=‘yu‘, charset=‘utf8‘)
sql= ‘select * from pinglun‘yk=pd.read_sql(sql, conn)
yk.drop_duplicates(inplace=True)
yk[‘cut_content‘] = yk.content.apply(lambda x: ‘ ‘.join(jieba.cut(x)))#用模型进行情感分类
yk[‘emotion‘] =pipe1.predict(yk.cut_content)#计算积极情感占比
yk[yk.emotion_nb == 1].shape[0]/yk.shape[0]
0.5522761760242793
另外根据模型在测试集的精准度0.87(在预测的结果为1中有87%真实值也是1), 因此在0.55的基础上再乘0.87, 结果为0.48, 这仅仅是预测为1且真实为1所占总体的参考比例, 不妨再利用snownlp对情感进行分类
#利用snownlp进行情感分类
emotion_pred = yk.cut_content.apply(lambdax: SnowNLP(x).sentiments)
yk[‘emotion_snow‘] = np.where(emotion_pred > 0.5, 1, 0)#计算积极情感占比
yk[yk.emotion_snow == 1].shape[0]/yk.shape[0]
0.6330804248861912
两者的差距也是挺大的, 相差8个百分点
#随机抽取1个
yk.sample(n=1)
![]()
表情就能表示出情感, 没能预测正确看来还是训练数据量太少, 要扩充啊, 另外当训练数据达到某种程度, 会远超人类的判断力
5. 生成词云图
importmatplotlib.pyplot as pltfrom wordcloud importWordCloud
bg_image= plt.imread(r‘tig.jpg‘)
wc= WordCloud(width=1080, #设置宽度
height=840, #设置高度
background_color=‘white‘, #背景颜色
mask=bg_image, #背景图
font_path=‘STKAITI.TTF‘, #中文字体
stopwords=stopwords, #停用词
max_font_size=400, #字体最大值
random_state=50 #随机配色方案
)
wc.generate_from_text(‘ ‘.join(yk.cut_content)) #生成词云
plt.imshow(wc) #绘制图像
plt.axis(‘off‘) #关闭坐标轴显示
wc.to_file(‘pig.jpg‘)
plt.show()

以上便是对学习过程的总结, 若出现错误, 还望指正, 谢谢!
参考:
http://www.cnblogs.com/mxp-neu/articles/5316989.html
https://www.jianshu.com/p/29aa3ad63f9d
声明: 本文仅用作学习交流
原文:https://www.cnblogs.com/star-zhao/p/9940437.html