python实现朴素贝叶斯算法
公式推导 =>
条件概率公式:
,又有乘法公式:
把乘法公式带入条件概率公式可得最终公式:
公式理解:
(1.) 其中w为测试文本转化成的行向量,大小等于单词文本库的列数,每个文本库里的单词作为一个特征,这个特征只能取值为0或者1,代表该单词出现或者不出现。
(2.)
在这里是是否为侮辱型文本,
为单词文本库中侮辱型文本占总文本库的比例(概率)。
(3.) 上述公式我们用了朴素贝叶斯假设,即所有特征是相互独立的,因此有
,它的意思是在已知文本是
算法思路:
(1) 算法目的就是给你一个文本,判断它是侮辱性文本还是正常文本。根据贝叶斯准则,我们只需要分别计算出该测试文本是侮辱性文本的概率和是正常文本的概率,比较这两个概率的大小,如果是侮辱性文本的概率大,那么这个文本就是侮辱性文本 ; 反之,这个文本是正常文本。
(2) 观察公式,发现计算该文本是侮辱性文本概率和计算该文本是正常文本概率都需要计算分母 p(w),而我们的目的是比较两者大小,所以我们只需要计算公式的分子即可。
(3) 首先我们先制成一个总的文本库矩阵
① 把已知的单词文本去重,并压缩成一个行向量。这个行向量包括了所有不重复的单词。
② 根据刚才制成的行向量再制一个等大的(就是等列数) 0向量,对初始单词文本库一行一行的遍历(这里的一行就是一个文本),再检查这一行的每一个单词是否存在于①步骤制成的单词行向量中。如果存在,则记录下这个单词在单词行向量的下标,将此时的等大的0向量也在该下标处的值设为1,表示这个词出现过。经过一行行循环,得到一个行数等于文本数,列数等于①步骤制成的单词行向量的列数的矩阵。
(4) 计算任意测试文本属于侮辱性文本的概率,得到的概率向量其实就是每个特征(单词)在侮辱性文本中出现的概率,然后乘以测试文本向量就是
。
算法细节:
(1.) 因为我们先计算了任意文本是侮辱性文本的概率,再乘以测试文本向量,因此有的单词可能在侮辱性文本中没出现过,即
中若有一项为0,则该表达式为0 ,不符合要求。故我们在初始化每个单词出现频数的时候默认每个单词都起始出现1次,而不是初始频数设置为0次。当然相应的分母也要改。
(2.) 因为
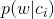
代码步骤:
一、 创建单词库行向量,并把初始单词文本库用该行向量表示
from numpy import * def loadDataSet(): postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], ['mybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', ' posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', ' buying', 'worthless', 'dog', 'food', 'stupid']] classVec = [0,1,0,1,0,1] # 已知文本的类别 return postingList, classVec def createVocabList(dataSet): # 参数dataSet就是上一个函数的postingList vocabSet = set([]) # set出来是元组 for document in dataSet: vocabSet = vocabSet | set(document) # 这里或操作相当于添加,此函数作用相当于把这所有单词制成一个行向量 return list(vocabSet) def setOfWord2Vec(vocabList, inputSet): # vocabList 相当于一个单词库行向量,它包含了不重复单词 returnVec = [0] * len(vocabList) # 定义一个跟上述单词库行向量一样大的零向量,记录每个单词是否出现 for word in inputSet: # 遍历输入行向量的每一个单词 if word in vocabList: # 判断该单词是否在单词文本库行向量中 returnVec[vocabList.index(word)] = 1 # 若在,则把0向量在该下标处的值置为1 else: print("the word: %s is not in my Vocabulary!"%word) return returnVec # 返回改变后的0零向量
二、计算任意样本是侮辱性文本的概率:
def trainNB0(trainMatrix, trainCategory): # 算的是每个词在侮辱性文档中出现的概率,和在正常文档中出现的概率 # 参数trainMatrix的每一行是一个文本向量,里面都是0或者1,它的列数等于前面单词库行向量的列数 numTrainDocs = len(trainMatrix) # 矩阵的行数就是一个样本文档数 numWords = len(trainMatrix[0]) # 每个文档的单词数,就是这个矩阵的列数 pAbusive = sum(trainCategory)/float(numTrainDocs) # 包含恶意词的样本占总样本的概率即p(ci) p0Num = ones(numWords) # 为防止之后分子相乘 因为一个为0全部为0的状况 p1Num = ones(numWords) p0Denom = 1*numWords # 分母项 分子改变了,因为初始单词频数由0变为了1,所以分母应该加上1×numWords p1Denom = 1*numWords # 初始化分母项 for i in range(numTrainDocs): # 一行一行的,也就是一个样本一个样本的取 if trainCategory[i] ==1: # 如果是包含侮辱词的样本 p1Num += trainMatrix[i] # 把所有侮辱文本中出现的每个词的出现过的频数加起来,这里的频数不是单词出现了多少次,而是有多少次出现过,这里就是矩阵竖着按行加起来 p1Denom += sum(trainMatrix[i]) # 侮辱性文档出现的词的总个数 else: p0Num += trainMatrix[i] p0Denom += sum(trainMatrix[i]) p1Vect = log(p1Num/p1Denom) # 任意文本的单词在侮辱性文本中出现的概率 p0Vect = log(p0Num/p0Denom) return p0Vect, p1Vect, pAbusive★ 注意:
因为这里我们把每个单词作为一个特征,把单词是否出现表示成0或者1,因此使用该算法是没有问题的,但是如果你想把朴素贝叶斯应用到其他场景,如果其他场景的特征不止有0或者1这两个取值,而是有多个取值,如特征可能是身高,取值可能有三种:矮、中、高,那么此算法是不适应的(即使你表示为0,1,2也不行的,问题出现在p1Num += trainMatrix[i]和p1Denom += sum(trainMatrix[i])上)
三、给出测试文本,比较两个概率,输出最终结果
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1): # vec2Classify测试文本的0或1的行向量 # p0Vec每个单词在正常文本中出现的概率,p1Vec每个单词在侮辱文档出现的概率,pClass1出现侮辱文档在总文档中占的概率 p1 = sum(vec2Classify * p1Vec) + log(pClass1) p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1) if p1 > p0: # 比较两个概率 return 1 # 1代表侮辱性文本 else: return 0 def testingNB(): listOPosts, listClasses = loadDataSet() # 得到文本库,即所有单词,是个多维数组 myVocabList = createVocabList(listOPosts) # 把这个文本库去重,制成一个行向量 trainMat = [] for postingDoc in listOPosts: trainMat.append(setOfWord2Vec(myVocabList, postingDoc)) # 把这文本库制成只有0和1的多维向量,以上三步作用是把文本单词替换为0,1表示 p0v, p1v, pAb = trainNB0(array(trainMat), array(listClasses)) testEntry = ['love', 'my', 'dalmation'] thisDoc = array(setOfWord2Vec(myVocabList, testEntry)) print("{0},classified as: {1}".format(testEntry, classifyNB(thisDoc, p0v, p1v, pAb))) testEntry1 = ['stupid', 'garbage'] thisDoc1 = array(setOfWord2Vec(myVocabList, testEntry1)) print("{0},classified as: {1}".format(testEntry1, classifyNB(thisDoc1, p0v, p1v, pAb))) testingNB0() # 调用函数★ 注意:
求最终结果
之所以写成: p1 = sum(vec2Classify * p1Vec) + log(pClass1) 是因为:
我们由于防止下溢出,并且只需要得到分子就能得到最后结果,所以我们对分子进行取对数。即
根据我们的正常思维而编出程序是:p1 = sum(log(vec2Classify*p1Vec))+log(pClass1),但是编程过程中我们先计算了任意样本在类别1(或2)的概率p1Vec,然后 点乘 测试文本转化后的向量来得到测试文本中的单词在该类别中的概率,所以,我们编程使用的
不是公式中的
都是测试文本中至少出现过一次的单词,而编程中的
如果还有不明白公式含义的请参考下列帖子:
https://blog.csdn.net/lyl771857509/article/details/78993493