Python 基于SVM和KNN算法的红酒分类
Python 机器学习之红酒分类问题
文章目录
-
- Python 机器学习之红酒分类问题
- 前言
- 一、问题和目标是什么
-
- 1.原题
- 2.题目分析
- 二、算法简介
- 三、代码实现
-
- 1.算法流程框架
- 2.第三方库调用
- 3.源代码
- 总结
- 参考网站
前言
又是一门考试后的大作业,没错就是数据挖掘,老师提供了红酒分类问题和乳腺癌诊断问题两个问题供大家选择,都是非常经典的机器学习案例。同时老师也提议大家选择难度较大的红酒分类问题,然而我当时写的时候一眼相中的就是红酒分类问题,因为数学建模竞赛里最喜欢出这类题目了。
话不多说,开始分享!
一、问题和目标是什么
1.原题
红酒分类问题
某研究获取了若干红酒的类别数据,存放于wine数据.txt 中。
每个样本的第一个属性是类别(1或2或3),其余按顺序均有如下13个属性,此处略……就是样本属性。
请自行从数据集中选出100个样本作为训练样本,其余样本作为测试样本。
并选择两种分类器进行分类(选择范围包括但不限于决策树、朴素贝叶斯分类器、人工神经网络网络、支持向量机)。要求
- 对两种分类器都尝试A. 对数据进行降维后再分类 以及 B.直接分类 两种方式。
- 比较四种组合(分类器1降维后分类、分类器1直接分类、分类器2降维后分类、分类器2直接分类)在测试样本上的准确率。
- 实验报告中说明训练样本和测试样本如何选择
- 为了使得数据适应所选择的分类器,要进行适当的数据预处理
2.题目分析
显然这是一个三分类问题,可以使用支持向量机、神经网络等分类算法,不过要注意的是这里提供的数据都是数值型不带标签的,不宜使用贝叶斯,决策树等算法。
针对题目要求作出如下分析:
- 降维要降到几维呢,一般来说都是2、3维,为了方便画图呈现效果就选择2维;
- 对于数据的预处理操作,是否进行标准化处理视分类器特性而定;
- 对于数据的划分,100个样本训练集中要覆盖到每一类的样本,这里我采用的是平均划分。读者也可以按照特定区域内的随机划分,不过这样实现起来也相应会复杂一些。
导入数据集可知,前59个样本全是第1类,中间71个样本为第2类,最后48个样本是第3类,故按照100:178比例划分为训练数据集,第1类数据量为33,第2类为40,第3类为27,剩余为测试数据集。
二、算法简介
选取的SVM模型和KNN模型代表着两个极端,在机器学习中SVM支持向量机以算法模型健壮性著称,核心算法强大,而KNN则是公认最简单的机器学习算法,算法原理简单。支持向量机(Support Vector Machine, SVM)是在统计学习理论的VC维理论和结构风险最小原理的基础上发展起来的一种新的机器学习方法,其中的核函数、最大间隔分类超平面技术让SVM格外强大。
而KNN算法原理简单,概括讲就是当预测一个新的值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别,这一点在研读python相关模块的源代码后也可以看出,KNN在模型构建的时候几乎没有做任何事情,因为KNN是一种非参的,惰性的算法模型。
着重说KNN,引用百度百科介绍:
核心思想
KNN算法的核心思想是,如果一个样本在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。KNN方法在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合 [3] 。
算法流程
总体来说,KNN分类算法包括以下4个步骤:
①准备数据,对数据进行预处理 。
②计算测试样本点(也就是待分类点)到其他每个样本点的距离 。
③对每个距离进行排序,然后选择出距离最小的K个点 。
④对K个点所属的类别进行比较,根据少数服从多数的原则,将测试样本点归入在K个点中占比最高的那一类
优点
KNN方法思路简单,易于理解,易于实现,无需估计参数,无需训练 。
缺点
该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数 。
该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点
三、代码实现
1.算法流程框架
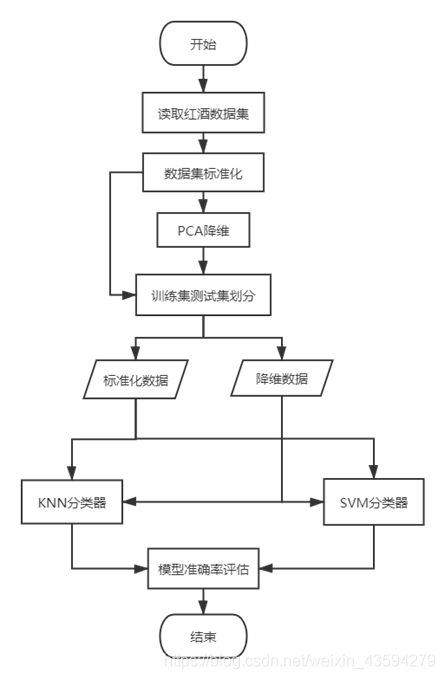
2.第三方库调用
import numpy as np
from sklearn import svm
from sklearn.datasets import load_wine
from sklearn.decomposition import PCA
from matplotlib import pyplot as plt
from sklearn.metrics import accuracy_score, classification_report
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
第三方库简介:
1.svm中的SVC实现多分类器;
2.load_wine导入数据集,没想到吧,其实老师所给数据集和这个库里面的数据是相同的,只不过老师自己改了一下标签编号,将0-2的标签序号改成了1-3而已;
3.PCA实现降维;
4.matplotlib.pyplot绘制散点图;
5.accuracy_score输出预测结果准确率,classification_report生成分类报告(包含F值、召回率等);
6.StandardScaler标准化数据
7.KNeighborsClassifier实现K近邻算法
3.源代码
def pca_show(pca_data, target): # 绘制PCA降维后图像
color = ['r', 'g', 'b'] # 图像点颜色
marker = ['s', 'x', 'o'] # 图像点样式
for lb, c, m in zip(np.unique(target), color, marker): # 绘制数据点
plt.scatter(pca_data[target == lb, 0],
pca_data[target == lb, 1],
c=c, label=lb, marker=m)
plt.title('Result')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.legend(loc='upper right')
plt.show()
def data_split(data, target):
"""
数据集前59个样本全是第1类,中间71个样本为第2类,最后48个样本是第3类
分布区间为 0:58 , 59:129, 130:177 左右都是闭区间
按照100:178比例划分数据集,第1类数据量为59*100/178 = 33,同理第2类为40,第3类为27
故训练集区间为 0:33,59:99,130:157 左闭右开
测试集区间为 33:59,99:130,157:177 左闭右开
"""
def cell_concatenate(data_tuple): # data_tuple内的数据连接
return np.concatenate(data_tuple, axis=0)
# 数据分解
train_data = cell_concatenate((data[0:33, :], data[59:99, :], data[130:157, :])) # 训练集
train_target = cell_concatenate((target[0:33], target[59:99], target[130:157])) # 样本类别
test_data = cell_concatenate((data[33:59, :], data[99:130, :], data[157:, :])) # 测试集
test_target = cell_concatenate((target[33:59], target[99:130], target[157:])) # 样本类别
# print(train_data.shape)
# print(test_data.shape)
return train_data, train_target, test_data, test_target
def svm_classifier(train_X, train_Y, test_X, test_Y, title):
print("SVM分类器", title)
svm_clf = svm.SVC(kernel='linear', C=1000.)
svm_clf.fit(train_X, train_Y) # 训练数据集
predict_Y = svm_clf.predict(test_X) # 预测
print("训练准确率为{:.3f}%".format(accuracy_score(test_Y, predict_Y) * 100))
print(classification_report(test_Y, predict_Y))
def knn_classifier(train_X, train_Y, test_X, test_Y, title):
print("KNN分类器", title)
knn = KNeighborsClassifier(algorithm='auto', leaf_size=10, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=2, p=2,
weights='uniform')
knn.fit(train_X, train_Y) # 加载数据集
predict_Y = knn.predict(test_X)
print("训练准确率为{:.3f}%".format(accuracy_score(test_Y, predict_Y) * 100))
print(classification_report(test_Y, predict_Y))
# if "PCA" in title:
# pca_show(test_X,predict_Y)
if __name__ == '__main__':
wine_dataset = load_wine() # 导入红酒数据集,数据为字典形式,数据集在data键中,标签在target键中
print("初始化完成")
sc = StandardScaler() # 数据标准化处理
wine_data_std = sc.fit_transform(wine_dataset['data'])
pca = PCA(n_components=2) # PCA降维降至2维
pca.fit(wine_data_std) # PCA训练
wine_data_pca = pca.fit_transform(wine_data_std)
pca_show(wine_data_pca, wine_dataset['target']) # 展示数据图像
# 原始数据划分后的训练、测试数据集
train_X, train_Y, test_X, test_Y = data_split(wine_dataset['data'], wine_dataset['target'])
# 标准化后的训练、测试数据集
train_X_std, train_Y_std, test_X_std, test_Y_std = data_split(wine_data_std, wine_dataset['target'])
# 降维后的训练、测试数据集
pca_train_X, pca_train_Y, pca_test_X, pca_test_Y = data_split(wine_data_pca, wine_dataset['target'])
svm_classifier(train_X, train_Y, test_X, test_Y, title="原始数据")
svm_classifier(train_X_std, train_Y_std, test_X_std, test_Y_std, title="标准化后数据")
svm_classifier(pca_train_X, pca_train_Y, pca_test_X, pca_test_Y, title="PCA降维后数据")
knn_classifier(train_X, train_Y, test_X, test_Y, title="原始数据")
knn_classifier(train_X_std, train_Y_std, test_X_std, test_Y_std, title="标准化后数据")
knn_classifier(pca_train_X, pca_train_Y, pca_test_X, pca_test_Y, title="PCA降维后数据")
总结
总体来讲,此案例难度不大,只要掌握了基本的算法原理,能够正确调用第三方库实现相应算法即可,API的学习务必参考官方文档或者是第三方库的项目源代码。主要麻烦在于数据处理和结果对比分析,这就需要读者独立完成,我只提供了大部分可使用的函数和方法框架,细节还需大家自己完善。
欢迎和我讨论交流,错误之处望批评和指正。看到这里的就顺便点个赞吧,这对我很重要!
参考网站
基于SVM分类器的红酒数据分析
KNN红酒数据集分类—机器学习
主成分分析PCA数据降维原理及python应用(葡萄酒案例分析)