使用Google colab进行机器学习项目开发
您是否曾经想要一个易于配置的交互环境来运行您的机器学习代码,免费访问图GPU?Google Colab 正是我们要找的。在云上运Jupyter notebooks是一种方便易用的方式,但是免费版本对GPU的使用也做了一定的限制,但不影响我们基本的代码开发使用GPU。
通过本博客,可以了解到以下技能:
Google Colab使用免费GPU加速训练- 使用
Google Colab的扩展包将数据保存到Google Drive, 为pandas ,DataFrame等提供交互式显示。 - 使用
Google Colab进行训练时,保存模型的进度
概述
本博客分为五个部分;它们是:
- 什么是Google Colab?
- Google Colab快速入门指南
- 探索Colab开发环境
- 好用的谷歌Colab扩展包介绍
- 案例:在Google Drive上保存模型进度
什么是Google Colab?
引用自“Welcome to Colab”Notebok:
Colab notebooks 允许您将可执行代码和富文本与图像、HTML、LaTeX等一起组合在一个文档中。当您创建自己的Colab notebooks时,它们将存储在您的Google Drive 帐户中。您可以轻松地与同事或朋友分享您的Colab notebooks ,允许他们对您的笔记本发表评论,甚至编辑它们。
我们可以像Jupyter notebooks一样使用Google Colab。它们真的很方便,因为Google Colab托管它们,所以我们不用自己的任何计算机资源来运行这个笔记本。我们还可以共享这些笔记本,这样其他人就可以轻松地运行我们的代码,所有这些都在一个标准环境中,因为它不依赖于我们自己的本地机器。但是,在初始化期间,我们可能需要在环境中安装一些库。
谷歌Colab快速入门指南
要创建您的Google Colab文件并开始使用Google Colab,您可以访问 Google Drive并创建一个谷歌驱动器帐户(如果您没有的话)。现在,点击Google Drive页面左上角的"New"按钮,然后点击More ▷ Google Colaboratory。
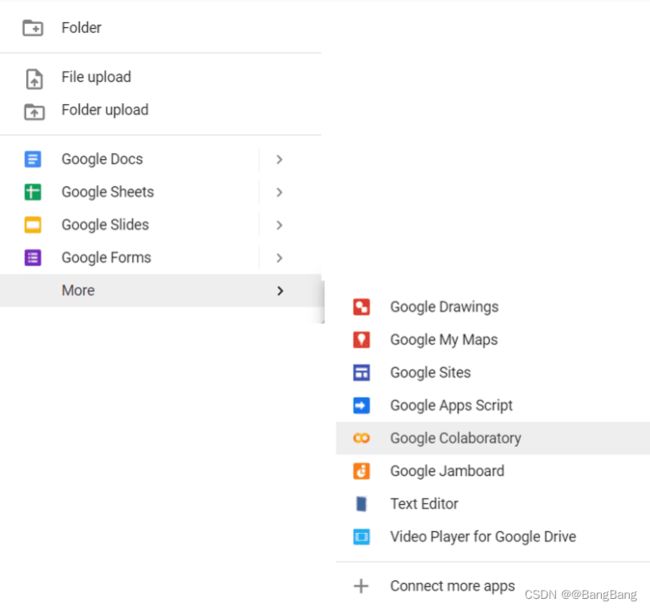
然后,就可以进入新建的Google Colab文件页面:
从这里,可以使用右上角的Share 按钮与他人共享您的谷歌Colab文件或开始编码!
Colab上的快捷键和Jupyter notebooks上的快捷键是相似的。这里介绍一些常用的:
- 运行单元格:Ctrl + Enter
- 运行cell并在下面添加新cell: Alt + Enter
- 运行cell并转到下面的cell:按Shift + Enter
- 行缩进两个空格:Ctrl +]
- 将行反缩进两个空格:Ctrl + [
但也有一个额外的非常有用的,让你只运行一个单元格中特定选择的代码部分:
- 运行单元格选定的部分:按Ctrl + Shift + Enter
就像Jupyter notebook一样,你也可以用Markdown单元格书写文本。但是Colab还有一个额外的功能,可以根据你的markdown 内容自动生成一个目录,你还可以根据标记单元格中的标题隐藏部分代码。
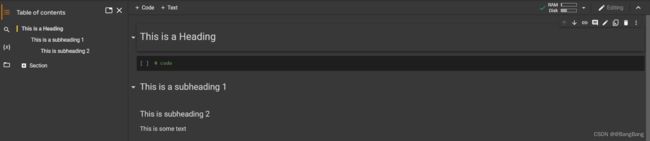
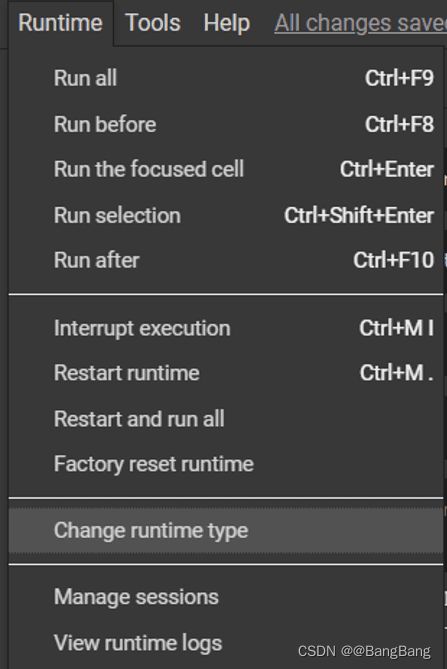
如果你在自己的电脑上运行Jupyter,你别无选择,只能使用电脑的CPU。但是在Colab中,除了cpu之外,还可以将运行时更改为包括gpu和tpu,因为它是在谷歌的云上执行的。你可以通过Runtime ▷ Change runtime type:
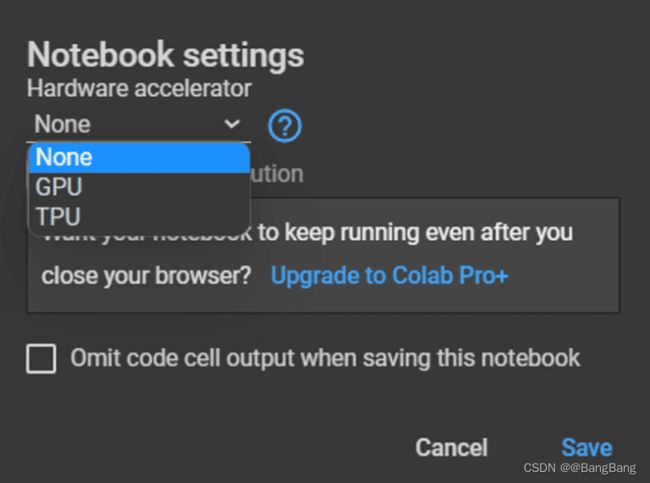
然后,您可以从不同的硬件加速器中选择来装备您的环境。
与你自己的计算机不同,Google Colab不为你提供输入命令来管理你的Python环境的终端。要安装Python库和其他程序,比如可以使用!pip install numpy(但是我们稍后会看到,Colab已经预装了很多我们需要的库,比如numpy)。
在我们已经知道了如何设置Colab环境并开始运行一些代码,让我们对环境进行一些探索吧!
使用你的 Colab 开发环境
因为我们可以运行一些shell命令!使用wget命令可能是获取数据的最简单方法。例如,运行这个将把一个CSV文件带到Colab环境中:
! wget https://raw.githubusercontent.com/jbrownlee/Datasets/master/shampoo.csv
要查看虚拟机中Colab文件的当前工作目录,请单击屏幕左侧的file图标。默认情况下,Colab提供了一个名为sample_data的目录,其中包含几个文件:
这是我们的Colab notebook的当前工作目录。你可以在Python中通过在notebook中使用如下代码来读取这些文件:
file = open("sample_data/mnist_test.csv")
稍后,我们将看到如何使用Colab扩展将我们的Google Drive挂载到这个目录,以便存储和访问Google Drive帐户上的文件。
通过使用!运行shell命令,我们还可以查看Colab环境的硬件配置。看看CPU,我们可以使用:
!cat /proc/cpuinfo
这里给出了我的环境的输出
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 63
model name : Intel(R) Xeon(R) CPU @ 2.30GHz
stepping : 0
microcode : 0x1
cpu MHz : 2299.998
cache size : 46080 KB
…
processor : 1
vendor_id : GenuineIntel
cpu family : 6
model : 63
model name : Intel(R) Xeon(R) CPU @ 2.30GHz
stepping : 0
microcode : 0x1
cpu MHz : 2299.998
cache size : 46080 KB
…
我们还可以检查运行时连接的GPU信息:
!nvidia-smi
这给出了输出,如果你有一个:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 00000000:00:04.0 Off | 0 |
| N/A 57C P8 31W / 149W | 0MiB / 11441MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
这些只是一些shell命令的示例,我们可以使用它们来探索Colab环境。还有许多其他工具,例如!pip list,用于查看Colab环境可以访问的库,标准的!ls用于查看工作目录中的文件,等等。
有用Colab扩展包
Colab还提供了许多真正有用的扩展。其中一个扩展允许我们将谷歌Drive挂载到工作目录。我们可以这样做:
import os
from google.colab import drive
MOUNTPOINT = "/content/gdrive"
DATADIR = os.path.join(MOUNTPOINT, "MyDrive")
drive.mount(MOUNTPOINT)
然后,Colab将请求访问您的Google Drive文件的权限,您可以在选择想要访问的谷歌帐户后进行此操作。在赋予它所需的权限之后,我们可以看到谷歌Google Drive挂载在左侧的Files选项卡中。
然后,要将文件写入到我们的Google Drive,可以执行以下操作:
# writes directly to google drive
with open(f"{DATADIR}/test.txt", "w") as outfile:
outfile.write("Hello World!")
这段代码编写了Hello World!转移到您的Google Drive的顶层的test.txt文件。类似地,我们也可以通过以下方式读取Google Drive中的文件:
...
with open(f"{DATADIR}/test.txt", "r") as infile:
file_data = infile.read()
print(file_data)
输出
Hello World
此外,Google Colab附带了一些扩展,以便使创建的笔记本又更好体验。如果我们经常使用pandas DataFrame,那么有一个用于显示交互表的扩展。为了使用这个函数,我们可以使用一些魔法的函数:
%load_ext google.colab.data_table
这启用了DataFrames的交互式显示,然后当我们运行:
from sklearn.datasets import fetch_openml
X = fetch_openml("diabetes", version=1, as_frame=True, return_X_y=False)["frame"]
X
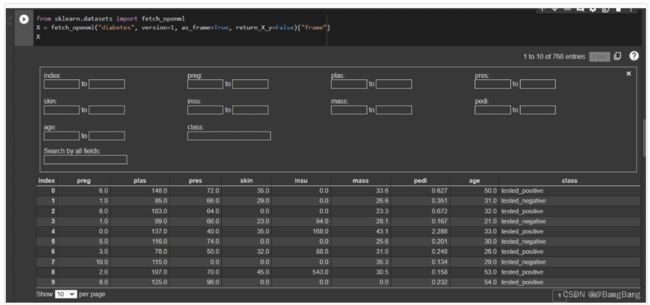
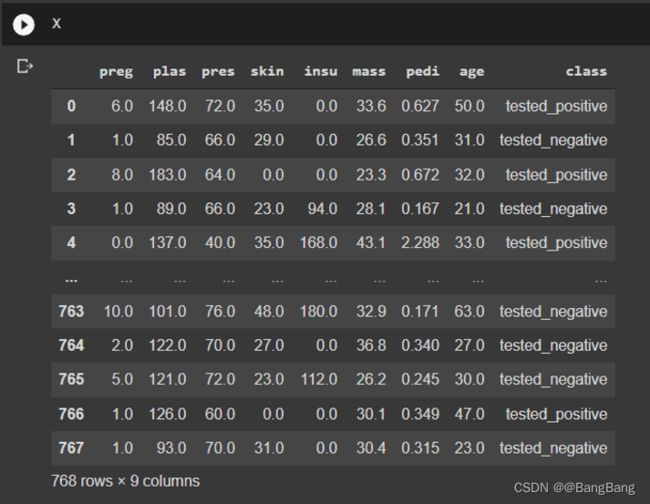
要在以后禁用这个功能,我们可以运行:
%unload_ext google.colab.data_table
当我们再次显示相同的DataFrame X时,我们得到了标准的Pandas DataFrame接口:
案例:在Google Drive上保存模型进度
Google Colab可能是为我们的机器学习项目提供强大的GPU资源的最简单的方法。但是在Colab的免费版本中,谷歌限制了我们在每个会话中使用Colab笔记本的时间。我们的内核可能会无缘无故地终止。我们可以重新开始我们的Notebook,继续我们的工作,但我们可能会失去记忆中的一切。这是一个问题,如果我们需要训练我们的模型很长时间。我们的Colab实例可能在训练完成之前终止。
使用Google Colab扩展来挂载我们的Google Drive和Keras ModelCheckpoint回调,我们可以在Google Drive上保存我们的模型进度。这对于解决Colab超时特别有用。它对付费的Pro和Pro+用户更宽松,但我们的模型训练总是有可能在中途终止。如果我们不想失去部分训练的模型,它是有价值的。
在此演示中,我们将在MNIST数据集上使用LeNet-5模型。
import tensorflow as tf
from tensorflow import keras
from keras.layers import Input, Dense, Conv2D, Flatten, MaxPool2D
from keras.models import Model
class LeNet5(tf.keras.Model):
def __init__(self):
super(LeNet5, self).__init__()
#creating layers in initializer
self.conv1 = Conv2D(filters=6, kernel_size=(5,5), padding="same", activation="relu")
self.max_pool2x2 = MaxPool2D(pool_size=(2,2))
self.conv2 = Conv2D(filters=16, kernel_size=(5,5), padding="same", activation="relu")
self.flatten = Flatten()
self.fc1 = Dense(units=120, activation="relu")
self.fc2 = Dense(units=84, activation="relu")
self.fc3=Dense(units=10, activation="softmax")
def call(self, input_tensor):
conv1 = self.conv1(input_tensor)
maxpool1 = self.max_pool2x2(conv1)
conv2 = self.conv2(maxpool1)
maxpool2 = self.max_pool2x2(conv2)
flatten = self.flatten(maxpool2)
fc1 = self.fc1(flatten)
fc2 = self.fc2(fc1)
fc3 = self.fc3(fc2)
return fc3
然后,为了在Google Drive上训练期间保存模型进度,首先,我们需要将Google Drive挂载到Colab环境中。
import os
from google.colab import drive
MOUNTPOINT = "/content/gdrive"
DATADIR = os.path.join(MOUNTPOINT, "MyDrive")
drive.mount(MOUNTPOINT)
之后,我们声明Callback以将检查点模型保存到Google Drive。
import tensorflow as tf
checkpoint_path = DATADIR + "/checkpoints/cp-epoch-{epoch}.ckpt"
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path,
save_weights_only=True,
verbose=1)
接下来,我们开始利用checkpoint callbacks训练MNIST数据集,当我们的Colab会话超时:以确保我们可以恢复在最后一个epoch
import tensorflow as tf
from tensorflow import keras
from keras.layers import Input, Dense, Conv2D, Flatten, MaxPool2D
from keras.models import Model
mnist_digits = keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist_digits.load_data()
input_layer = Input(shape=(28,28,1))
model = LeNet5()(input_layer)
model = Model(inputs=input_layer, outputs=model)
model.compile(optimizer="adam", loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics="acc")
model.fit(x=train_images, y=train_labels, batch_size=256, validation_data = [test_images, test_labels], epochs=5, callbacks=[cp_callback])
这将训练我们的模型并给出输出:
Epoch 1/5
235/235 [==============================] - ETA: 0s - loss: 0.9580 - acc: 0.8367
Epoch 1: saving model to /content/gdrive/MyDrive/checkpoints/cp-epoch-1.ckpt
235/235 [==============================] - 11s 7ms/step - loss: 0.9580 - acc: 0.8367 - val_loss: 0.1672 - val_acc: 0.9492
Epoch 2/5
229/235 [============================>.] - ETA: 0s - loss: 0.1303 - acc: 0.9605
Epoch 2: saving model to /content/gdrive/MyDrive/checkpoints/cp-epoch-2.ckpt
235/235 [==============================] - 1s 5ms/step - loss: 0.1298 - acc: 0.9607 - val_loss: 0.0951 - val_acc: 0.9707
Epoch 3/5
234/235 [============================>.] - ETA: 0s - loss: 0.0810 - acc: 0.9746
Epoch 3: saving model to /content/gdrive/MyDrive/checkpoints/cp-epoch-3.ckpt
235/235 [==============================] - 1s 6ms/step - loss: 0.0811 - acc: 0.9746 - val_loss: 0.0800 - val_acc: 0.9749
Epoch 4/5
230/235 [============================>.] - ETA: 0s - loss: 0.0582 - acc: 0.9818
Epoch 4: saving model to /content/gdrive/MyDrive/checkpoints/cp-epoch-4.ckpt
235/235 [==============================] - 1s 6ms/step - loss: 0.0580 - acc: 0.9819 - val_loss: 0.0653 - val_acc: 0.9806
Epoch 5/5
222/235 [===========================>..] - ETA: 0s - loss: 0.0446 - acc: 0.9858
Epoch 5: saving model to /content/gdrive/MyDrive/checkpoints/cp-epoch-5.ckpt
235/235 [==============================] - 1s 6ms/step - loss: 0.0445 - acc: 0.9859 - val_loss: 0.0583 - val_acc: 0.9825
从输出中,我们可以看到checkpoints已经被保存。看看我的Google Drive文件夹,我们也可以看到存储在那里的checkpoints。
Colab实例位于谷歌的云环境中。它运行的机器有一些存储空间,所以我们可以安装一个包或下载一些文件到它。但是,我们不应该将checkpoint保存在那里,因为我们不能保证在会话终止后能取回它。因此,在上面的示例中,我们将Google Drive装入实例,并将checkpoints保存在Google Drive中。这就是我们如何确保checkpoints文件是可访问的。
在这里,我们将模型训练和保存的完整代码附加到Google Drive:
import os
from google.colab import drive
import tensorflow as tf
from tensorflow import keras
from keras.layers import Input, Dense, Conv2D, Flatten, MaxPool2D
from keras.models import Model
MOUNTPOINT = "/content/gdrive"
DATADIR = os.path.join(MOUNTPOINT, "MyDrive")
drive.mount(MOUNTPOINT)
class LeNet5(tf.keras.Model):
def __init__(self):
super(LeNet5, self).__init__()
self.conv1 = Conv2D(filters=6, kernel_size=(5,5), padding="same", activation="relu")
self.max_pool2x2 = MaxPool2D(pool_size=(2,2))
self.conv2 = Conv2D(filters=16, kernel_size=(5,5), padding="same", activation="relu")
self.flatten = Flatten()
self.fc1 = Dense(units=120, activation="relu")
self.fc2 = Dense(units=84, activation="relu")
self.fc3=Dense(units=10, activation="softmax")
def call(self, input_tensor):
conv1 = self.conv1(input_tensor)
maxpool1 = self.max_pool2x2(conv1)
conv2 = self.conv2(maxpool1)
maxpool2 = self.max_pool2x2(conv2)
flatten = self.flatten(maxpool2)
fc1 = self.fc1(flatten)
fc2 = self.fc2(fc1)
fc3 = self.fc3(fc2)
return fc3
mnist_digits = keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist_digits.load_data()
# saving checkpoints
checkpoint_path = DATADIR + "/checkpoints/cp-epoch-{epoch}.ckpt"
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path,
save_weights_only=True,
verbose=1)
input_layer = Input(shape=(28,28,1))
model = LeNet5()(input_layer)
model = Model(inputs=input_layer, outputs=model)
model.compile(optimizer="adam", loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics="acc")
model.fit(x=train_images, y=train_labels, batch_size=256, validation_data = [test_images, test_labels],
epochs=5, callbacks=[cp_callback])
如果模型训练中途停止,我们可以通过重新编译模型并加载权重来继续,然后我们可以继续我们的训练:
checkpoint_path = DATADIR + "/checkpoints/cp-epoch-{epoch}.ckpt"
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path,
save_weights_only=True,
verbose=1)
input_layer = Input(shape=(28,28,1))
model = LeNet5()(input_layer)
model = Model(inputs=input_layer, outputs=model)
model.compile(optimizer="adam", loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics="acc")
# to resume from epoch 5 checkpoints
model.load_weights(DATADIR + "/checkpoints/cp-epoch-5.ckpt")
# continue training
model.fit(x=train_images, y=train_labels, batch_size=256, validation_data = [test_images, test_labels],
epochs=5, callbacks=[cp_callback])
总结
在本博客中,了解了什么Google Colab,如何利用Google Colab获得免费使用GPU,如何在Google Colab中使用 Google Drive账号,以及在Google Colab Notebook中如何保存模型和存储模型的训练checkpoints到Google Drive。
参考
“欢迎来到Colab”笔记本:https://colab.research.google.com/
jupiter Notebook文档:https://docs.jupyter.org/en/latest/