对比学习综述:Contrastive Representation Learning: A Framework and Review(2020)论文地址附文末↓
一、对比表示学习的概念及示例
1、表示学习 representation learning
指学习从原始输入数据域到特征向量或张量的参数映射的过程,希望捕获和提取更抽象和有用的概念,从而提高一系列下游任务的性能
→ 学习到在新数据样本上进行有意义的推广的映射
可根据模型建模方式or训练标签形式进行分类:
1、建模方式:
①生成式模型:通过建模数据分布p(x)来学习表示(如p(y|x))
②判别式模型:通过直接建模条件分布p(y|x)来学习表示。包括一个推断步骤,推断潜在变量p(v|x)的值,然后直接从这些推断变量p(y|v)做出下游决策
2、训练标签:
①监督学习:表示直接通过从输入映射到人类生成的标签,即训练数据对(x,y),以优化目标函数
→ 对标记数据的需求,以及耗时和昂贵,标签的主观性和隐私问题
②无监督学习:大多是生成式模型,计算昂贵,受到输入维度之间依赖关系建模能力的限制
③自监督学习:从输入数据本身的一部分生成伪标签y’(介于无监督和监督之间)
目标和评价:
对于对比表示学习,表示的质量近似于该表示分离相似和不相似的样本的程度;有时学习一个好的表示也可以是研究数据本身固有特征的有效方法,而不需要执行任何特定的任务
2、对比表示学习 contrastive representation learning
与学习映射到某些(伪)标签的鉴别模型和重构输入样本的生成模型不同,在对比学习中,通过比较输入样本来学习表示
→ 不同样本之间的比较。可以在“相似”的正输入对和“不同”的负对之间进行比较
只需要定义相似度分布,以便采样一个正输入x+~p+(·|x) 和一个负输入x-~p-(·|x)的分布
对比学习的目标:
“相似”样本的表示应该紧密地映射在一起,而“不同”样本的表示应该在嵌入空间中离得更远
3、用一个图对各分类及相关关系作总结:
左上角:无监督,生成式;右上角:监督,生成式;
左下角:自监督,判别式;右下角:监督,判别式。

4、例:基于图像的实例识别
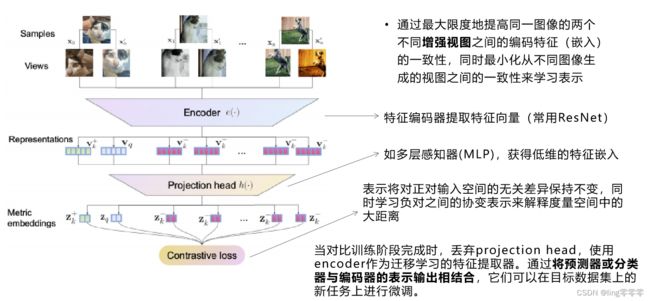
注意:正对、负对的生成方式(如本任务中的数据增强方法)对结果影响很大
在后面会详细介绍该网络结构中各部分的分类及实现。
二、对比学习中的分类
A.对比表示学习框架
提出了一个简单的框架来理解和解释对比表示学习的工作原理,将相似度匹配问题作为字典查找的一种形式

图中,q为当前采样的 query(查询目标),k+和k-分别为与q对应的正样本(相似样本)和负样本(不相似样本)。网络的最终目标是最大化正对(q和k+)之间的一致性(最小化距离),最大化负对之间的距离。
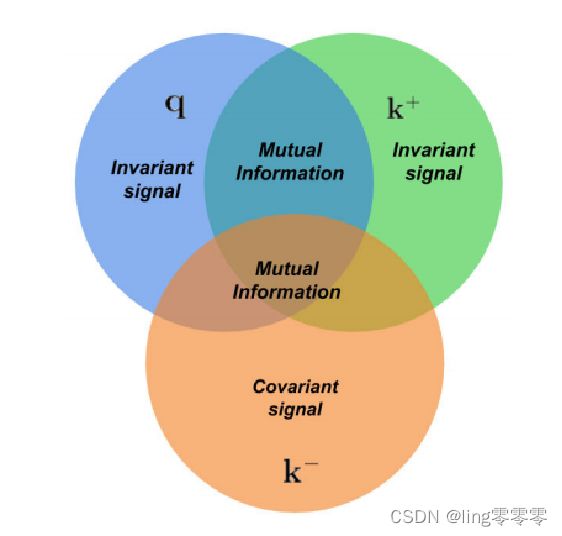
对比的方法允许通过相似性和不相似性的分布来明确所期望的不变性
B.相似性分类
1、多感官信号
利用不同传感器之间的自然对应关系,该模型可以学习到每个传感器输入中的低级细节的不变性,并专注于表示它们之间共同表达的内容

2、数据变换
通过图像增强破坏低级视觉线索,迫使对比方法学习对输入中这些变化的表示不变

3、上下文实例关系
对比局部特征与全局特征的表示可以鼓励模型学习在局部视图中出现的重要特征,而忽略只出现在这些局部输入中的噪声特征

4、序列一致性
序列中连续视图的表示被认为是一个正对,而同一序列或不同序列中的不连续和遥远的对被认为是一个负对。这种方法在表示学习中使用了慢度假设,该假设表明重要特征是在一系列观察中缓慢变化的特征。并且,视频帧的时间相干性还可以提供数据转换的自然来源

5、自然聚类
聚类是根据嵌入空间中的一些距离度量来寻找实例组特征的高级语义的过程
自然聚类是指假设不同的对象自然地与不同的分类变量相关联,其中每个类别在一个表示空间中占据一个单独的流形。不同簇之间的距离松散地表示类别之间的相似性。

C.编码器分类
1、end-to-end
queries和keys的编码器都直接使用关于对比损失函数的梯度反向传播进行更新
内存需求高 → 通常如果queries和keys具有相同的数据模式,那么它们各自的编码器通常彼此共享
2、online-offline
通过使用一个额外的离线编码器,减轻了端到端编码器将所有q和k存储在GPU内存中的内存需求
该编码器不是通过梯度下降直接在线更新,而是从在线网络来离线更新。这样,特征向量和由离线编码器计算出的隐藏激活就不会被GPU内存所限制,对比方法可以扩大批中正负对比较的数量
通常有两种方法来使用在线网络更新离线网络:
①通过使用过去的检查点checkpoint(前一个时期的在线编码器检查点作为当前时期负键的离线编码器)
②通过基于动量的加权平均(动量队列:对查询和在线编码的键保留了一组更一致的负键集)
3、pre-trained
这通常发生在跨模态学习或知识蒸馏(knowledge distillation)中,此时对比方法用于学习映射到另一个已训练好的编码器的相同表示空间。
注:在知识蒸馏设置中,使用一个预先训练的冻结权重的“教师”网络来编码keys,而一个较小的“学生”网络试图将queries表示与来自教师网络的正键匹配
D.变换头transform heads分类
将把一个或多个表示转换为一个度量嵌入,学习如何有效地计算和最大化相似性度量(和encoders结构上类似,功能上不同,故分开讨论)
如果不分开?
→ 可能导致不想出现的结果如:只关注正样本之间的相似度最大化,表示被迫丢弃潜在的有用信息
1、projection heads
作为不同向量空间之间的桥梁(如表示空间到度量空间、度量空间到另一个度量空间)
可以是一个简单的线性变换或一个非线性的MLP
2、contextualisation heads
将多个特征向量聚合到一个上下文嵌入中
与投影头只向下投影的表示法不同,上下文化的度量嵌入z具有不同的函数,并包含不同类型的信息。根据上下文信息是否有用的下游任务,上下文嵌入z实际上可以代替或与表示v一起使用。
3、quantisation heads
将多个表示映射到同一表示中,降低表示空间的复杂度
例如 wav2vec 2.0 使用Gumbel-softmax量化头将连续音频信号映射到一组离散的潜在向量(即“代码书 code book”)(连续空间量化成有限空间)
E.对比损失函数分类
在对比损失公式中,目标可以根据度量嵌入来动态定义,而不是有固定的目标。对比损失度量了潜在空间中嵌入之间的距离或相似性。
1、评分函数

(公式难打所以直接截的ppt,大家凑合一下qwq)
2、对比损失函数的实际形式(分类)
①基于能量的利益损失
将能量(距离评分)与要建模的变量的每个配置(查询向量和键向量对)联系起来。
训练包括将低能量(小距离)与变量的期望配置(正对)关联,高能量与变量的期望配置(负对)关联。

②基于概率的损失



③基于互信息的损失
旨在学习一种映射,以最大化同一场景的不同视图的表示之间的相互信息
例:InfoNCE
DIM
三、在视觉任务中的应用
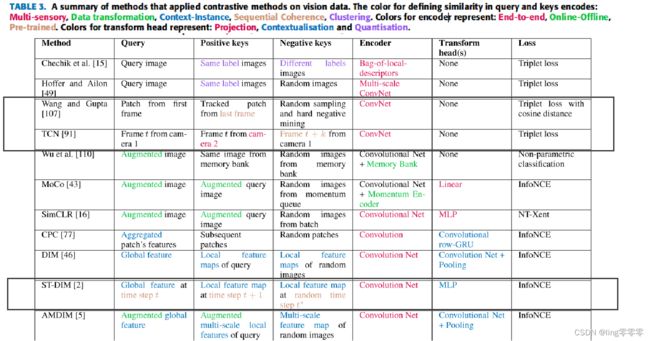

注:框出来的是在视频(帧)上使用对比学习的方法
四、作者提出的一些讨论
①从对比方法中学到什么表征,为什么它比监督预训练更好?
从实例鉴别任务来看,学习到的不变性和协变性完全由创建积极对的增强技术决定
要将对比学习应用于其他数据集和问题,必须意识到数据表示中的偏差以及产生正和负样本背后的原则
②对比损失需要更多或不需要负样本?
数量:对比学习方法的性能受益于与多个负样本的比较,这需要在大的GPU集群上进行训练和更长的训练时间;
质量:更仔细地选择负样本已经被证明可以提高学习到的嵌入在下游任务上的收敛速度和性能
这就提出了在使用负样本进行对比损失时,质量与数量权衡的问题。是否有可能设计一种对比损失,同时使用架构约束,可能用于学习的早期阶段,并在后期阶段使用硬负样本来学习更细粒度的表示?
③不同结构设计如何对对比方法表现产生影响?
在实践中,编码器和变换头的区别并不是那么明确,投影和转换头的最佳选择尚不清楚。有些情况使用变换头是必要的甚至需要用多个,有些时候不需要使用任何头,或使用线性层和非线性多层投影头即可达到最优效果
结果设计的选择通常是针对该体系结构的经验实验的结果
④应用对比学习方法预训练表示需注意的几点:
①数据集中的任何固有特征和偏差,例如,图像是否只包含一个或多个对象,这些对象是否位于中心,等等
②对下游任务的表示的期望属性,如遮挡不变性、着色不变性、时间协方差等
③对正对和负对的构造方式,使它们提供良好的学习信号并传递所期望的属性
数据的对比学习和对比表示代表了一种有趣的、不同的数据建模方法,它适合于某些类型的数据集,以及标记训练数据可能不可用或足够支持典型深度学习方法的应用程序。
论文地址:Le-Khac P H, Healy G, Smeaton A F. Contrastive representation learning: A framework and review[J]. IEEE Access, 2020, 8: 193907-193934.
论文PDF链接:Contrastive representation learning: A framework and review.pdf