机器篇——集成学习(一) 细说 Bagging 算法
返回主目录
返回集成学习目录
上一章:机器篇——决策树(六) 细说 评估指标的交叉验证
下一章:机器篇——集成学习(二) 细说 随机森林(Rondoom Forest) 算法
目录内容
机器篇——集成学习(一) 细说 Bagging 算法
机器篇——集成学习(二) 细说 随机森林(Rondoom Forest) 算法
机器篇——集成学习(三) 细说 提升(Boosting) 算法
机器篇——集成学习(四) 细说 AdaBoost 算法
机器篇——集成学习(五) 细说 梯度提升(Gradient Boost)算法
机器篇——集成学习(六) 细说 GBDT 算法
机器篇——集成学习(七) 细说 XGBoost 算法
机器篇——集成学习(八) 细说 细说 ball49_pred 项目(彩票预测)
机器篇——集成学习(九) 细说 hotel_pred 项目(酒店预测)
本小节,细说 Bagging 算法,下一小节细说 随机森林(Rondoom Forest) 算法
一. 理解
1. 定义
所谓集成学习(Ensemble Learning, EL),简单理解就是指采用多个弱分类器组成一个强分类器,然后,对数据进行预测,从而提高整体分类器的泛化能力。
2. 集成学习的方法
(1). Bagging:引导聚集算法,样本有放回抽样
(2). Rondom Forest:Bagging + Decision Tree
(3). Boosting:提升算法
(4). AdaBoost
(5). Gradient Boost
(6). GBDT
(7). XGBoost
二. 具体算法
1. Bagging 算法
(1). Bagging 算法(Boostrap aggregating, 引导聚集算法),又称为装袋算法。Bagging 算法可与其他分类、回归算法结合,提高其准确率、稳定性的同时,通过降低结果的方差,避免过拟合的发生
(2). Bagging 方法有很多种,其主要区别在于随机抽取训练子集的方法不同:
①. 如果抽取的数据集的随机子集是样例的随机子集,称为 Pasting
②. 如果样例抽取是有放回的,称为 Bagging
③. 如果抽取的数据集的随机子集是特征的随机子集,称作随机子空间(Rondom Subspaces)
④. 如果基估计器构建在对于样本和特征抽取的子集之上时,称为随机补丁(Rondom Patches)
(3). 在 sklearn 中,Bagging 方法使用同一的 BaggingClassifier 元估计器(或 BaggingRegressor),输入的参数和随机子集抽取策略由用户指定。max_samples 和 max_features 控制着子集的大小(对于样例和特征),bootstrap 和 bootstrap-features 控制着样例和特征的抽取是有放回还是无放回的。当使用样本集时,通过设置 oob_score=True,可以使用袋外(out of bag)样本评估泛化精度。
(4). 在 Bagging 中,一个样本可能被多次采样,也可能一直不被采样,假设一个样本一直不出现在采样集的概率为 ![]() ,那么对其求极限可知:
,那么对其求极限可知:
![]()
原始样本数据集中有 63.2% 的样本出现在 Bagging 使用的数据集中,同时在采样中,还可以使用带外样本(out of bagging) 来对模型的泛化精度进行评估。
(5). 最终的预测结果
①. 对于分类任务使用简单投票法,即每个分类器一票进行投票(也可以进行概率平均)
②. 对于回归任务,则采用简单平均获取最终结果,即取所有分类器的平均值。
虽然在 Bagging 中引入的随机分割增加了偏差,但是因为多个模型的集成平均,同时也使得在总体上获取了更好的模型。
(6). Bagging 算法流程
输入为样本集 ![]() ,弱学习器算法,弱分类器迭代次数
,弱学习器算法,弱分类器迭代次数  。
。
输出为最终的强分类器 
①. 对于 ![]() :
:
a. 对训练集进行第 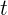 次随机采样,共采样
次随机采样,共采样  次,得到包含 个样本的采样集
次,得到包含 个样本的采样集 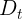 。
。
b. 用采样集 训练第 个弱学习器 ![]()
②. 如果是分类算法预测,则 个弱学习器投出最多票数的类别或者类别之一为最终类别。
如果是回归算法预测,则 个弱学习器得到的回归结果进行算术平均得到的值为最终的模型输出。
(7). bootstrapping 方法的主要过程
①. 重复地从一个样本集合  中采样
中采样  个样本。
个样本。
②. 针对每次样本的子样本集,进行统计学习,获得假设 ![]()
③. 将若干个假设进行组合,形成最终的假设 ![]()
④. 将最终的假设用于具体的分类任务
(8). Bagging 的总结
①. Bagging 通过降低基分类器的方差,改善了泛化的误差
②. 某性能依赖于基分类器的稳定。
如果基分类器不稳定,Bagging 有助于降低训练数据的随机波动导致的误差
如果稳定,则集成分类器的误差主要由基分类器的偏移引起的。
③. 由于每个样本被选中的概率是相同的,因此 Bagging 并不侧重于训练数据集中的任何特定实例。
(8). 代码演示
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# ============================================
# @Time : 2020/01/10 20:05
# @Author : WanDaoYi
# @FileName : bagging_test.py
# ============================================
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import BaggingClassifier
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import matplotlib
# 用于解决画图中文乱码
font = {"family": "SimHei"}
matplotlib.rc("font", **font)
# 加载 iris 数据
iris_info = load_iris()
# 读取 iris 的 data 数据 (x)
iris_data = pd.DataFrame(iris_info.data)
print(iris_data.head())
# 获取 data.columns 列属性名称
iris_data.columns = iris_info.feature_names
print(iris_data.columns)
# 获取 iris label 数据
label_info = iris_info.target
# 将 data 数据与 label 数据拼接 有 x 有 y 的成完整的数据。
iris_data["Species"] = label_info
print(iris_data.head())
# 读取前面的 4 列,即 x,花萼长度和宽度
x = iris_data.iloc[:, : 4]
# 读取最后 1 列,即 y,花的类别
y = iris_data.iloc[:, -1]
# 划分训练集和验证集
# train_size:训练数据比例
# random_state:随机种子,保证每次随机数据一致
x_train, x_val, y_train, y_val = train_test_split(x, y, train_size=0.7, random_state=42)
# 使用集成学习 bagging,n_estimators=20 为又放回抽样 20 次
bagging_demo = BaggingClassifier(n_estimators=20)
# 训练模型
bagging_demo.fit(x_train, y_train)
# 预测模型
y_pred = bagging_demo.predict(x_val)
acc_score = accuracy_score(y_val, y_pred)
print("acc_score: {}".format(acc_score))
plt.plot(x_val, y_val, 'r+', label='Iris-true')
plt.plot(x_val, y_pred, 'g.', label='Iris-pred')
plt.show() 

返回主目录
返回集成学习目录
上一章:机器篇——决策树(六) 细说 评估指标的交叉验证
下一章:机器篇——集成学习(二) 细说 随机森林(Rondoom Forest) 算法