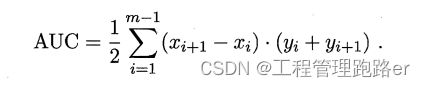西瓜书第一章第二章学习笔记
第一章:绪论
第一章主要介绍了很多概念,如下进行整理
1.基本术语
(1)=:取值为
(2)数据集:每对括号是一条记录,记录的集合就是一个数据集
(3)示例(样本)(特征向量):上网所说的记录,是对某事件和对象的描述
(4)属性(特征):反映事件或对象在某方面的表现或性质的事项
(5)属性值:属性上的取值
(6)属性空间(样本空间)(输入空间):属性张成的空间,例如三个属性,张成三个坐标轴,形成一个用于描述对象的三维空间,每个对象都能在这个三维空间里面找到对应的坐标位置
(7)训练数据:训练过程中使用的数据
(8)训练样本:训练数据中每个样本称为训练样本
(9)训练集:训练样本的集合
(10)标记:关于示例的结果信息
(11)样例:拥有结果信息的示例称为样例
(12)(xi,yi):第i个样例
(13)标记空间(输出空间):所有标记的集合
---------------------------------------------------------------------------------------------------------------------------------
(14)分类:预测离散值的学习任务;只涉及两个类别的称为二分类,一个称为正类,一个称为反类;涉及多个类别称为多分类
(15)回归:预测连续值的学习任务
(16)f:x-->y:预测对很多样例进行学习,建立一个从输入空间x到输出空间y的映射f
二分类任务令y={-1,+1} 或{0,1}
多分类任务y>2
回归任务 y=R(实数集)
---------------------------------------------------------------------------------------------------------------------------------
(17)测试:学得模型后使用其进行预测的过程
(18)测试样本:测试所预测的样本
(19)学习任务的分类:
根据训练数据是否拥有标记信息划分为监督学习(分类、回归)和无监督学习(聚类)
(20)泛化:学得模型适用于新样本的能力
2.假设空间
机器学习是一个归纳的过程,从具体归纳出一般性规律
(1)假设空间:所有假设组成的空间

(2)学习过程:对假设空间进行搜索
(3)学得结果:搜索到的假设对所有训练样本都能够进行正确判断
(4)版本空间:多个假设与训练集一致,这些假设的集合称为版本空间
3.归纳偏好
对于一个算法而言,必须产生一个模型,但是当版本空间中多个假设预测新样本时,产生了不一致的输出,这时需要偏好发挥决定作用。
例如喜欢尽可能特殊模型(适用情形尽量少)或者尽可能一般模型(适用情形尽量多)
任何一个算法必须有它的归纳偏好以产生确定的学习结果
归纳偏好:机器学习算法在学习过程中对某种类型假设的偏好
奥姆卡剃刀原则:若有若干个假设与观察一致,则选最简单的那个
第二章:模型评估与选择
1.经验误差与过拟合
(1)错误率:错误样本数占总样本数的比例
(2)精度:1-错误率
(3)误差:实际预测输出与样本的真实输出之间的差异
(4)训练误差(经验误差):学习器(模型)在训练集上的误差
(5)泛化误差:学习器在新样本上的误差
(6)过拟合:学习器把训练样本过度学习了,产生了在训练样本中是一般性质但是真正的一般性质
(7)欠拟合:训练样本中真正的一般性质尚未学好
2.评估方法
运用一个测试集测试学习器得到的测试误差,用作泛化误差的近似值。
测试集应尽量与训练集互斥(检查学习器举一反三的能力)
若只有一个数据集,又已经作为训练集了,如何创造一个测试集呢?
(1)留出法:将数据集D一分为二,S训练集和T测试集,ST互斥
数据集的划分在分布上要均匀,(例如分层采样)数量可以不
在数量上,最好是将2/3-4/5作为S,其余作为T
TIP:使用留出法一般要采用若干次随机划分、重复试验评估,最终取平均值作为结果
(2)交叉验证法
又称为k折交叉验证法,将D划分为k个大小相似的互斥子集,尽量保持分布一致。
每次用k-1个子集进行训练,1个子集进行测试,总共可以进行k次训练和测试,最终返回k次测试的均值,如下图所示:
k最常用值10,此外还有5,20等
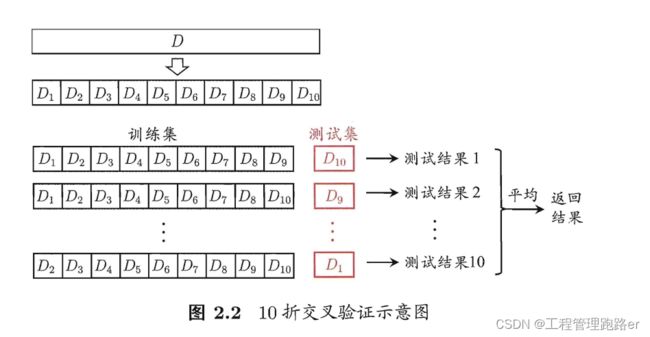
划分方式有多种,因此要进行p次划分,最终最终结果是p次验证结果的均值,常见的有10次10折交叉验证
留一法:若D有m个样本,直接令k=m,因此划分方式也只有一种;通常认为留一法的结果比较准确,缺点是面对大量数据开销大
(3)自助法:
适用于数据集小的情况
希望测试集和训练集的数据数量一样多
D':有放回的取样m次得到的训练集
D\D':D-D',初始数据中一次都没被取到的样本作为测试集
运用这种方法进行测试的结果称为外包估计
调参与最终模型
(1)验证集:模型评估与选择中用于评估测试的数据集
例如,在研究对比不同算法的泛化性能时,我们用测试
集上的判别效果来估计模型在实际使用时的泛化能力,而把训练数据另外划分
为训练集和验证集,基于验证集上的性能来进行模型选择和调参.2.性能度量
评估的标准
回归任务:均方误差
分类任务中常用的性能度量
(1)错误率与精度
错误率
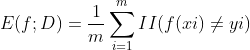
精度
![]()
(2)查准率、查全率与F1
检查有多少好的被选出来了
二分类问题可以这样分
| 真实情况 | 预测结果 | 预测结果 |
|---|---|---|
| 正例 | 反例 | |
| 正例 | TP(真正例) | FN(假反例) |
| 反例 | FP(假正例) | TN(真反例) |
查准率: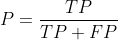 (所有预测为正的结果中,真正为正的概率)
(所有预测为正的结果中,真正为正的概率)
查全率: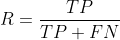 (所有预测结果中,真正为正的概率)
(所有预测结果中,真正为正的概率)
一般两个度量相互矛盾
PR曲线
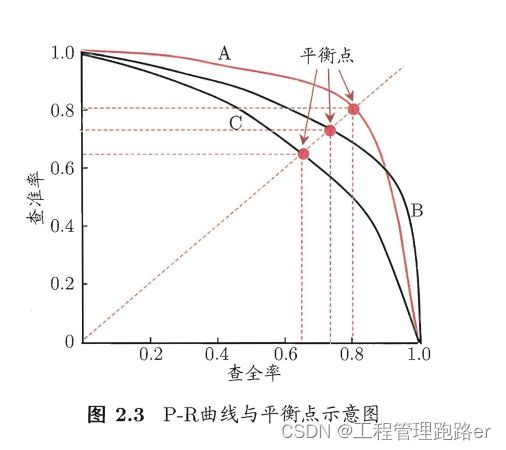
利用PR曲线来判断学习器好坏
(1)A全包C,因此A一定优于C
(2)A与B有交叉部分,可以利用围成的面积进行判断 ,但是不好计算
(3)平衡点BEP:P=R时的取值,越大越好
(4)F1度量:
基于查准率与查全率的调和平均
样例总数YLZS
![]()
(5)![]() :F1度量的一般形式,对两种度量的不同偏好
:F1度量的一般形式,对两种度量的不同偏好

多个二分类混淆矩阵,进行多次训练测试,最终希望估计算法的全局性能
两种方法:算出每一组的PR,最后平均
宏查准率、宏查全率和宏F1:

或者 用TP、FP、TN、FN用平均值去计算PR
得到微查准率、微查全率和微F1

(3)ROC与AUC
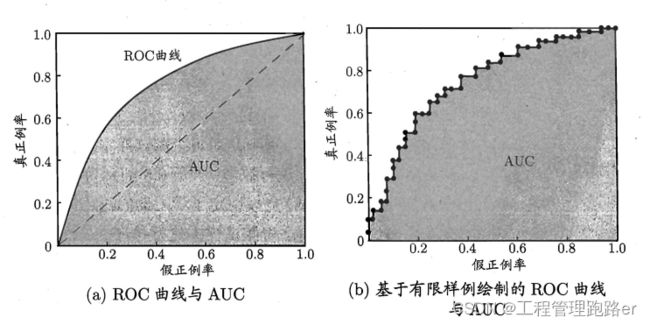
ROC 全称是"受试者工作特征" (Receiver Operating Characteristic)曲线
ROC 曲线的纵轴是"真\正例\率"(TPR),横轴是"假\正例\率",(FPR)
(FPR,TPR)

TPR:所有的真实情况为正例的被预测成正例的概率
FPR:真实情况为反例的被预测成正例的情况
利用ROC曲线与AUC示意图进行学习器优劣分析时,前两点和PR曲线图一致
当交叉,计算面积,也就是计算AUC的值