大数据HIVE---进阶
本位主要讲解大数据分析师在工作中需要用到的HIVE进阶知识,主要包括:
窗口函数
数据倾斜
性能调优
explain
替换引擎
那,就直接开讲了。
窗口函数
要讲HIVE进阶,窗口函数不得不提,作者之前的文章《Hive窗口函数进阶指南》已经很详细地讲解了这部分内容,为了省去大家点链接跳来跳去的麻烦,下面将其核心内容摘录出来,如下所示。
窗口函数也称为OLAP(OnlineAnalytical Processing)函数,是对一组值进行操作,不需要使用Group by子句对数据进行分组,还能在同一行返回原来行的列和使用聚合函数得到的聚合列。
SQL语法

如上代码所示,窗口函数的语法分为四个部分:
函数子句:指明具体操作,如sum-求和,first_value-取第一个值;
partition by子句:指明分区字段,如果没有,则将所有数据作为一个分区;
order by子句:指明了每个分区排序的字段和方式,也是可选的,没有就是按照表中的默认顺序;
窗口子句:指明相对当前记录的计算范围,可以向上(preceding),可以向下(following),也可以使用between指明,上下边界的值,没有的话默认为当前分区。有些场景比较特殊,后文会讲到这种场景。
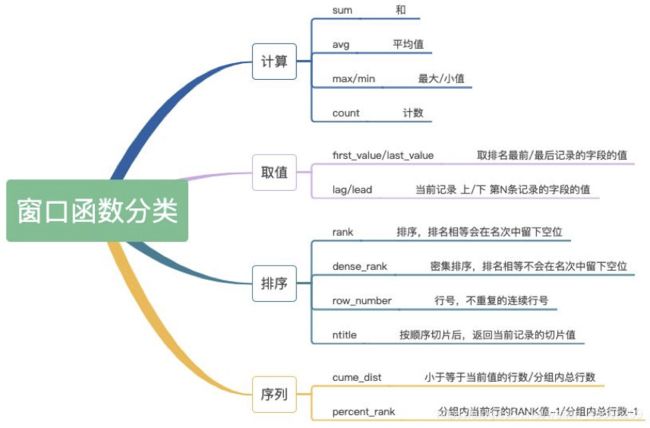
分类
按照窗口函数的功能分为:计算、取值、排序、序列四种
使用场景
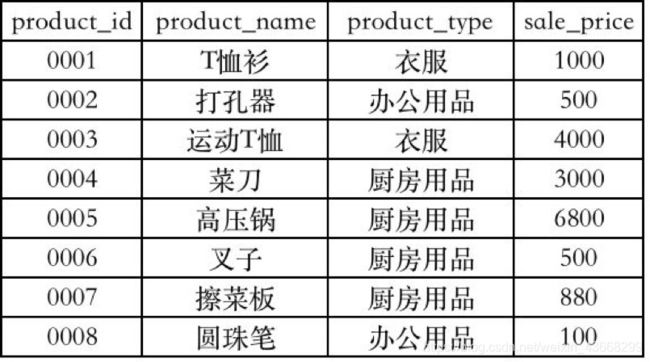
结合实际场景看看怎么用窗口函数来解决问题。下面针对不同的使用场景,将窗口函数的使用呈现给大家。
所有例子的数据均来自下图这张表。
用于辅助计算
主要的用法是在原有表的基础上,增加一列聚合后的值,辅以后续的计算。
例如:统计出不同产品类型售价最高的产品。
具体代码如下:
–使用窗口函数max
select a.product_type,a.product_name
from
(
selectproduct_name,product_type,sale_price
,max(sale_price) over
(
partitionby product_type
) as max_sale_price
–增加一列为聚合后的最高售价
fromproduct
) a
where a.sale_price = a.max_sale_price;
–保留与最高售价相同的记录数
执行结果:

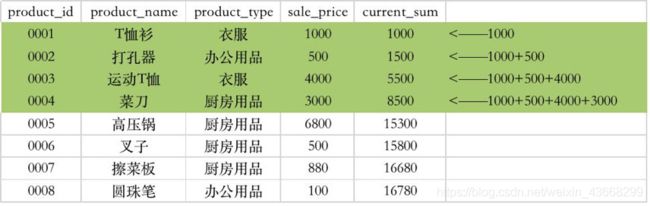
累积计算
标准聚合函数作为窗口函数配合order by使用,可以实现累积计算。
例如:sum窗口函数配合order by,可以实现累积和。
具体代码如下:
SELECT product_id,product_name
,product_type,sale_price
,SUM(sale_price) OVER
(
ORDER BYproduct_id
) AS current_sum
FROM product;
执行结果:
相应的AVG窗口函数配合order by,可以实现累积平均,max可以实现累积最大值,min可以实现累积最小值,count则可以实现累积计数。
注意,只有计算类的窗口函数可以实现累积计算。
标准聚合函数作为窗口函数使用的时候,在指明order by的情况下,如果没有Window子句,则Window子句默认为:RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW(上边界不限制,下边界到当前行)。
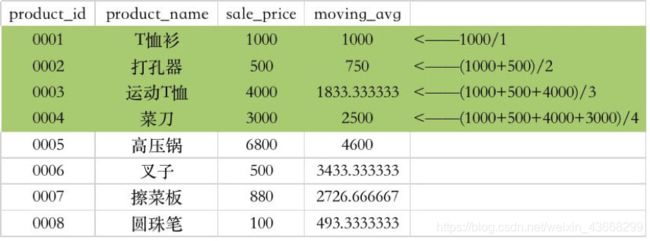
移动计算
移动计算是在分区和排序的基础上,对计算范围进一步做出限定。
例如:按照产品ID排序,将最近3条的销售价格进行汇总平均。
具体代码如下:
SELECT product_id,product_name
,sale_price
,AVG(sale_price)
over
(
ORDER BY product_id
rows 2 preceding
) AS moving_avg
FROM product;
rows 2 preceding的意思就是“截止到之前2行”。也就是将作为汇总对象的记录限定为如下的最靠近的3行。
执行结果如下:
取一字段值
取值的窗口函数有:first_value/last_value、lag/lead。
first_value(字段名)-取出分区中的第一条记录的任意一个字段的值,可以排序也可以不排序,此处也可以进一步指明Window子句。
lag(字段名,N,默认值)-取出当前行之上的第N条记录的任意一个字段的值,这里的N和默认值都是可选的,默认N为1,默认值为null。
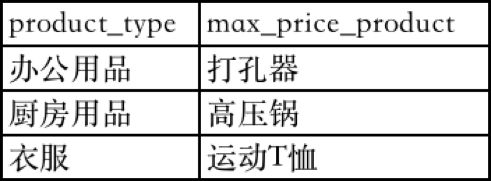
使用first_value取出每个分类下的最贵的产品,如下:
select distinct product_type
,first_value(product_name) over
(partition by product_type
order by sale_price desc) as max_price_product
from product
执行结果如下:
排序
排序对应的四个窗口函数为:rank、dense_rank、row_number、ntitle
rank:计算排序时,如果存在相同位次的记录,则会跳过之后的位次。
e.g. 有三条记录排在第1位时:1位、1位、1位、4位…
dense_rank:计算排序时,即使存在相同位次的记录,也不会跳过之后的位次。
e.g. 有三条记录排在第1位时:1位、1位、1位、2位…
row_number:赋予唯一的连续位次。
e.g. 有三条记录排在第1位时:1位、2位、3位、4位…
ntitle:用于将分组数据按照顺序切分成n片,返回当前切片值
e.g. 对于一组数字(1,2,3,4,5,6),ntile(2)切片后为(1,1,1,2,2,2)
1)统计所有产品的售价排名
具体代码如下:
SELECT product_name,product_type
,sale_price,
RANK () OVER
(
ORDER BY sale_price
) AS ranking
FROM product;
执行结果如下:

2)统计各产品类型下各产品的售价排名
具体代码如下:
SELECT product_name,product_type
,sale_price,
RANK () OVER
(
PARTITION BY product_type
ORDER BY sale_price
) AS ranking
FROM product;
执行结果如下:

对比一下dense_rank、row_number、ntile
具体代码如下:
SELECT product_name,product_type,sale_price,
RANK ()OVER (ORDER BY sale_price) AS ranking,
DENSE_RANK () OVER (ORDER BY sale_price) AS dense_ranking,
ROW_NUMBER () OVER (ORDER BY sale_price) AS row_num,
ntile(3)OVER (ORDER BY sale_price) as nt1,
ntile(30)OVER (ORDER BY sale_price) as nt2
–切片大于总记录数
FROM product;
执行结果如下:

从结果可以发现,当ntile(30)中的切片大于了总记录数时,切片的值为记录的序号。
序列
序列中的两个窗口函数cume_dist和percent_rank,通过实例来看看它们是怎么使用的。
1)统计小于等于当前售价的产品数,所占总产品数的比例
具体代码如下:
SELECT product_type,product_name,sale_price,
CUME_DIST() OVER(ORDER BY sale_price) AS rn1,
CUME_DIST() OVER
(
PARTITIONBY product_type
ORDER BYsale_price
) AS rn2
FROM product;
执行结果如下:
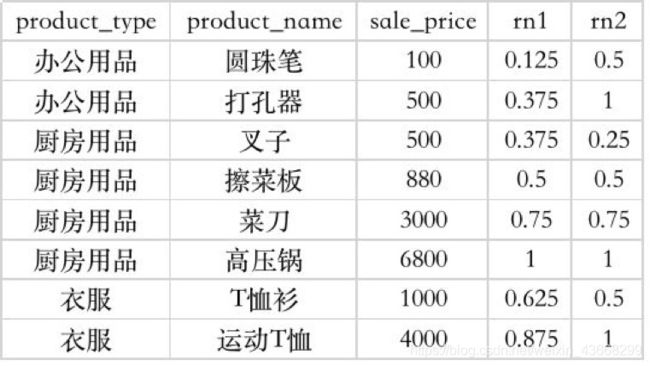
rn1: 没有partition,所有数据均为1组,总行数为8,
第一行:小于等于100的行数为1,因此,1/8=0.125
第二行:小于等于500的行数为3,因此,3/8=0.375
rn2: 按照产品类型分组,product_type=厨房用品的行数为4,
第三行:小于等于500的行数为1,因此,1/4=0.25
2)统计每个产品的百分比排序
当前行的RANK值-1/分组内总行数-1
具体代码如下:
SELECT product_type,product_name,sale_price,
percent_rank() OVER (ORDER BY sale_price) AS rn1,
percent_rank() OVER
(
PARTITIONBY product_type
ORDER BYsale_price
) AS rn2
FROM product;
执行结果如下:
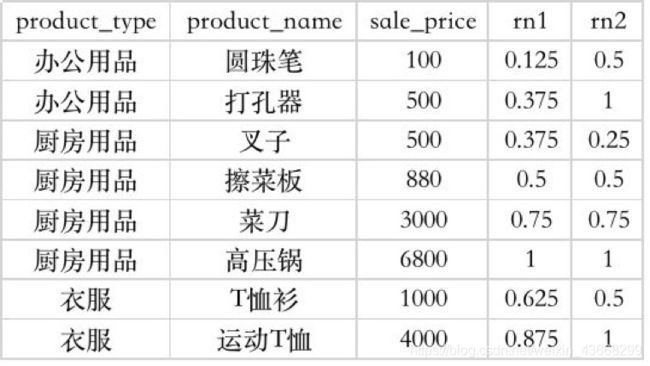
rn1: 没有partition,所有数据均为1组,总行数为8,
第一行:排序为1,因此,(1-1)/(8-1)= 0
第二行:排序为2,因此,(2-1)/(8-1)= 0.14
rn2: 按照产品类型分组,product_type=厨房用品的行数为4,
第三行:排序为1,因此,(1-1)/(4-1)= 0
第四行:排序为1,因此,(2-1)/(4-1)= 0.33
数据倾斜
什么是数据倾斜
数据倾斜就是数据的分布不平衡,某些地方特别多,某些地方又特别少,导致在处理数据的时候,有些很快就处理完了,而有些又迟迟未能处理完,导致整体任务最终迟迟无法完成,这种现象就是数据倾斜。
针对mapreduce的过程来说主要表现是:任务进度长时间维持在 99%或者 100%的附近,查看任务监控页面,发现只有少量 reduce 子任务未完成,因为其处理的数据量和其他的 reduce 差异过大。单一 reduce 处理的记录数和平均记录数相差太大,通常达到好几倍之多,最长时间远大于平均时长。
哪些操作容易造成数据倾斜?

产生数据倾斜的原因
结合数据倾斜的场景,可以总结出产生数据倾斜的原因
- key 分布不均匀
- 业务数据本身的特性
- 建表考虑不周全,如partition的数量过少
- 某些 HQL 语句本身就容易产生数据倾斜,如join
优化方法
既然已经知道了哪些情况可能会产生数据倾斜以及产生数据倾斜的原因,那么如何去规避数据倾斜问题呢?
下面结合具体的场景来说说
特殊值产生的数据倾斜
在日志中,常会有字段值丢失的问题,比如日志中的 user_id,如果取其中的 user_id 和用户表中的 user_id 相关联,就会碰到数据倾斜的问题。
解决方案 1:user_id 为空的不参与关联
select *
from log a join user b
on a.user_id is not null and a.user_id = b.user_id
union all
select *
from log c
where c.user_id is null;
解决方案 2:赋予空值新的 key 值
select *
from log a left outer join user b
on case when a.user_id is null thenconcat(‘null_’,rand()) else a.user_id end = b.user_id
方法 2 比方法 1 效率更好,不但 IO 少了,而且作业数也少了。
方案 1 中,log 表 读了两次,job数肯定是 2,而方案 2 job数是 1。
方法 2 使本身为 null 的所有记录不会拥挤在同一个 reduceTask 了,加上随机字符串值,会分散到了多个 reduceTask 中,由于 null 值关联不上,处理后并不影响最终结果。
大小表关联查询产生数据倾斜
对于这种数据倾斜一般的做法是使用MapJoin-将其中做连接的小表(全量数据)分发到所有 MapTask 端进行 Join,从而避免了 reduceTask,前提要求是内存足以装下该全量数据。
以大表 a 和小表 b 为例,所有的 maptask 节点都装载小表 b 的所有数据,然后大表 a 的 一个数据块数据比如说是 a1 去跟 b 全量数据做链接,就省去了 reduce 做汇总的过程。
所以相对来说,在内存允许的条件下使用 map join 比直接使用 MapReduce 效率还高些, 当然这只限于做 join 查询的时候。
其实对于多表join,是否开启MapJoin,可以进行设置的,具体参数如下:
set hive.auto.convert.join=true; //设置 MapJoin 优化自动开启
set hive.mapjoin.smalltable.filesize=25000000 //设置小表不超过多大时开启 mapjoin 优化
也可以人为指定开启MapJoin,请看下面的代码:
select /* +mapjoin(b) */ a.id aid, name, age
from a join b
on a.id = b.id;
因为加了/* +mapjoin(b) */这一段代码,执行的时候就会将b表读入内存中,但是要求b表必须是小表,数据量不能太大。
性能调优
由于Hive的执行依赖于底层的MapReduce作业,因此对MapReduce作业的调整优化是提高Hive性能的基础。所以可以从以下几个方面进行一系列的调优,来大幅度地提高Hive的查询性能。
启用压缩
在Hive中对中间数据或最终数据做压缩,是提高数据吞吐量和性能的一种手段。对数据做压缩,可以大量减少磁盘的存储空间,比如基于文本的数据文件,可以将文件压缩40%或更多。同时压缩后的文件在网络间传输I/O也会大大减少;当然压缩和解压缩也会带来额外的CPU开销,但是却可以节省更多的I/O和使用更少的内存开销。
常见的压缩方式有:GZIP、BZIP2、LZO、Snappy等。
那这么多种压缩方式,使用哪一种呢?可以通过压缩比、压缩速度、是否可分割来决定选哪一种,压缩比和压缩速度都好理解,是否可分割是指压缩后的文件是否可以再分割:可以分割的格式允许单一文件由多个Mapper程序同时读取,可以做到更好的并行化。
下表是各种压缩方式的对比:

如何设置
前文有提到在Hive中对中间数据或最终数据做压缩,那分别来看看如何设置。
中间数据压缩
set hive.exec.compress.intermediate=true
set mapred.map.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec
hive.exec.compress.intermediate:默认该值为false,设置为true为激活中间数据压缩功能。HiveQL语句最终会被编译成Hadoop的Mapreduce job,开启Hive的中间数据压缩功能,就是在MapReduce的shuffle阶段对mapper产生的中间结果数据压缩。在这个阶段,优先选择一个低CPU开销的算法。
mapred.map.output.compression.codec:该参数是具体的压缩算法实现类的配置参数,SnappyCodec是比较适合这种场景的编解码器,该算法会带来很好的压缩比和较低的CPU开销。
最终数据压缩
set hive.exec.compress.output=true
setmapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec
hive.exec.compress.output:该参数控制最终数据压缩的激活与禁用,设置为true来声明将结果文件进行压缩。
mapred.output.compression.codec:选择一个合适的编解码器,如选择SnappyCodec。
避免全局排序
Hive中使用order by子句实现全局排序。order by只用一个Reducer产生结果,对于大数据集,这种做法效率很低。
如果不需要全局有序,则可以使用sort by子句,该子句为每个reducer生成一个排好序的文件。如果需要控制一个特定数据行流向哪个reducer,可以使用distribute by子句,例如:
select id, name, salary, dept
from employee
distribute by dept
sort by id asc, name desc;
属于一个dept的数据会分配到同一个reducer进行处理,同一个dept的所有记录按照id、name列排序。最终的结果集是局部有序的。
优化limit操作
默认时limit操作仍然会执行整个查询,然后返回限定的行数。在有些情况下这种处理方式很浪费,因此可以通过设置下面的属性避免此行为。

说明:
hive.limit.optimize.enable:是否启用limit优化。当使用limit语句时,对源数据进行抽样。
hive.limit.row.max.size:在使用limit做数据的子集查询时保证的最小行数据量。
hive.limit.optimize.limit.file:在使用limit做数据子集查询时,采样的最大文件数。
hive.limit.optimize.fetch.max:使用简单limit数据抽样时,允许的最大行数。
启用并行
每条HiveQL语句都被转化成一个或多个执行阶段,可能是一个MapReduce阶段、采样阶段、归并阶段、限制阶段等。默认时,Hive在任意时刻只能执行其中一个阶段。
如果组成一个特定作业的多个执行阶段是彼此独立的,那么它们可以并行执行,从而整个作业得以更快完成。通过设置下面的属性启用并行执行。

说明:
hive.exec.parallel:是否并行执行作业。
hive.exec.parallel.thread.number:最多可以并行执行的作业数。
启用MapReduce严格模式
Hive提供了一个严格模式,可以防止用户执行那些可能产生负面影响的查询。通过设置下面的属性启用MapReduce严格模式。
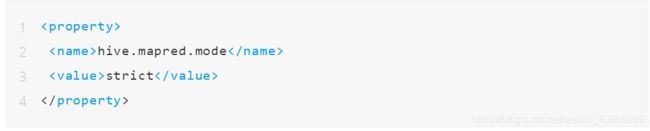
严格模式禁止3种类型的查询:
1)对于分区表,where子句中不包含分区字段过滤条件的查询语句不允许执行。
2)对于使用了order by子句的查询,要求必须使用limit子句,否则不允许执行。
3)限制笛卡尔积查询。
控制并行Reduce任务
Hive通过将查询划分成一个或多个MapReduce任务达到并行的目的。确定最佳的mapper个数和reducer个数取决于多个变量,例如输入的数据量以及对这些数据执行的操作类型等。
如果有太多的mapper或reducer任务,会导致启动、调度和运行作业过程中产生过多的开销,而如果设置的数量太少,那么就可能没有充分利用好集群内在的并行性。对于一个Hive查询,可以设置下面的属性来控制并行reduce任务的个数。

说明:
hive.exec.reducers.bytes.per.reducer:每个reducer的字节数,默认值为256MB。Hive是按照输入的数据量大小来确定reducer个数的。例如,如果输入的数据是1GB,将 使用4个reducer。
hive.exec.reducers.max:将会使用的最大reducer个数。
启用向量化
向量化特性在Hive 0.13.1版本中被首次引入。通过查询执行向量化,使Hive从单行处理数据改为批量处理方式,具体来说是一次处理1024行而不是原来的每次只处理一行,这大大提升了指令流水线和缓存的利用率,从而提高了表扫描、聚合、过滤和连接等操作的性能。可以设置下面的属性启用查询执行向量化。

说明:
hive.vectorized.execution.enabled:如果该标志设置为true,则开启查询执行的向量模式,默认值为false。
hive.vectorized.execution.reduce.enabled:如果该标志设置为true,则开启查询执行reduce端的向量模式,默认值为true。
hive.vectorized.execution.reduce.groupby.enabled:如果该标志设置为true,则开启查询执行reduce端groupby操作的向量模式,默认值为true。
启用基于成本的优化器
Hive 0.14版本开始提供基于成本优化器(CBO)特性。使用过Oracle数据库的读者对CBO一定不会陌生。与Oracle类似,Hive的CBO也可以根据查询成本制定执行计划,例如确定表连接的顺序、以何种方式执行连接、使用的并行度等。设置下面的属性启用基于成本优化器。

说明:
hive.cbo.enable:控制是否启用基于成本的优化器,默认值是true。Hive的CBO使用Apache Calcite框架实现。
hive.compute.query.using.stats:该属性的默认值为false。如果设置为true,Hive在执行某些查询时,例如select count(1),只利用元数据存储中保存的状态信息返回结果。 为了收集基本状态信息,需要将hive.stats.autogather属性配置为true。为了收集更多的状态信息,需要运行analyze table查询命令,例如下面的语句收集sales_order_fact表的统计信息。
analyze table
sales_order_fact compute statistics
for
columns;
hive.stats.fetch.partition.stats:该属性的默认值为true。操作树中所标识的统计信息,需要分区级别的基本统计,如每个分区的行数、数据量大小和文件大小等。分区统计信息从元数据存储中获取。如果存在很多分区,要为每个分区收集统计信息可能会消耗大量的资源。这个标志可被用于禁止从元数据存储中获取分区统计。当该标志设置为false时,Hive从文件系统获取文件大小,并根据表结构估算行数。
hive.stats.fetch.column.stats:该属性的默认值为false。操作树中所标识的统计信息,需要列统计。列统计信息从元数据存储中获取。如果存在很多列,要为每个列收 集统计信息可能会消耗大量的资源。这个标志可被用于禁止从元数据存储中获取列统计。
EXPLAIN
explain-解释计划,通过explain命令可以知道hive将会如何执行所写的查询语句,需要注意的是查询语句并没有执行哦,只是告诉你将会怎么样执行。
这对于HIVE SQL的调优是很重要的,一个复杂的SQL如果执行的时间过长,可以根据解释计划来看具体执行的步骤,进而找到可以优化的地方。
下面就结合例子看看如何查看解释计划,代码中的注释部分是要重点关注的。
EXPLAIN
select student,sum(score)
FROM test.class
GROUP BY student
执行上述的代码:
Explain
Plan optimized by CBO.
–CBO是打开的,计划基于CBO优化
Vertex dependency in root stage
Reducer 2 <- Map 1 (SIMPLE_EDGE)
–简单的依赖关系,一个Map2个Reducer
Stage-0
Fetch Operator
limit:-1
Stage-1
Reducer 2
File Output Operator [FS_6]
Group By Operator[GBY_4] (rows=9 width=16) --reducer端的聚合
Output:["_col0","_col1"],aggregations:[“sum(VALUE._col0)”],keys:KEY._col0
<-Map 1 [SIMPLE_EDGE]//发生在job的 map 处理阶段过程
SHUFFLE [RS_3]
PartitionCols:_col0
Group ByOperator [GBY_2] (rows=18 width=16) --map端的聚合
Output:["_col0","_col1"],aggregations:[“sum(score)”],keys:student
Select Operator [SEL_1] (rows=18 width=16)
Output:[“student”,“score”]
TableScan [TS_0] (rows=18 width=16) --读取表的数据
test@class,class,Tbl:COMPLETE,Col:NONE,Output:[“student”,“score”]
上述打印的就是解释计划,主要关注的是Stage部分,需要注意的是这一部分是从下往上进行查看的,最先查看到的是读取表的数据(18条记录)及选取的字段,然后可以看出在Map端先做了一次聚合,然后在recucer端又进行了一次聚合。
EXPLAIN后面可以加不同关键字来针对性的查看,DEPENDENCY|AUTHORIZATION在实际工作中比较常用,我们着重介绍下这两个关键字。
DEPENDENCY
EXPLAIN DEPENDENCY
select *
FROM test.test_view --是一个测试视图
Explain
{“input_tables”:[{“tablename”:“test@test_view”,“tabletype”:“VIRTUAL_VIEW”},{“tablename”:“test@product”,“tabletype”:“MANAGED_TABLE”,“tableParents”:"[test@test_view]"}],“input_partitions”:[]}

EXPLAIN DEPENDENCY用于描述整个sql需要依赖的输入数据,为了直观的看出它的结构,我将输出的JSON格式化后展开如上图所示:分为两部分input_tables和input_partitions,顾名思义就是输入的表和分区, 实际运用场景:
1)排错,排查某个程序可能在运行过程略过了某个分区
2)理清程序依赖的表的输入,理解程序的运行,特别是理解在俩表join的情况下的依赖输入
3)查看视图的实际数据来源
AUTHORIZATION
Explain
INPUTS:
test@class
OUTPUTS:
hdfs://hans/tmp/hive/spark/da7f94b3-b9e2-46f1-8bee-8a367f62a753/hive_2019-05-30_10-58-00_447_6351031319937169270-1/-mr-10001
CURRENT_USER:
spark
OPERATION:
QUERY
AUTHORIZATION_FAILURES:
Permission denied: Principal [name=spark,type=USER] does not have following privileges for operation QUERY [[SELECT] onObject [type=TABLE_OR_VIEW, name=test.class]]
用来表达CURRENT_USER的用户对哪些INPUTS有读操作,对哪些OUTPUTS有写操作。
上面的解释计划是spark的用户,读取test@class的数据,查询出来的结果会暂时存放到hdfs://hans/tmp/hive/spark/da7f94b3-b9e2-46f1-8bee-8a367f62a753/hive_2019-05-30_10-58-00_447_6351031319937169270-1/-mr-10001文件中。
替换引擎
为什么要替换
HIVE的默认执行引擎是MapReduce,MapReduce是一种离线计算框架,将一个算法抽象成Map和Reduce两个阶段进行处理,每个阶段都是用键值对(key/value)作为输入和输出,非常适合数据密集型计算。
但是缺点也很明显,最直观的感受就是执行时间长,它在计算时会对磁盘进行多次的读写操作,这样启动多轮job的代价略有些大,不仅占用资源,更耗费大量的时间。
本篇前面在性能调优部分,所讲解的优化措施就是针对MapReduce的,如果现在有另外一个引擎可以代替MapReduce并且自带优化策略,你换不换?
替换成什么?
目前的主流选择是Tez,Tez是Apache开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。
总结起来,Tez在执行绩效上有以下特点:
(1)比MapReduce更好的性能提升
(2)最佳资源管理
(3)运行中重新配置计划
(4)动态物理数据流决策
从上面Tez的介绍来看,Tez的确有很多优点。
下面我们单单从执行过程来看,传统的MR(包括Hive,Pig和直接编写MR程序),假设有四个有依赖关系的MR作业(1个较为复杂的Hive SQL语句或者Pig脚本可能被翻译成4个有依赖关系的MR作业),运行过程如下(其中,绿色是Reduce Task,需要写HDFS;云状表示写屏蔽(write barrier,一种内核机制,持久写);绿色的圆圈代表一个job):
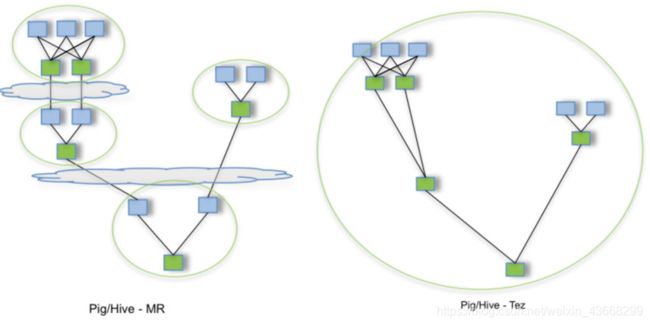
MR需要4个job来完成计算,而Tez可以将多个有依赖的作业转换为一个作业(这样只需写一次HDFS,且中间节点较少),从而大大提升DAG作业的性能。
怎么替换
肯定是要先安装起来,这里就不具体说明怎么安装了,网上相关的文章很多。安装好了之后,只需对hive-site.xml中修改如下配置:

看到这里,大家可以去查看下自己的工作或者学习的HIVE平台的引擎是什么,如何还是mr建议换掉,在hive的命令行输入下面的代码,即可查看。
set hive.execution.engine;
总结
本篇HIVE进阶讲述的内容,可能在实际工作中不是全部很常用,但是对于更高效的利用HIVE、写出高效和简洁的HIVE SQL代码、程序调错调优是非常重要的,所以掌握这些知识无疑是提升工作效率的一剂良药。
参考文献:
[1] 比MR至少快5倍的神器,竟然是它,作者:巩传捷@中兴大数据 -https://www.sohu.com/a/131167936_465944
[2] MapReduce和Tez对比,作者:凌度 - https://www.cnblogs.com/linn/p/5325147.html
[3] 数据倾斜及处理,作者:火山Vol -https://www.jianshu.com/p/42be5ca8b11d
[4] Hive学习之路 (十九)Hive的数据倾斜,作者:扎心了,老铁 - https://www.cnblogs.com/qingyunzong/p/8847597.html
[5] Hive压缩设置,作者:djd已经存在 - https://blog.csdn.net/djd1234567/article/details/51581354
[6] Hive的Explain命令,作者:skyl夜 -https://www.cnblogs.com/skyl/p/4737411.html
[7] Tez官网 - http://tez.apache.org/
转载至:人工智能与大数据群