PyTorch internals
PyTorch internals
This post is a long form essay version of a talk about PyTorch internals, that I gave at the PyTorch NYC meetup on May 14, 2019.
这篇文章是我在2019年5月14日于PyTorch纽约市见面会上发表的有关PyTorch内部原理的长篇论文版本。

Hi everyone! Today I want to talk about the internals of PyTorch.

This talk is for those of you who have used PyTorch, and thought to yourself, “It would be great if I could contribute to PyTorch,” but were scared by PyTorch’s behemoth of a C++ codebase. I’m not going to lie: the PyTorch codebase can be a bit overwhelming at times. The purpose of this talk is to put a map in your hands: to tell you about the basic conceptual structure of a “tensor library that supports automatic differentiation”, and give you some tools and tricks for finding your way around the codebase. I’m going to assume that you’ve written some PyTorch before, but haven’t necessarily delved deeper into how a machine learning library is written.
这次演讲的对象是那些曾经使用过PyTorch并想:“如果我能为PyTorch做出贡献,那就太好了,”但是却被PyTorch的C++代码库庞然大物所吓倒的人。我不会撒谎:PyTorch代码库有时可能会让人有些不知所措。本演讲的目的是为您提供一幅地图:向您介绍“支持自动微分的张量库”的基本概念结构,并为您提供一些在代码库中寻找你的方式的工具和技巧。我将假设您之前已经编写了一些PyTorch代码,但还没有深入研究如何编写机器学习库。

The talk is in two parts: in the first part, I’m going to first introduce you to the conceptual universe of a tensor library. I’ll start by talking about the tensor data type you know and love, and give a more detailed discussion about what exactly this data type provides, which will lead us to a better understanding of how it is actually implemented under the hood. If you’re an advanced user of PyTorch, you’ll be familiar with most of this material. We’ll also talk about the trinity of “extension points”, layout, device and dtype, which guide how we think about extensions to the tensor class. In the live talk at PyTorch NYC, I skipped the slides about autograd, but I’ll talk a little bit about them in these notes as well.
演讲分为两个部分:在第一部分中,我将首先向您介绍张量库的概念图。我将从谈论您知道和喜欢的张量数据类型开始,然后更详细地讨论该数据类型提供的确切内容,这将使我们更好地了解它是如何在后台实际实现的。
如果您是PyTorch的高级用户,那么您将熟悉这些材料中的大多数。我们还将讨论“扩展点”:布局、设备和dtype的三位一体性,它们指导我们如何考虑对张量类的扩展。在PyTorch纽约的现场演讲中,我跳过了有关自动求导的幻灯片,但我也会在这些笔记中对它们进行一些讨论。
The second part grapples with the actual nitty gritty details involved with actually coding in PyTorch. I’ll tell you how to cut your way through swaths of autograd code, what code actually matters and what is legacy, and also all of the cool tools that PyTorch gives you for writing kernels.
第二部分介绍了在PyTorch中实际编码所涉及的实际细节。我将告诉您如何穿过大量autograd代码,什么是真正重要的代码和遗留的东西,以及PyTorch提供的所有酷炫的内核编写工具。


The tensor is the central data structure in PyTorch. You probably have a pretty good idea about what a tensor intuitively represents: its an n-dimensional data structure containing some sort of scalar type, e.g., floats, ints, et cetera. We can think of a tensor as consisting of some data, and then some metadata describing the size of the tensor, the type of the elements in contains (dtype), what device the tensor lives on (CPU memory? CUDA memory?)
张量是PyTorch中的中心数据结构。您可能对张量直观地表示什么有一个很好的想法:它是一个n维数据结构,其中包含某种标量类型,例如浮点数,整数等。我们可以认为张量由一些数据组成,然后由一些元数据描述张量的大小、包含元素的类型(dtype)、张量驻留在哪个设备上(CPU内存或CUDA内存)。

There’s also a little piece of metadata you might be less familiar with: the stride. Strides are actually one of the distinctive features of PyTorch, so it’s worth discussing them a little more.
还有一些您可能不太熟悉的元数据:步长。步长实际上是PyTorch的独特功能之一,因此值得对它们进行更多的讨论。

A tensor is a mathematical concept. But to represent it on our computers, we have to define some sort of physical representation for them. The most common representation is to lay out each element of the tensor contiguously in memory (that’s where the term contiguous comes from), writing out each row to memory, as you see above. In the example above, I’ve specified that the tensor contains 32-bit integers, so you can see that each integer lies in a physical address, each offset four bytes from each other. To remember what the actual dimensions of the tensor are, we have to also record what the sizes are as extra metadata.
张量是一个数学概念。但是要在我们的计算机上表示它,我们必须为它们定义某种物理表示。最常见的表示方法是将张量的每个元素连续放置在内存中(这是术语“连续”的来源),将每一行写到内存中,如您在上面看到的。
在上面的示例中,我指定了张量包含32位整数,因此您可以看到每个整数都位于一个物理地址中,每个地址彼此偏移四个字节。为了记住张量的实际尺寸,我们还必须记录尺寸大小,作为额外的元数据。
So, what do strides have to do with this picture?
步长与这张图片有什么关系呢?

Suppose that I want to access the element at position tensor[0, 1] in my logical representation. How do I translate this logical position into a location in physical memory? Strides tell me how to do this: to find out where any element for a tensor lives, I multiply each index with the respective stride for that dimension, and sum them all together. In the picture above, I’ve color coded the first dimension blue and the second dimension red, so you can follow the index and stride in the stride calculation. Doing this sum, I get two (zero-indexed), and indeed, the number three lives two below the beginning of the contiguous array.
假设我要在我的逻辑表示形式中访问tensor[0,1]位置上的元素。如何将此逻辑位置转换为物理内存中的位置?
步长告诉我如何执行此操作:要找出张量的任何元素在哪里,我将每个索引与该维度的步长相乘,然后将它们加在一起。在上面的图片中,我已经对第一维蓝色和第二维红色进行了颜色编码,因此您可以遵循索引并在步幅计算中迈步。这样做的总和,我得到2(地址从0开始),实际上,数字3在连续数组的开始位置的后移两个。
(Later in the talk, I’ll talk about TensorAccessor, a convenience class that handles the indexing calculation. When you use TensorAccessor, rather than raw pointers, this calculation is handled under the covers for you.)
(稍后,我将讨论TensorAccessor,这是一个处理索引计算的便捷类。当您使用TensorAccessor而不是原始指针时,该计算将在您的幕后进行。)
Strides are the fundamental basis of how we provide views to PyTorch users. For example, suppose that I want to extract out a tensor that represents the second row of the tensor above:
步长是我们向PyTorch用户提供视图的基础。例如,假设我要提取出一个张量,该张量表示上述张量的第二行:

Using advanced indexing support, I can just write tensor[1, :] to get this row. Here’s the important thing: when I do this, I don’t create a new tensor; instead, I just return a tensor which is a different view on the underlying data. This means that if I, for example, edit the data in that view, it will be reflected in the original tensor. In this case, it’s not too hard to see how to do this: three and four live in contiguous memory, and all we need to do is record an offset saying that the data of this (logical) tensor lives two down from the top. (Every tensor records an offset, but most of the time it’s zero, and I’ll omit it from my diagrams when that’s the case.)
采用先进的索引支持,我可以只写Tensor[1,:]来获得此行。重要的是:当我这样做时,我没有创建一个新的张量; 相反,我返回的张量其实是在背后数据不同的视角。这意味着如果我想编辑该视图中的数据,将在原来的张量上修改。在这种情况下,不难发现如何执行此操作:3和4位于连续内存中,我们要做的就是记录一个偏移量,说该(逻辑)张量的数据位于顶部向下两个位置。(每个张量都记录一个偏移量,但大多数情况下它是零,在这种情况下,我将在图表中忽略它。)
Question from the talk: If I take a view on a tensor, how do I free the memory of the underlying tensor?
Answer: You have to make a copy of the view, thus disconnecting it from the original physical memory. There’s really not much else you can do. By the way, if you have written Java in the old days, taking substrings of strings has a similar problem, because by default no copy is made, so the substring retains the (possibly very large string). Apparently, they fixed this in Java 7u6.
观众的问题:如果查看张量,如何释放基础张量的内存?
答案:你必须制作一个视图的副本断开与原物理内存的联系。您实际上无能为力。顺便说一句,如果您以前写过Java,则采用字符串的子字符串也会遇到类似的问题,因为默认情况下不会进行复制,因此子字符串会保留(可能是非常大的字符串)。显然,他们在Java 7u6中修复了此问题。
A more interesting case is if I want to take the first column:
一个更有趣的情况是,如果我想读第一列:

When we look at the physical memory, we see that the elements of the column are not contiguous: there’s a gap of one element between each one. Here, strides come to the rescue: instead of specifying a stride of one, we specify a stride of two, saying that between one element and the next, you need to jump two slots. (By the way, this is why it’s called a “stride”: if we think of an index as walking across the layout, the stride says how many locations we stride forward every time we take a step.)
当我们查看物理内存时,我们看到该列的元素不是连续的:每个元素之间存在一个间隙。在这里,需要大步进行:我们没有指定步长为1,而是指定了步长为2,也就是说,在一个元素和下一个元素之间,您需要跳过两个插槽。
(顺便说一句,这就是为什么它被称为“步长”的原因:如果我们认为索引遍历整个布局,则步长表示每次迈出多少步。)
The stride representation can actually let you represent all sorts of interesting views on tensors; if you want to play around with the possibilities, check out the Stride Visualizer.
步幅表示实际上可以让您表示张量上的各种有趣的视图;如果您想尝试各种可能性,请查看步长可视化器。
Let’s step back for a moment, and think about how we would actually implement this functionality (after all, this is an internals talk.) If we can have views on tensor, this means we have to decouple the notion of the tensor (the user-visible concept that you know and love), and the actual physical data that stores the data of the tensor (called storage):
让我们退后一会,思考一下我们将如何实际实现此功能(毕竟,这是pytorch内部实现的讨论)如果我们可以为张量创建视图,这意味着我们必须解耦张量的概念(您知道并喜欢的用户可见的概念),以及存储张量数据的实际物理数据(称为存储):

There may be multiple tensors which share the same storage. Storage defines the dtype and physical size of the tensor, while each tensor records the sizes, strides and offset, defining the logical interpretation of the physical memory.
可能有多个张量共享相同的存储。存储定义了张量的dtype和物理大小,而每个张量记录了大小、步长和偏移量,从而定义了物理内存的逻辑解释。
One thing to realize is that there is always a pair of Tensor-Storage, even for “simple” cases where you don’t really need a storage (e.g., you just allocated a contiguous tensor with torch.zeros(2, 2)).
要意识到的一件事是,即使在您真正不需要存储的“简单”情况下,也总是存在一对Tensor-Storage(例如,刚刚分配了具有连续存储的张量torch.zeros(2, 2))。
By the way, we’re interested in making this picture not true; instead of having a separate concept of storage, just define a view to be a tensor that is backed by a base tensor. This is a little more complicated, but it has the benefit that contiguous tensors get a much more direct representation without the Storage indirection. A change like this would make PyTorch’s internal representation a bit more like Numpy’s.
顺便说一句,我们有兴趣改变这个状况。无需将存储定义为单独的概念,只需将视图定义为由基本张量支持的张量。这稍微复杂一点,但是它的好处是连续张量无需存储重定向即可获得更直接的表示。这样的更改会使PyTorch的内部表示形式更像Numpy的内部表示形式。
We’ve talked quite a bit about the data layout of tensor (some might say, if you get the data representation right, everything else falls in place). But it’s also worth briefly talking about how operations on the tensor are implemented. At the very most abstract level, when you call torch.mm, two dispatches happen:
我们已经对张量的数据布局进行了很多讨论(有人可能会说,如果正确地实现了数据表示,其他所有东西都就位了)。但是,值得一提的是关于如何实现张量的运算。在最抽象的层次上,当您调用
torch.mm时,会发生两次调度:

The first dispatch is based on the device type and layout of a tensor: e.g., whether or not it is a CPU tensor or a CUDA tensor (and also, e.g., whether or not it is a strided tensor or a sparse one). This is a dynamic dispatch: it’s a virtual function call (exactly where that virtual function call occurs will be the subject of the second half of this talk). It should make sense that you need to do a dispatch here: the implementation of CPU matrix multiply is quite different from a CUDA implementation. It is a dynamic dispatch because these kernels may live in separate libraries (e.g., libcaffe2.so versus libcaffe2_gpu.so), and so you have no choice: if you want to get into a library that you don’t have a direct dependency on, you have to dynamic dispatch your way there.
第一次调度基于张量的设备类型和布局:例如,它是CPU张量还是CUDA张量(以及例如它是strided张量还是稀疏张量)。这是一个动态调度:这是一个虚拟函数调用(该虚拟函数调用发生的确切位置将是本文的后半部分)。应该在此处进行调度应该很有意义:CPU矩阵乘法的实现与CUDA实现完全不同。这是一种“动态”调度,因为这些内核可能位于单独的库中(例如,libcaffe2.so与libcaffe2_gpu.so),因此您别无选择:如果您想进入一个没有直接依赖的库,因此您必须动态地在那儿调度自己的方式。
The second dispatch is a dispatch on the dtype in question. This dispatch is just a simple switch-statement for whatever dtypes a kernel chooses to support. Upon reflection, it should also make sense that we need to a dispatch here: the CPU code (or CUDA code, as it may) that implements multiplication on float is different from the code for int. It stands to reason you need separate kernels for each dtype.
第二个调度是有关dtype的调度。对于内核支持的任何dtypes,此调度只是一个简单的switch语句。
经过思考,我们应该在这里调度也是有意义的:CPU上(或CUDA代码)实现float乘法的代码和实现int的代码是不同的。可以说,每个dtype需要单独的内核。
This is probably the most important mental picture to have in your head, if you’re trying to understand the way operators in PyTorch are invoked. We’ll return to this picture when it’s time to look more at code.
如果您想了解PyTorch中运算符的调用方式,这可能是您脑海中最重要的心理印象。当需要更多地查看代码时,我们将返回到这张图片。

Since we have been talking about Tensor, I also want to take a little time to the world of tensor extensions. After all, there’s more to life than dense, CPU float tensors. There’s all sorts of interesting extensions going on, like XLA tensors, or quantized tensors, or MKL-DNN tensors, and one of the things we have to think about, as a tensor library, is how to accommodate these extensions.
由于我们一直在谈论Tensor,所以我也想花一点时间了解扩展张量。毕竟,除了密集的CPUfloat张量之外,生活中还有更多可用的东西。有各种有趣的扩展,例如XLA张量、量化张量或MKL-DNN张量,作为张量库,我们必须考虑的事情之一就是如何容纳这些扩展。

Our current model for extensions offers four extension points on tensors. First, there is the trinity three parameters which uniquely determine what a tensor is:
我们当前的扩展模型在张量上提供了四个扩展点。首先,三位一体的三个参数唯一地确定张量是什么:
- The device, the description of where the tensor’s physical memory is actually stored, e.g., on a CPU, on an NVIDIA GPU (cuda), or perhaps on an AMD GPU (hip) or a TPU (xla). The distinguishing characteristic of a device is that it has its own allocator, that doesn’t work with any other device.
设备,是张量物理内存实际存储位置的描述,例如在CPU、NVIDIA GPU(cuda)或AMD GPU(hip)或TPU(xla)上。设备的显着特征是它具有自己的分配器,该分配器不能与任何其他设备一起使用。 - The layout, which describes how we logically interpret this physical memory. The most common layout is a strided tensor, but sparse tensors have a different layout involving a pair of tensors, one for indices, and one for data; MKL-DNN tensors may have even more exotic layout, like blocked layout, which can’t be represented using merely strides.
布局,它描述了我们如何逻辑上解释此物理内存。最常见的布局是步长张量,而稀疏张量具有不同的布局,其中涉及一对张量,一个用于索引,一个用于数据。MKL-DNN张量可能具有更奇特的布局,例如块状布局,不能仅用步长来表示。 - The dtype, which describes what it is that is actually stored in each element of the tensor. This could be floats or integers, or it could be, for example, quantized integers.
数据类型,描述实际存储在张量的每个元素中的是什么。这可以是浮点数或整数,也可以是例如量化的整数。
If you want to add an extension to PyTorch tensors (by the way, if that’s what you want to do, please talk to us! None of these things can be done out-of-tree at the moment), you should think about which of these parameters you would extend. The Cartesian product of these parameters define all of the possible tensors you can make. Now, not all of these combinations may actually have kernels (who’s got kernels for sparse, quantized tensors on FPGA?) but in principle the combination could make sense, and thus we support expressing it, at the very least.
如果您想为PyTorch张量添加扩展(顺便说一句,如果您要这样做,请与我们联系!目前这些事情都无法在树外完成),您应该考虑要扩展这些参数中的哪一个。这些参数的笛卡尔乘积定义了您可以制作的所有可能的张量。
现在,这些组合并非都具有内核(谁在FPGA上获得了用于稀疏、量化张量的内核?),但是原则上,所有组合都可能有意义,因此我们至少支持表达它。
There’s one last way you can make an “extension” to Tensor functionality, and that’s write a wrapper class around PyTorch tensors that implements your object type. This perhaps sounds obvious, but sometimes people reach for extending one of the three parameters when they should have just made a wrapper class instead. One notable merit of wrapper classes is they can be developed entirely out of tree.
您可以对Tensor功能进行“扩展”的最后一种方法,那就是围绕PyTorch张量编写一个包装类,以实现您的对象类型。这听起来似乎很明显,但是有时候人们想要扩展一下这三个参数之一时,其实只需要创建一个包装器类。包装器类的一个显着优点是它们可以完全从树中开发出来。
When should you write a tensor wrapper, versus extending PyTorch itself? The key test is whether or not you need to pass this tensor along during the autograd backwards pass. This test, for example, tells us that sparse tensor should be a true tensor extension, and not just a Python object that contains an indices and values tensor: when doing optimization on networks involving embeddings, we want the gradient generated by the embedding to be sparse.
什么时候应该写张量包装器,而不是扩展PyTorch本身?关键测试是在autograd反向传播过程中是否需要传递该张量。例如,该测试告诉我们,稀疏张量应该是真正的张量扩展,而不仅仅是包含索引和值张量的Python对象:在涉及嵌入的网络上进行优化时,我们希望嵌入产生的梯度是稀疏的。

Our philosophy on extensions also has an impact of the data layout of tensor itself. One thing we really want out of our tensor struct is for it to have a fixed layout: we don’t want fundamental (and very frequently called) operations like “What’s the size of a tensor?” to require virtual dispatches. So when you look at the actual layout of a Tensor (defined in the TensorImpl struct), what we see is a common prefix of all fields that we consider all “tensor”-like things to universally have, plus a few fields that are only really applicable for strided tensors, but are so important that we’ve kept them in the main struct, and then a suffix of custom fields that can be done on a per-Tensor basis. Sparse tensors, for example, store their indices and values in this suffix.
我们的扩展哲学也影响张量本身的数据布局。我们真正希望从张量结构中获得的一件事是它具有固定的布局:我们不希望诸如"张量的大小是多少"之类的基本(并且经常被调用)操作要求虚拟调度(执行)。因此,当您查看张量的实际布局(在TensorImpl结构中定义)时,我们所看到的是我们认为所有具有"张量"之类的东西普遍具有的所有字段的通用前缀,再加上一些仅真正适用于步长张量但是很重要的字段,因为我们将它们保留在主结构中。然后是可以在每个张量基础上完成的自定义字段的后缀。例如,稀疏张量将其索引和值存储在此后缀中。

I told you all about tensors, but if that was the only thing PyTorch provided, we’d basically just be a Numpy clone. The distinguishing characteristic of PyTorch when it was originally released was that it provided automatic differentiation on tensors (these days, we have other cool features like TorchScript; but back then, this was it!)
我已经告诉过您所有关于张量的信息,但是如果那是PyTorch提供的唯一信息,那么我们基本上只是一个Numpy的克隆。PyTorch最初发布时的显着特征是它提供了对张量的自动微分(这些天,我们还有其他很酷的功能,例如TorchScript;但是在当时,就是这样!)
What does automatic differentiation do? It’s the machinery that’s responsible for taking a neural network:
自动微分有什么作用?负责获取(taking?)神经网络的事情是:

…and fill in the missing code that actually computes the gradients of your network:
…并填写实际上计算出网络梯度的缺少的代码:

Take a moment to study this diagram. There’s a lot to unpack; here’s what to look at:
花一点时间研究一下该图。有很多需要解释的东西, 这是要看的内容:
- First, rest your eyes on the variables in red and blue. PyTorch implements reverse-mode automatic differentiation, which means that we effectively walk the forward computations “backward” to compute the gradients. You can see this if you look at the variable names: at the bottom of the red, we compute
loss; then, the first thing we do in the blue part of the program is computegrad_loss.losswas computed fromnext_h2, so we computegrad_next_h2. Technically, these variables which we callgrad_are not really gradients; they’re really Jacobians left-multiplied by a vector, but in PyTorch we just call themgradand mostly everyone knows what we mean.
首先,请注意红色和蓝色的变量。PyTorch实现了反向模式自动微分,这意味着我们有效地沿着前向计算向后计算了梯度。如果您查看变量名,您会看到这一点:红色的下面,我们计算出loss。然后,我们在程序蓝色部分中要做的第一件事就是计算grad_loss。loss是根据next_h2计算的,所以我们先计算grad_next_h2。事实上,我们称之为grad_的这些变量不是真正的梯度,而是雅克比矩阵左乘向量,但是在PyTorch中,我们只是把他们叫成梯度而已,大多数人都知道我们的意思。 - If the structure of the code stays the same, the behavior doesn’t: each line from forwards is replaced with a different computation, that represents the derivative of the forward operation. For example, the
tanhoperation is translated into atanh_backwardoperation (these two lines are connected via a grey line on the left hand side of the diagram). The inputs and outputs of the forward and backward operations are swapped: if the forward operation producednext_h2, the backward operation takesgrad_next_h2as an input.
如果代码的结构保持不变,则行为不会:前向的每一行都用不同的计算代替,代表前向计算的导数。例如,tanh操作被转换成tanh_backward操作(在图示的左手边,这两行通过灰线连接起来)前向操作和后向操作的输入和输出被交换了:如果前向计算生成了next_h2,则反向计算以grad_next_h2作为参数
The whole point of autograd is to do the computation that is described by this diagram, but without actually ever generating this source. PyTorch autograd doesn’t do a source-to-source transformation (though PyTorch JIT does know how to do symbolic differentiation).
自动求导的全部要点是执行上图所描述的计算,但是实际上并没有生成相应的源代码。PyTorch自动求导不会进行源到源的转换(尽管PyTorch JIT确实知道如何进行符号微分)。

To do this, we need to store more metadata when we carry out operations on tensors. Let’s adjust our picture of the tensor data structure: now instead of just a tensor which points to a storage, we now have a variable which wraps this tensor, and also stores more information (AutogradMeta), which is needed for performing autograd when a user calls loss.backward() in their PyTorch script.
为此,当我们在张量上执行操作时,我们需要存储更多的元数据。让我们调整张量数据结构的图:现在,我们不仅有一个指向存储的张量,还拥有一个包装该张量的变量,并且还存储了更多信息(AutogradMeta),当用户在其PyTorch脚本中调用loss.backward()执行自动求导时需要此信息。
This is yet another slide which will hopefully be out of date in the near future. Will Feng is working on a Variable-Tensor merge in C++, following a simple merge which happened to PyTorch’s frontend interface.
这是又一张幻灯片,有望在不久的将来过时。在PyTorch的前端接口发生一次简单的合并之后,Will Feng正在进行C ++中的变量-张量合并。
We also have to update our picture about dispatch:
我们还必须更新有关调度的图片:

Before we dispatch to CPU or CUDA implementations, there is another dispatch on variables, which is responsible for unwrapping variables, calling the underlying implementation (in green), and then rewrapping the results into variables and recording the necessary autograd metadata for backwards.
在我们调度到CPU或CUDA实现之前,还有一个关于变量的调度,负责解包变量,调用基础实现(以绿色表示),然后将结果重新包装为变量并记录必要的autograd元数据以供向后使用。
Some implementations don’t unwrap; they just call into other variable implementations. So you might spend a while in the Variable universe. However, once you unwrap and go into the non-Variable Tensor universe, that’s it; you never go back to Variable (except by returning from your function.)
某些实现不会解包。他们只是调用其他变量实现。因此,您可能会在Variable世界中花费一段时间。但是,一旦打开包装并进入非变量Tensor世界,就是这样:您再也不会回到Variable(除非从函数中返回)
In my NY meetup talk, I skipped the following seven slides. I’m also going to delay writeup for them; you’ll have to wait for the sequel for some text.
在纽约市见面会演讲中,我跳过了以下七个幻灯片。我还将延迟为他们撰写论文;您将不得不等待续集中的一些文本。



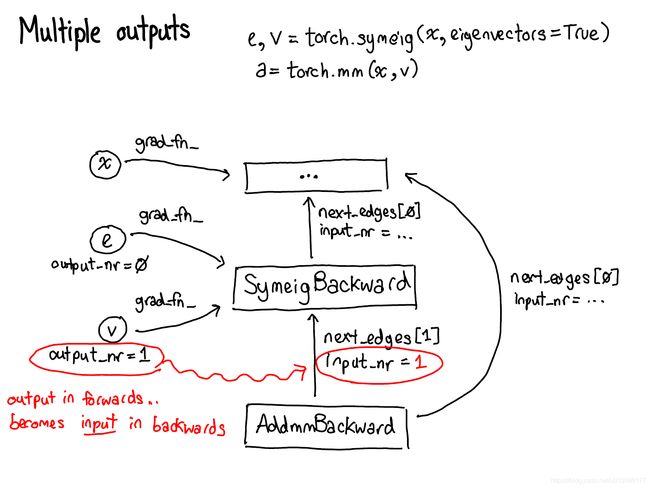
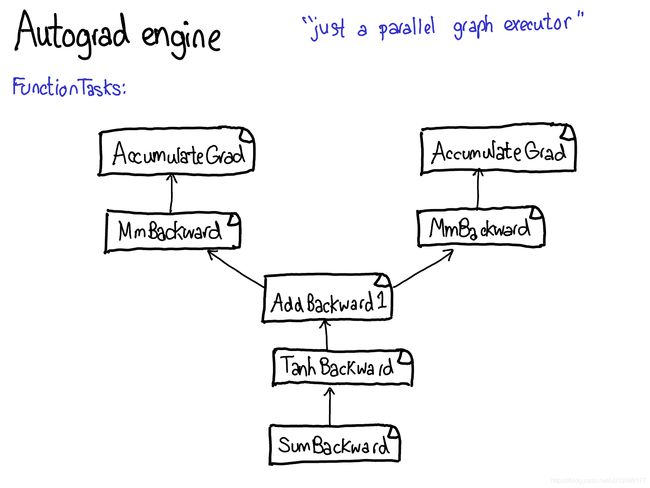



Enough about concepts, let’s look at some code.
关于概念已经足够了,让我们看一些代码。

PyTorch has a lot of folders, and there is a very detailed description of what they are in the CONTRIBUTING document, but really, there are only four directories you really need to know about:
PyTorch有很多文件夹,在CONTRIBUTING中有很多详细的描述,但实际上,您只需要了解四个目录:

- First,
torch/contains what you are most familiar with: the actual Python modules that you import and use. This stuff is Python code and easy to hack on (just make a change and see what happens). However, lurking not too deep below the surface is…
首先,torch/包含您最熟悉的内容:导入和使用的实际Python模块。这些东西是Python代码,易于破解(只需进行更改,看看会发生什么)。但是,潜伏在地表以下不是很深。 torch/csrc/, the C++ code that implements what you might call the frontend of PyTorch. In more descriptive terms, it implements the binding code that translates between the Python and C++ universe, and also some pretty important pieces of PyTorch, like the autograd engine and the JIT compiler. It also contains the C++ frontend code.
torch/csrc, 实现PyTorch前端可以调用的C ++代码。用更具描述性的术语,它实现了在Python和C++之间转换的绑定代码,还有一些非常重要的PyTorch片段,比如自动求导引擎和JIT编译器。也包含C++前端代码。aten/, short for “A Tensor Library” (coined by Zachary DeVito), is a C++ library that implements the operations of Tensors. If you’re looking for where some kernel code lives, chances are it’s in ATen. ATen itself bifurcates into two neighborhoods of operators: the “native” operators, which are modern, C++ implementations of operators, and the “legacy” operators (TH, THC, THNN, THCUNN), which are legacy, C implementations. The legacy operators are the bad part of town; try not to spend too much time there if you can.
aten/,"A Tensor Libaray"的缩写, 是一个C++库,实现了Tensor的算子。如果你在找一些核函数模板,看一下Aten吧。ATen本身分为两个运算符区域:"native"运算符(它们是现代的C ++实现)和"legacy"运算符(TH,THC,THNN,THCUNN),它们是传统的C实现。遗留的算子是代码中最糟糕的部分。如果可以的话,尽量不要在那儿花费太多时间。c10/, which is a pun on Caffe2 and A"Ten" (get it? Caffe 10) contains the core abstractions of PyTorch, including the actual implementations of the Tensor and Storage data structures.
c10/是Caffe2和ATen的双关语,包含了PyTorch的核心抽象,实现了Tensor和Storage结构的真正实现。
That’s a lot of places to look for code; we should probably simplify the directory structure, but that’s how it is. If you’re trying to work on operators, you’ll spend most of your time in aten.
很多地方都可以找到代码。我们可能应该简化目录结构,下面介绍方法。如果您尝试修改算子,则应该将大部分时间都花在aten上。
Let’s see how this separation of code breaks down in practice:
我们看看这种分离的代码在实践中是如何分解的:

When you call a function like torch.add, what actually happens? If you remember the discussion we had about dispatching, you already have the basic picture in your head:
当您调用类似torch.add的函数时,实际发生了什么?如果您还记得我们有关调度的讨论,那么您已经掌握了基本知识:
- We have to translate from Python realm to the C++ realm (Python argument parsing)
我们必须从Python领域转换为C++领域(Python参数解析) - We handle variable dispatch (VariableType–Type, by the way, doesn’t really have anything to do programming language types, and is just a gadget for doing dispatch.)
我们处理Variable调度(顺便说一句,VariableType–Type确实与编程语言类型没有任何关系,只是一个用于进行调度的小工具。) - We handle device type / layout dispatch (Type)
处理设备类型/布局分发(类型) - We have the actual kernel, which is either a modern native function, or a legacy TH function.
我们有实际的核函数,它可以是现代的native函数,也可以是旧式TH函数。
Each of these steps corresponds concretely to some code. Let’s cut our way through the jungle.
这些步骤中的每一个都具体对应于某些代码。让我们开始穿越丛林。

Our initial landing point in the C++ code is the C implementation of a Python function, which we’ve exposed to the Python side as something like torch._C.VariableFunctions.add. THPVariable_add is the implementation of one such implementation.
在C++代码的初始着陆点是Python函数的C实现,正如我们在Python幻灯片里展示的torch._C.VariableFunctions.add。THPVariable_add是这样的一种实现。
One important thing to know about this code is that it is auto-generated. If you search in the GitHub repository, you won’t find it, because you have to actually build PyTorch to see it. Another important thing is, you don’t have to really deeply understand what this code is doing; the idea is to skim over it and get a sense for what it is doing. Above, I’ve annotated some of the most important bits in blue: you can see that there is a use of a class PythonArgParser to actually pull out C++ objects out of the Python args and kwargs; we then call a dispatch_add function (which I’ve inlined in red); this releases the global interpreter lock and then calls a plain old method on the C++ Tensor self. On its way back, we rewrap the returned Tensor back into a PyObject.
有关此代码的重要一件事是它是自动生成的。如果您在GitHub存储库中搜索,将找不到它,因为您必须实际构建PyTorch才能看到它。另一个重要的事情是,您不必真正深入地了解此代码在做什么。想法应该是略过它,并对它的功能有所了解。上面,我用蓝色注释了一些最重要的部分:您会看到有一个PythonArgParser类的使用,可以从Pythonargs和kwargs中实际提取C++对象。然后我们调用dispatch_add函数(我用红色下划线);这会释放全局解释器锁,然后在C++ Tensorself上调用一个普通的旧方法。在返回的过程中,我们将返回的Tensor重新包装回PyObject中。
(At this point, there’s an error in the slides: I’m supposed to tell you about the Variable dispatch code. I haven’t fixed it here yet. Some magic happens, then…)
(此时,幻灯片中有一个错误:我应该向您介绍变量调度代码。我还没有在这里修复它。那么,发生了一些不可思议的事情……)

When we call the add method on the Tensor class, no virtual dispatch happens yet. Instead, we have an inline method which calls a virtual method on a “Type” object. This method is the actual virtual method (this is why I say Type is just a “gadget” that gets you dynamic dispatch.) In the particular case of this example, this virtual call dispatches to an implementation of add on a class named TypeDefault. This happens to be because we have an implementation of add that is the same for every device type (both CPU and CUDA); if we had happened to have different implementations, we might have instead landed on something like CPUFloatType::add. It is this implementation of the virtual method that finally gets us to the actual kernel code.
当我们在Tensor类上调用add方法时,还没有虚拟调度发生。相反,我们有一个内联方法,该内联方法在Type对象上调用虚拟方法。该方法是实际的虚拟方法(这就是为什么我说Type只是让您动态调度的“小工具”的原因)在本示例的特定情况下,此虚拟调用将调度到名为TypeDefault的类上的add的实现。碰巧是因为我们有一种add的实现,对于每种设备类型(CPU和CUDA)都相同。如果我们碰巧有不同的实现, 我们可能会调用类似CPUFloatType::add的东西。正是这种虚拟方法的实现最终使我们了解了实际的核函数。
Hopefully, this slide will be out-of-date very soon too; Roy Li is working on replacing
Typedispatch with another mechanism which will help us better support PyTorch on mobile.希望这张幻灯片也将很快过时。Roy Li正在用另一种机制替换
Type调度,这将有助于我们在移动设备上更好地支持PyTorch。
It’s worth reemphasizing that all of the code, until we got to the kernel, is automatically generated.
值得强调的是,直到进入核函数之前,所有代码都是自动生成的。

It’s a bit twisty and turny, so once you have some basic orientation about what’s going on, I recommend just jumping straight to the kernels.
可能有一点混乱,所以一旦有一些关于正在做什么的基本的方向,我建议你直接跳到核函数上。

PyTorch offers a lot of useful tools for prospective kernel writers. In this section, we’ll walk through a few of them. But first of all, what do you need to write a kernel?
torch提供了丰富的工具用于预期的核函数编写。在本节中,我们会浏览一部分。但是首先,写内核需要什么?

We generally think of a kernel in PyTorch consisting of the following parts:
通常认为torch包含下面的部分
- First, there’s some metadata which we write about the kernel, which powers the code generation and lets you get all the bindings to Python, without having to write a single line of code.
首先,有一些关于我们要写的内核的元数据,用于代码生成,并且得到所有到python的绑定,不需要写一行代码。 - Once you’ve gotten to the kernel, you’re past the device type / layout dispatch. The first thing you need to write is error checking, to make sure the input tensors are the correct dimensions. (Error checking is really important! Don’t skimp on it!)
一旦接近核函数,你必须传递设备类型/布局指派。首先需要写的是错误检查,以确保输入的tensor是正确的维度。(错误检查很重要,不要撇下他) - Next, we generally have to allocate the result tensor which we are going to write the output into.
下一步,我们需要分配结果张量,我们将要输出的地方。 - Time for the kernel proper. At this point, you now should do the second, dtype dispatch, to jump into a kernel which is specialized per dtype it operates on. (You don’t want to do this too early, because then you will be uselessly duplicating code that looks the same in any case.)
该写核函数了。在此刻,你需要做第二次类型指派,以跳转到用于特定数据类型的核函数。 - Most performant kernels need some sort of parallelization, so that you can take advantage of multi-CPU systems. (CUDA kernels are “implicitly” parallelized, since their programming model is built on top of massive parallelization).
多数 核函数都需要一定程度的并行,以便充分利用多CPU系统。(CUDA核函数是隐形并行的,因为他们的编程模型构建在大量的并行上) - Finally, you need to access the data and do the computation you wanted to do!
最后,你需要访问数据并做自己的计算!
In the subsequent slides, we’ll walk through some of the tools PyTorch has for helping you implementing these steps.
在随后的幻灯片中,我们将浏览一下PyTorch拥有的一些工具帮助你实现这些步骤。

To take advantage of all of the code generation which PyTorch brings, you need to write a schema for your operator. The schema gives a mypy-esque type of your function, and also controls whether or not we generate bindings for methods or functions on Tensor. You also tell the schema what implementations of your operator should be called for given device-layout combinations. Check out the README in native is for more information about this format.
要利用PyTorch带来的所有代码生成功能,您需要为算子编写模式(schema)。模式提供函数的mypy-esque类型,并控制我们是否为Tensor上的方法或函数生成绑定。您还告诉模式,对于给定的设备布局组合,应调用算子的哪些实现。查看原生开发自述文件可获得有关此格式的更多信息。
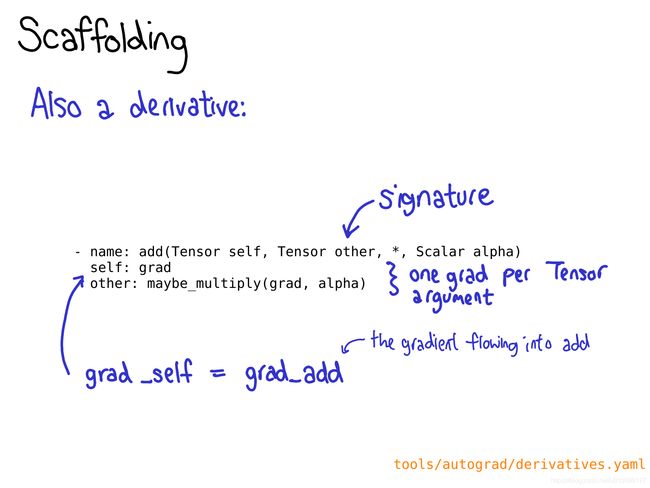
You also may need to define a derivative for your operation in derivatives.yaml.
您可能还需要在derivatives.yaml中为您的算子定义一个导数。

Error checking can be done by way of either a low level or a high level API. The low level API is just a macro, TORCH_CHECK, which takes a boolean, and then any number of arguments to make up the error string to render if the boolean is not true. One nice thing about this macro is that you can intermix strings with non-string data; everything is formatted using their implementation of operator<<, and most important data types in PyTorch have operator<< implementations.
可以通过低级或高级API进行错误检查。低级API是一个宏TORCH_CHECK,采取一个布尔值,如果布尔值不为真,则会将任意数量的参数拼接成错误信息字符串。关于此宏的一件好事是,您可以将字符串与非字符串数据混合在一起。一切都通过使用operator<<来格式化字符串,PyTorch中最重要的数据类型都实现了operator<<。
The high level API saves you from having to write up repetitive error messages over and over again. The way it works is you first wrap each Tensor into a TensorArg, which contains information about where the tensor came from (e.g., its argument name). It then provides a number of pre-canned functions for checking various properties; e.g., checkDim() tests if the tensor’s dimensionality is a fixed number. If it’s not, the function provides a user-friendly error message based on the TensorArg metadata.
高级API使您不必重复编写重复的错误消息。它的工作方式是您首先将每个Tensor包装到TensorArg中,其中包含有关张量来自何处的信息(例如,其参数名称)。然后,它提供了许多预定义的功能来检查各种属性。例如,checkDim()测试张量的维数是否为固定数。如果不是,该函数将基于TensorArg元数据提供用户友好的错误消息。

One important thing to be aware about when writing operators in PyTorch, is that you are often signing up to write three operators: abs_out, which operates on a preallocated output (this implements the out= keyword argument), abs_, which operates inplace, and abs, which is the plain old functional version of an operator.
在PyTorch中编写运算符时要注意的一件事是,您经常要注册编写三个算子:abs_out,它在预分配的输出上进行运算(这实现了out=关键字参数),abs_可在原地操作和abs(用于算子的普通旧功能版本)。
Most of the time, abs_out is the real workhorse, and abs and abs_ are just thin wrappers around abs_out; but sometimes writing specialized implementations for each case are warranted.
大部分时间, abs_out是真正的主力,abs和abs_都是对abs_out的包装函数;但有时候写为每种情况写特定的实现。

To do dtype dispatch, you should use the AT_DISPATCH_ALL_TYPES macro. This takes in the dtype of the tensor you want to dispatch over, and a lambda which will be specialized for each dtype that is dispatchable from the macro. Usually, this lambda just calls a templated helper function.
要进行数据类型分配,您应该使用AT_DISPATCH_ALL_TYPES宏。这将读取您要分派的张量的类型,以及专用于每个数据类型的lambda函数。通常,此lambda仅调用模板化的辅助函数。
This macro doesn’t just “do dispatch”, it also decides what dtypes your kernel will support. As such, there are actually quite a few versions of this macro, which let you pick different subsets of dtypes to generate specializations for. Most of the time, you’ll just want AT_DISPATCH_ALL_TYPES, but keep an eye out for situations when you might want to dispatch to some more types. There’s guidance in Dispatch.h for how to select the correct one for your use-case.
这个宏不仅可以“执行分派”,还可以决定核函数支持的数据类型。因此,此宏实际上有很多版本,可让您选择dtype的不同子集来为其生成专门的信息。大多数时候,您只需要AT_DISPATCH_ALL_TYPES,但是请留意可能要分派给其他类型的情况。在Dispatch.h中有有关如何为您的用例选择正确选项的指南。

On CPU, you frequently want to parallelize your code. In the past, this was usually done by directly sprinkling OpenMP pragmas in your code.
在CPU中,你经常想要并行化你的代码,在以前,这通常通过在代码中直接添加OpenMP指示来完成的。

At some point, we have to actually access the data. PyTorch offers quite a few options for doing this.
在某些情况下,我们必须真正的访问数据。PyTorch提供了很多选项做这些事情:
- If you just want to get a value at some specific location, you should use
TensorAccessor. A tensor accessor is like a tensor, but it hard codes the dimensionality and dtype of the tensor as template parameters. When you retrieve an accessor likex.accessor, we do a runtime test to make sure that the tensor really is this format; but after that, every access is unchecked. Tensor accessors handle strides correctly, so you should prefer using them over raw pointer access (which, unfortunately, some legacy kernels do.) There is also aPackedTensorAccessor, which is specifically useful for sending an accessor over a CUDA launch, so that you can get accessors from inside your CUDA kernel. (One notable gotcha:TensorAccessordefaults to 64-bit indexing, which is much slower than 32-bit indexing in CUDA!)
如果您只想获得某个特定位置的值,你应该用TensorAccessor。张量访问器就像一个张量,但是它将张量的维度和类型硬编码成了模板参数。 - If you’re writing some sort of operator with very regular element access, for example, a pointwise operation, you are much better off using a higher level of abstraction, the
TensorIterator. This helper class automatically handles broadcasting and type promotion for you, and is quite handy.如果您要编写某种具有非常规则的元素访问权限的运算符(例如,逐点运算),则使用更高级别的抽象TensorIterator会更好。此类帮助程序自动为您处理广播和类型提升,并且非常方便。 - For true speed on CPU, you may need to write your kernel using vectorized CPU instructions. We’ve got helpers for that too! The
Vec256class represents a vector of scalars and provides a number of methods which perform vectorized operations on them all at once. Helpers likebinary_kernel_vecthen let you easily run vectorized operations, and then finish everything that doesn’t round nicely into vector instructions using plain old instructions. The infrastructure here also manages compiling your kernel multiple times under different instruction sets, and then testing at runtime what instructions your CPU supports, and using the best kernel in those situations.
为了获得真正的CPU速度,您可能需要使用矢量化CPU指令编写内核。我们也为此提供了helpers!vec256类表示标量的向量,并提供了许多对它们立即执行向量化运算的方法。然后,可以使用诸如binary_kernel_vec之类的helpers轻松地执行矢量化操作,然后使用简单的旧指令完成所有不能很好地转换为矢量指令的操作。这里的基础架构还管理着在不同指令集下多次编译内核,然后在运行时测试CPU支持的指令,并在这些情况下使用最佳内核。

A lot of kernels in PyTorch are still written in the legacy TH style. (By the way, TH stands for TorcH. It’s a pretty nice acronym, but unfortunately it is a bit poisoned; if you see TH in the name, assume that it’s legacy.) What do I mean by the legacy TH style?
PyTorch中的许多内核仍然采用传统的TH风格编写。(顺便说一下,TH代表TorcH。这是一个很好的首字母缩写,但是不幸的是它有点中毒;如果您看到TH的名字,那就假设它是旧版。)旧版TH样式是什么意思?
- It’s written in C style, no (or very little) use of C++.
它是用C风格写的,没有或很少使用C++. - It’s manually refcounted (with manual calls to
THTensor_freeto decrease refcounts when you’re done using tensors), and
它用手工引用计数(当Tensor使用完成时需要手工调用THTensor_free减少引用计数) - It lives in
generic/directory, which means that we are actually going to compile the file multiple times, but with different#define scalar_t.
它存在于generic/文件夹中,这意味着我们实际上将多次编译文件,但是与#define scalar_t不同。
This code is pretty crazy, and we hate reviewing it, so please don’t add to it. One of the more useful tasks that you can do, if you like to code but don’t know too much about kernel writing, is to port some of these TH functions to ATen.
该代码非常疯狂,我们讨厌对其进行审查,因此请不要添加它。如果您想编写代码但对内核编写不了解太多,那么您可以执行的更有用的任务之一就是将其中一些TH函数移植到ATen。


To wrap up, I want to talk a little bit about working efficiently on PyTorch. If the largeness of PyTorch’s C++ codebase is the first gatekeeper that stops people from contributing to PyTorch, the efficiency of your workflow is the second gatekeeper. If you try to work on C++ with Python habits, you will have a bad time: it will take forever to recompile PyTorch, and it will take you forever to tell if your changes worked or not.
总结一下,我想谈谈有效使用PyTorch的知识。如果PyTorch的C++代码库的庞大是阻止人们参与PyTorch的第一个障碍,那么工作流的效率就是第二个障碍。如果您尝试使用Python习惯来使用C++,你的体验会很糟糕:重新编译PyTorch将花费很多时间,并且将花费很长时间才能知道您所做的更改是否有效。
How to work efficiently could probably be a talk in and of itself, but this slide calls out some of the most common anti-patterns I’ve seen when someone complains: “It’s hard to work on PyTorch.”
如何有效地工作可能本身就是一个话题,但是这张幻灯片列举了人们最常抱怨的模式:“在PyTorch上很难工作。”
- If you edit a header, especially one that is included by many source files (and especially if it is included by CUDA files), expect a very long rebuild. Try to stick to editing cpp files, and edit headers sparingly!
如果编辑头文件,尤其是许多源文件包含的头文件(尤其是CUDA文件使用的头文件),则需要很长的重建时间。尝试坚持编辑cpp文件,并谨慎编辑头文件! - Our CI is a very wonderful, zero-setup way to test if your changes worked or not. But expect to wait an hour or two before you get back signal. If you are working on a change that will require lots of experimentation, spend the time setting up a local development environment. Similarly, if you run into a hard to debug problem on a specific CI configuration, set it up locally. You can download and run the Docker images locally
我们的CI是一种非常出色的无需设置的方法,用于测试您的更改是否有效。但是,请等待一两个小时,然后再回来看。如果您要进行一项需要大量实验的更改,请花一些时间来设置本地开发环境。同样,如果在特定的CI配置上遇到难以调试的问题,请在本地进行配置。你可以下载并在本地运行Docker镜像 - The CONTRIBUTING guide explains how to setup ccache; this is highly recommended, because sometimes it will help you get lucky and avoid a massive recompile when you edit a header. It also helps cover up bugs in our build system, when we recompile files when we shouldn’t.
贡献指南解释了如何设置ccache。强烈建议您这样做,因为有时它可以帮助您幸运地避免在编辑头文件时进行大量重新编译。当我们不应该重新编译文件时,它也有助于掩盖我们构建系统中的错误。 - At the end of the day, we have a lot of C++ code, and you will have a much more pleasant experience if you build on a beefy server with CPUs and RAM. In particular, I don’t recommend doing CUDA builds on a laptop; building CUDA is sloooooow and laptops tend to not have enough juice to turnaround quickly enough.
归根结底,我们有很多C ++代码,如果您在具有CPU和RAM的强大服务器上构建,您将获得更加愉悦的体验。特别是,我不建议在笔记本电脑上进行CUDA构建。建立CUDA的过程非常繁琐,因此笔记本电脑往往没有足够的资源来快速地周转。

So that’s it for a whirlwind tour of PyTorch’s internals! Many, many things have been omitted; but hopefully the descriptions and explanations here can help you get a grip on at least a substantial portion of the codebase.
这就是PyTorch内部的旋风之旅!许多事情被省略了。但是希望这里的描述和解释可以帮助您掌握至少一部分代码库。
Where should you go from here? What kinds of contributions can you make? A good place to start is our issue tracker. Starting earlier this year, we have been triaging issues; issues labeled triaged mean that at least one PyTorch developer has looked at it and made an initial assessment about the issue. You can use these labels to find out what issues we think are high priority or look up issues specific to some module, e.g., autograd or find issues which we think are small (word of warning: we’re sometimes wrong!)
你应该从这里去哪里?您可以做出哪些贡献?从今年年初开始,我们一直在对问题进行分类,标记为“已分类”的问题意味着至少有一个PyTorch开发人员已经对其进行了研究并对该问题进行了初步评估。您可以使用这些标签来找出我们认为哪些问题是高优先级的。或查找特定于某个模块的问题,例如自动求导,或者找出我们认为比较小的问题
Even if you don’t want to get started with coding right away, there are many other useful activities like improving documentation (I love merging documentation PRs, they are so great), helping us reproduce bug reports from other users, and also just helping us discuss RFCs on the issue tracker. PyTorch would not be where it is today without our open source contributors; we hope you can join us too!
即使您不想立即开始编码,也有许多其他有用的活动,例如改进文档(我喜欢合并文档PR,它们是如此出色),可帮助我们重现其他用户的错误报告,并且只是帮助我们在问题跟踪器上讨论RFC。如果没有我们的开源贡献者,PyTorch也不会有今天。我们希望您也能加入我们!