ICCV 2021 | 微软MSRA提出:训练快速收敛的条件DETR
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:集智书童 论文:https://arxiv.org/abs/2108.06152代码:https://github.com/Atten4Vis/ConditionalDETR
论文:https://arxiv.org/abs/2108.06152代码:https://github.com/Atten4Vis/ConditionalDETR
本文作者提出了一种conditional cross-attention mechanism用于快速训练DETR,从decoder embedding中学习了一个conditional spatial query用于decoder multi-head cross-attention;实验结果表明,对于Backbone R50和R101,条件DETR收敛速度快6.7倍;对于backboone DC5-R50和DC5-R101,条件DETR收敛速度快10倍。
1简介
最近发展起来的DETR方法将transformer编解码器体系结构应用于目标检测并取得了很好的性能。在本文中,作者解决了训练收敛速度慢这一关键问题,并提出了一种conditional cross-attention mechanism用于快速训练DETR。作者动机是cross-attention在DETR中高度依赖content embeddings定位的4端和预测框,这增加了对高质量content embedding的需求进而增加了训练的难度。
本文方法被命名为条件DETR,从decoder embedding中学习了一个conditional spatial query用于decoder multi-head cross-attention。其好处是,通过conditional spatial query每个cross-attention head能够关注包含不同区域的band(例如,一个目标端点或目标box内的一个区域)。这缩小了目标分类和box回归的不同区域定位的空间范围,从而减轻了对content embedding的依赖,减轻了训练。
实验结果表明,对于Backbone R50和R101,条件DETR收敛速度快6.7倍;对于backboone DC5-R50和DC5-R101,条件DETR收敛速度快10倍。
2背景
DETR方法将transformer应用于目标检测取得了良好的性能。它有效地消除了许多手工制作组件的需要,包括NMS和Anchor生成。
DETR方法在训练上收敛缓慢,需要500个epoch才能取得良好的效果。Deformable DETR通过使用高分辨率和多尺度编码器将global dense attention(self-attention和cross-attention)替换为deformable attention来解决这个问题。相反,本文仍然使用global dense attention并提出了一个改进的 decoder cross-attention mechanism以加速训练收敛的过程。
本文方法的动机是高度依赖content embeddings和spatial embeddings in cross-attention。实验结果表明,如果从第2解码器层去除key和query中的位置嵌入,只使用key和query中的content embeddings,检测AP略有下降(1%)。
 图1
图1
图1(第2行)显示了50个epoch训练的DETR cross-attention的spatial attention weight maps。可以看到,4个映射中有2个没有正确地突出对应端点的波段,因此在缩小内容查询的空间范围以精确定位端点方面很弱。其原因是:
spatial query:即目标query,只给出general attention weight map,而没有利用具体的图像信息;
由于训练时间短content embeddings不够强,不能很好地匹配spatial key,因为它们也用于匹配content key。这增加了对高质量content embeddings的依赖性,从而增加了训练难度。
本文提出了一种有条件的DETR方法,该方法从之前对应的解码器输出嵌入中学习每个query的条件spatial embedding,形成decoder multi-head cross-attention的条件spatial query。通过将用于回归目标框的信息映射到嵌入空间来预测条件spatial query。
3条件DETR
3.1 方法概览
该方法采用端到端目标检测器(detection transformer, DETR),无需生成NMS或Anchor即可一次性预测所有目标。该体系结构由CNN Backbone、transformer encoder、transformer decoder、目标分类器和边界框位置预测器组成。transformer encoder的目的是改进CNN Backbone的content embeddings输出。它是由多个编码器层组成的堆栈,其中每一层主要由self-attention层和feed-forward层组成。
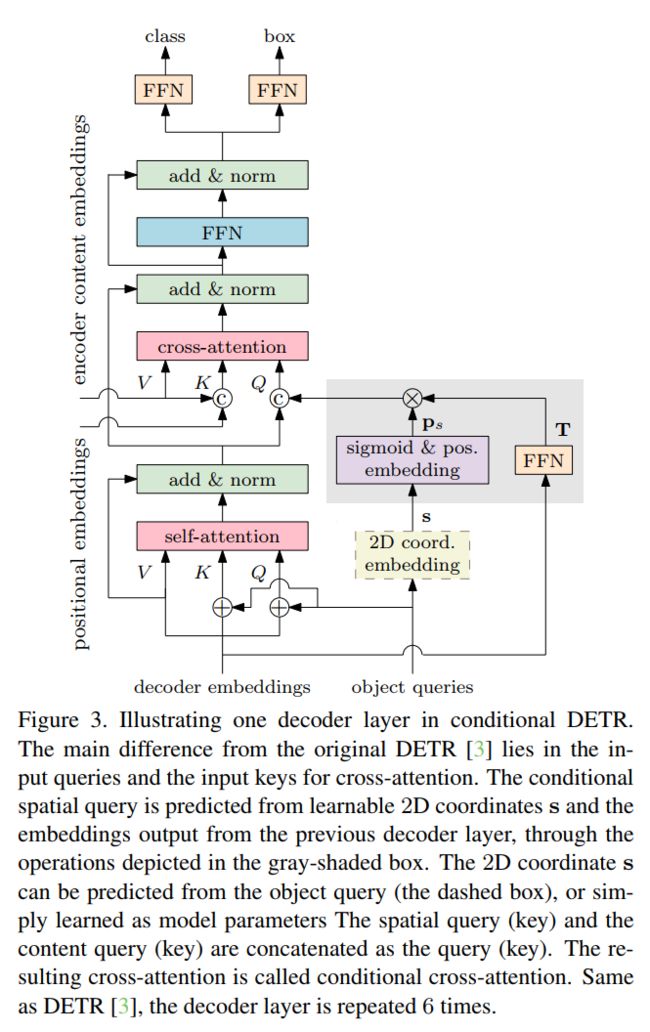 图3
图3
transformer decoder是一堆decoder layer。每个decoder layer如图3所示,由3个主要层组成:
self-attention layer:用于去除重复预测,执行前一解码器层输出的嵌入之间的交互,用于类和box的预测;
cross-attention layer:该层聚合编码器输出的embedding以细化解码器embedding改进类和box预测;
feed-forward layer
Box回归
从每个decoder embedding中预测一个候选框,如下所示:
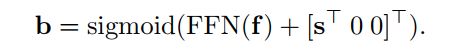
这里, 是decoder embedding。 是一个4维矢量 ,由框的中心、框的宽度和框的高度组成。Sigmoid()用于将预测b归一化到范围[0,1]。FFN()的目的是预测非规范化框。在原始DETR中为(0,0),s为参考点的非归一化二维坐标。在本方法中,作者考虑2个选择:将参考点s作为每个候选框预测的参数学习,或者从相应的目标query中生成它。
类别预测
每个候选框的分类score也通过FNN预测:
Main work
cross-attention mechanism的目的是定位不同的区域(用于box检测的4个端点和box内用于目标分类的区域)并聚合相应的嵌入。本文提出了一种条件cross-attention mechanism,通过引入conditional spatial query来提高定位能力和加速训练的收敛过程。
3.2 DETR Decoder Cross-Attention
DETR解码器cross-attention mechanism有3个输入:query、key和value。每个key都是通过添加一个content key (编码器的content embedding输出)和一个spatial key (对应的标准化2D坐标的positional embedding)形成的。该value是由编码器输出的content embedding(与content key相同)形成的。
在原始的DETR方法中,每个query是通过添加content query (decoder self-attention embedding)和spatial query (即object query )形成的。在实现中,有N=300个object queries,相应地有N个query,每个query在一个解码器层输出一个候选检测结果。
attention weight是基于query与key的点积:
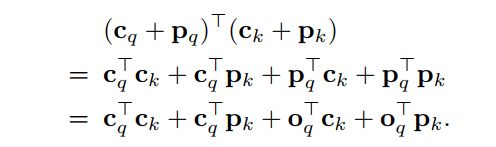
3.3 Conditional Cross-Attention
提出的Conditional Cross-Attention将解码器self-attention输出的content query 和spatial query 串联起来形成query。因此,同理,key由content key 和spatial key 拼接而成。
cross-attention weight由content attention weight和spatial attention weight两部分组成。这两个权重来自两个点积,content和spatial点积:
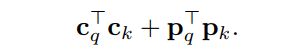
与原来的DETR Cross-Attention不同,本文所提的机制分离了content query和spatial query的角色,使spatial query和content query分别关注spatial和content的attention weight。
另外一个重要的任务是从前一个解码器层的embedding 计算spatial query 。首先识别出不同区域的空间信息是由解码器 embedding 和参考点这两个因素共同决定的。然后展示了如何将它们映射到embedding space形成query ,使spatial位于key的2D坐标映射到的同一空间。
解码器embedding包含不同区域相对于参考点的位移。式1中的box预测过程包括2个步骤:
对非归一化空间中的参考点进行预测;
将预测框归一化到范围[0,1];
步骤(1)表示decoder embedding f包含了构成方框的4个端点相对于非归一化空间中的参考点s的位移。这意味着,无论是embedding f还是参考点s,都需要确定不同区域、4个极值以及预测分类评分的区域的空间信息。
Conditional spatial query prediction
通过embedding f和参考点s预测条件空间查询,
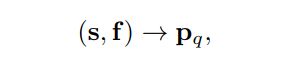
以便与key的标准化2D坐标映射到的位置空间对齐。这个过程如图3的灰色框区所示。
这里将参考点归一化,然后将其映射到256维正弦位置嵌入,方法与key的位置嵌入相同:
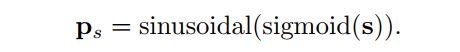
然后通过可学习线性投影+ReLU+可学习线性投影组成的FFN将解码器embedding f中包含的位移信息映射到同一空间中的线性投影:
conditional spatial query通过转换embedding空间中的参考点来计算:
作者选择简单和计算效率高的对角矩阵。256个对角线元素被表示为一个向量 。conditional spatial query通过逐元素乘法计算:
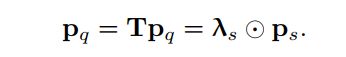
Multi-head cross-attention
与DETR一样作者采用标准的Multi-head cross-attention机制。目标检测通常需要隐式或显式定位目标的4个端点以实现精确的box回归,并定位目标区域以实现精确的目标分类。multi-head mechanism有利于解决定位任务的纠缠问题。
作者通过将query、key和value M=8次投影到低维的线性投影来执行multi-head parallel attentions。spatial和content query(key)分别以不同的线性投影投影到每个head。value投影与原始的DETR相同,仅用于content。
3.4 可视化分析
图4可视化了每个attention weight maps:
spatial attention weight maps
content attention weight maps
combined attention weight maps
对spatial dot-products 、 content dot-products 和combined dot-products 进行softmax normalized。图中显示了8个map中的5个其他3个是重复的,对应于底部和顶部的端点,以及目标框内的一个小区域。
 图4
图4
可以看到,每个head的spatial attention weight maps能够定位一个不同的区域(包含一个极点的区域或物体box内的区域)。有趣的是,每个spatial attention weight maps对应的一个极点突出了一个空间带,该空间带与目标框的相应边缘重叠。目标框内区域的另一个spatial attention weight maps仅仅突出显示了一个小区域,该区域的表示可能已经编码了足够的目标分类信息。
content attention weight maps还突出了分散的区域。空间和内容映射的组合过滤掉了其他高亮部分,并保留了极端高亮部分以实现精确的box回归。
Comparison to DETR
图1显示了条件式DETR(第1行)和经过50个epoch训练的原始DETR(第2行)的spatial attention weight maps。本文方法的映射是通过spatial key和query之间的dot 的softmax normalized来计算的:
可以看出spatial attention weight maps准确定位了不同的区域。相比之下,原始的DETR中包含50个epoch的map不能准确定位2个极点,而500个训练epoch(第3行)使得content query更强,从而实现了精确定位。这意味着学习content query 作为2个角色(同时匹配content key和spatial key)是非常困难的,因此需要更多的训练epoch。
分析
图4所示的spatial attention weight maps暗示用于形成spatial query的conditional spatial query至少有2种效果:
将突出显示的位置转换为4个端点和目标框内的位置:有趣的是,突出显示的位置在目标框内的空间分布相似;
缩放顶端亮点的空间扩展:大目标的空间扩展大,小目标的空间扩展小。
这2种效果是在spatial embedding space中通过T/ps变换实现的(通过cross-attention中包含的独立于图像的线性投影进一步分离,并分布到每个head)。这说明变换T不仅包含前面讨论的位移,还包含目标尺度。
4实验
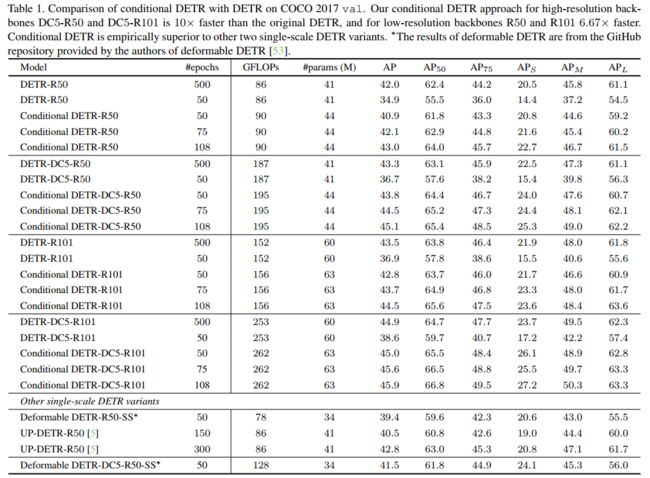 表1
表1
表1给出了DETR和条件DETR的结果。具有50个训练期的DETR比500个训练期的表现差得多。
对于R50和R101具有50个训练周期的条件DETR作为backbone,其表现略低于具有500个训练周期的DETR。
对于DC5-R50和DC5-R101,带有50个训练周期的条件DETR的性能与带有500个训练周期的DETR相似。
4个backbone 75/108个训练周期的条件DETR优于500个训练周期的DETR。
总之,高分辨率backbone DC5-R50和DC5-R101的有条件DETR比原始的DETR快10倍,低分辨率backbone R50和R101快6.67倍。换句话说,有条件的DETR对于更强大的backbone和更好的性能表现得更好。
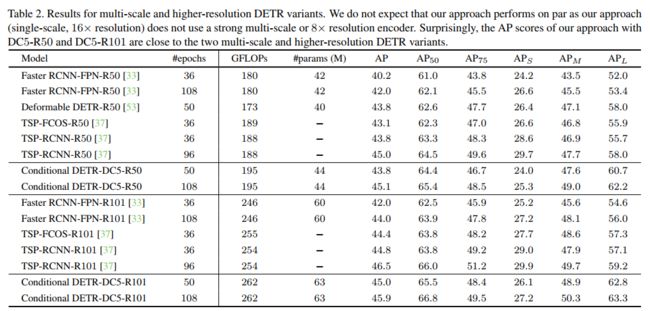 表2
表2
表2中显示,在DC5-R50(16×)上的方法与可变形的方法表现相同DETR-R50(多尺度、8×)。考虑到单尺度可变形DETR-DC5-R50-SS的AP为41.5(低于43.8)(表1),可以看到,可变形的DETR受益于多尺度和高分辨率编码器。
本文方法的性能也与TSP-FCOS TSP-RCNN。这2种方法包含一个在少量选定位置/区域上的transformer编码器(在TSP-FCOS和TSP-RCNN区域提议中感兴趣的特性),而不使用transformer解码器是FCOS和Faster RCNN的扩展。
5参考
[1].Conditional DETR for Fast Training Convergence
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
重磅!目标检测交流群成立
扫码添加CVer助手,可申请加入CVer-目标检测微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看