机器学习——算法介绍-3
文章目录
- 算法分类
-
- sklearn数据集
- 数据集划分
- sklearn数据集划分API
- scikit-learn数据集API介绍
- 获取数据集返回的类型
- sklearn分类数据集
- 数据集进行分割
- 用于分类的大数据集
- sklearn回归数据集
- 想一下之前做的特征工程的步骤?
- sklearn机器学习算法的实现-估计器
- 估计器的工作流程
- 分类算法-k近邻算法
- 计算距离公式
- sklearn k-近邻算法API
- k近邻算法实例-预测入住位置
- 案例分析
- 数据的处理
- 实例流程
- 问题
- k-近邻算法优缺点
- k-近邻算法实现
- 分类模型的评估
- 混淆矩阵
- 为什么需要这些指标?
- 其他分类标准
- 分类模型评估API
- classification_report
- 分类算法-朴素贝叶斯算法
- 概率基础
- 联合概率和条件概率
- 朴素贝叶斯-贝叶斯公式 
- 训练集统计结果(指定统计词频):
- 拉普拉斯平滑
- sklearn朴素贝叶斯实现API
- MultinomialNB
- 朴素贝叶斯算法案例
- 朴素贝叶斯案例流程
- 朴素贝叶斯分类优缺点
- 模型的选择与调优
- 交叉验证过程
- 超参数搜索-网格搜索
- 超参数搜索-网格搜索API
- GridSearchCV
- K-近邻网格搜索案例
- 分类算法-决策树、随机森林
- 决策树
- 认识决策树
- 信息论的创始人
- 案例
- 信息和消除不确定性是相联系的
- 决策树的划分依据之一-信息增益
- 信息增益的计算
- 案例
- 常见决策树使用的算法
- sklearn决策树API
- 泰坦尼克号数据
- 泰坦尼克号乘客生存分类模型
- 获取数据
-
- 决策树的结构、本地保存
- 决策树的优缺点以及改进
- 集成学习方法-随机森林
- 集成学习方法
- 什么是随机森林
- 学习算法
- 为什么要随机抽样训练集?
- 为什么要有放回地抽样?
- 集成学习API
- 对单个决策树优化过程
- 随机森林的优点
- 思维导图
算法分类
1、sklearn数据集与估计器
2、分类算法-k近邻算法
3、k-近邻算法实例
4、分类模型的评估
5、分类算法-朴素贝叶斯算法
6、朴素贝叶斯算法实例
7、模型的选择与调优
8、决策树与随机森林
sklearn数据集
自带数据,可以直接使用,方便学习
1、数据集划分
2、sklearn数据集接口介绍
3、 sklearn分类数据集
4、 sklearn回归数据集
数据集划分
机器学习一般的数据集会划分为两个部分:
训练数据:用于训练,构建模型
测试数据:在模型检验时使用,用于评估模型是否有效
一般75%~25%的划分经过验证是合适的
sklearn数据集划分API
sklearn.model_selection.train_test_split
scikit-learn数据集API介绍
sklearn.datasets
加载获取流行数据集
datasets.load_*()
获取小规模数据集,数据包含在datasets里,不必下载文件
datasets.fetch_*(data_home=None)
获取大规模数据集,需要从网络上下载,函 数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
获取数据集返回的类型
load和fetch返回的数据类型datasets.base.Bunch(字典格式)
data:特征数据数组,是 [n_samples * n_features] 的二维numpy.ndarray 数
特征值,即特征的取值

target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
即特征的目标

DESCR:数据描述
即数据集的说明文字

feature_names:特征名,新闻数据,手写数字、回归数据集没有
即特征数据的列名
![]()
target_names:标签名
即目标值的名字
![]()
from sklearn.datasets import load_iris
iris = load_iris()
# 特征值
print("获得特征值")
print(iris.data)
print("获得目标值")
print(iris.target)
print("特征描述")
print(iris.DESCR)
print("特证名")
print(iris.feature_names)
print("标签名")
print(iris.target_names)
sklearn分类数据集
至于数据集的导入,如下,load_*格式
sklearn.datasets.load_iris()
加载并返回鸢尾花数据集
sklearn.datasets.load_digits()
加载并返回数字数据集
数据集进行分割
sklearn.model_selection.train_test_split(*arrays, **options)
输入参数
x 数据集的特征值
y 数据集的标签值
test_size 测试集的大小,一般为float
random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
返回值
训练集和测试集,先返回特征值,然后返回目标值
return 训练集特征值,测试集特征值,训练标签,测试标签
(默认随机取)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.25)
print(x_train,y_train)
print(x_test,y_test)
用于分类的大数据集
和load类似,也是获取数据的一种方式,只不过数据量更加庞大,会将文件下载到指定目录
如果不指定目录,会自动寻找当前目录下的data文件夹下是否有相应文件

sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
subset: ‘train’或者’test’,‘all’,可选,选择要加载的数据集.
训练集的“训练”,测试集的“测试”,两者的“全部”all
datasets.clear_data_home(data_home=None)
清除目录下的数据
news=fetch_20newsgroups(data_home='./data',subset='all')
print(news.target_names)

sklearn回归数据集
同理分类数据集
sklearn.datasets.load_boston()
加载并返回波士顿房价数据集
klearn.datasets.load_diabetes()
加载和返回糖尿病数据集
此时结果不再是类别,而是可连续的数值,训练的目的是求出一个预测值
想一下之前做的特征工程的步骤?
转换器和估计器
转换器,之前将文本数值化的时候实际上就是调用了转换器
1、实例化 (实例化的是一个转换器类(Transformer))
fit_transformer实际上是两个步骤
fit()实际上只是输入数据,其他的不做
transformer用来处理数据,例如平均值,方差等等,使用时一般一起使用
那什么时候分开用,什么时候一起用呢?
一旦fit和transformer分开,transformer只以当前fit为准,使用当前平均值,当前方差
因此如果是聚合的数据,直接一次性转换即可
对于离散没有关联的数据,可以分开转换
from sklearn.preprocessing import StandardScaler
a=StandardScaler()
mylist=[[1,2,4],[1,5,6]]
mylist1=[[2,4,5],[5,6,9]]
a.fit(mylist)
a.transform(mylist)
a.fit(mylist1)
a.transform(mylist)
第一次fit数据,平均值,方差等已经根据第一次fit的数据计算生成
![]()
第二次fit数据,平均值,方差等根据第二次的数据生成,虽然transform依然转换第一次的数据,但是因为和第一次fit的平均值不同,所以结果是不同的
第一次根据mylist生成标准差矩阵,fit的mylist列表

第二次根据mylist生成标准差矩阵,fit的mylist1列表,这里毫无疑问已经错误
![]()
2、调用fit_transform(对于文档建立分类词频矩阵,不能同时调用)
⽂章1,⽂章2 ⽂章3,⽂章4
fit⽂章1,⽂章2之后转换标准已经改变

python界面命令:deactivate 界面关闭,重新打开
workon xxx开辟新的空间编写命令
ipython命令行编辑python代码
sklearn机器学习算法的实现-估计器
在sklearn中,估计器(estimator)是一个重要的角色,分类器和回归器都属于estimator,是一类实现了算法的API
估计器就是结果估计器,就是对于问题求解的算法 实现,这些api的难点在于设置机器学习数据参数,这些参数是机器自己学习到的,
1、用于分类的估计器:
sklearn.neighbors k-近邻算法
sklearn.naive_bayes 贝叶斯
sklearn.linear_model.LogisticRegression 逻辑回归
2、用于回归的估计器:
sklearn.linear_model.LinearRegression 线性回归
sklearn.linear_model.Ridge 岭回归
估计器的工作流程

训练后,传入测试数据,需要评判模型的score,即对于结果预测的准确度
分类算法-k近邻算法
你的“邻居”来推断出你的类别,比如定位,你不知道自己的位置,但是你旁边的人拿出手机确定了他的位置,你可以模糊的认为这是你的位置,自然界有很多应用,比如物以类聚,人以群分,朴素观点
分类算法-k近邻算法(KNN)
定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
来源:KNN算法最早是由Cover和Hart提出的一种分类算法
计算距离公式
两个样本的距离可以通过如下公式计算,又叫欧式距离
结合我们之前讲的约会数据例子,在计算两个样本数据的距离时特征有什么影响?需要对数据做些什么?
需要对数据进行标准化,
sklearn k-近邻算法API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm=‘auto’)
n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
k的选择对结果很有影响,太大太小都会影响结果
假如有32个球,
比如k取样本数32,那判断无从谈起,如果k取太小,会受到身边异常值的影响,比如球身边有30个篮球,2个红球,k取2,把红球纳入了进去,结果肯定是有影响的
algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},可选用于计算最近邻居的算法:‘ball_tree’将会使用 BallTree,‘kd_tree’将使用 KDTree。‘auto’将尝试根据传递给fit方法的值来决定最合适的算法。 (不同实现方式影响效率)
k近邻算法实例-预测入住位置
facebook的位置预测案例
https://www.kaggle.com/c/facebook-v-predicting-check-ins/data

在本次比赛中,您将根据用户的位置、准确性和时间戳来预测用户签入的业务
训练和测试数据集基于时间拆分,测试数据中的公共/私人排行榜随机拆分。在这个数据集中没有人的概念。所有的 row_id 都是事件,而不是人。
注意:某些列(例如时间和准确性)在其定义中有意保留含糊不清。请将它们视为挑战的一部分。

文件说明
训练.csv,测试.csv
row_id:签到事件的id
xy:坐标
精度:定位精度
时间:时间戳
place_id:商家的id,这是你预测的目标
sample_submission.csv - 带有随机预测的正确格式的样本提交文件
案例分析
分类
特征值:x, y 坐标, 定位准确性,年,⽇,时,周
⽬标值:⼊住位置的地址id

处理:
1.由于数据量⼤,电脑太渣,只是演示的话,只取出一部分数据,缩小处理的数据范围,可以下,先对xy约束,0
3、⼏千~⼏万,少于指定签到⼈数的位置删除,
数据的处理
伪代码讲逻辑,实际代码说操作
读代码是一件十分恼人的事,事实上懂了代码的逻辑,再看代码就会舒服很多
我想也许业务都需要伪代码进行逻辑同步
1、缩小数据集范围
DataFrame.query()
相当于一个查询,可以过滤数据
2、处理日期数据
pd.to_datetime ()
参数:unit单元,可以规定转化的最小单位,s,ns,ms等等,即保留的最后一个单位
这里是将时间戳转化为日期形式

pd.DatetimeIndex
将日期数据字典化
3、增加分割的日期数据
重新确立新的特征
data[‘day’]=time_value.day
data[‘hour’]=time_value.hour
data[‘weekday’]=time_value.weekday
4、删除没用的日期数据
日期数据已经被转化为了其他特征,删除旧有数据
pd.drop
pandas的axis和其他的行列标志不同,这里1代表列,0代表行,这里删除列

5、将签到位置少于n个的目标地址删除
根据place_id进行分组
place_count=data.groupby(‘place_id’).count()
此时place_id是序号,因此同样的place_id已经合并了,其他列显示的是出现的次数

将非零的placeid进行分组
place_count =data.groupby(‘place_id’).aggregate(np.count_nonzero)
将placeid组中,用户签到次数小于3的踢出,表示此地并不受欢迎,索引重新从0开始计算
tf = place_count[place_count.row_id > 3].reset_index()
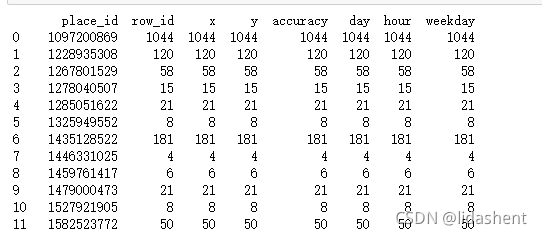
data = data[data[‘place_id’].isin(tf.place_id)]
data数据中只保留tf.place_id的数据
此时目标地址已经完成过滤
这里是分类算法,取出数据中的特征值,目标值
y=data[‘place_id’]
x=data.drop([‘place_id’],axis=1) axis为1时,这里代表列


数据预处理已经完成,接下来需要划分训练数据和测试数据,特征数据如上图所示
x_train,x_test,y_train,y_test=train_test_splite(x,y,test_size=0.25)
数据划分完毕,对两者的特征值都执行标准化
x_train=std.fit_transform(x_train)
x_test=std.fit_transform(x_test)
此时数据已经达到了可以进行训练的标准,即已经完成特征过滤,有效数据过滤,然后划分号训练和测试集,有效数据标准化
调用K近邻算法进行模型运算
knn=KNeighborsClassifier(n_neighbors=5)
knn.fit(x_train,y_train)
y_test_predict=knn.predict(x_test)
得到对于测试集预测的类别
![]()
由此可以通过比对预测值和真实值,得到模型的准确率评分
print(knn.score(x_test,y_test))
![]()
准确率不高和数据量,k的取值,特征保留的是否合理都有关系
完整代码
file_train=r"C:\Users\Administrator.DESKTOP-KMH7HN6\Downloads\myPython\data\facebook-v-predicting-check-ins\train.csv"
file_test=r"C:\Users\Administrator.DESKTOP-KMH7HN6\Downloads\myPython\data\facebook-v-predicting-check-ins\test.csv"
data=pd.read_csv(file_train)
print("开始打印原始数据")
print(data.head(10))
print("数据过滤")
data=data.query("x>1.0 & x<1.25 & y>2.5 & y<2.75")
print("处理时间数据,将时间戳转化为日期格式")
time_value=pd.to_datetime(data['time'],unit='s')
print(time_value)
print("将得到的日期分离,转化为字典格式得到其他特征")
time_value=pd.DatetimeIndex(time_value)
print(time_value)
#分离时间,重塑data特征
data['day']=time_value.day
data['hour']=time_value.hour
data['weekday']=time_value.weekday
#抛弃时间戳列
data=data.drop(['time'],axis=1)
print(data)
place_count=data.groupby('place_id').count()
print(place_count)
tf=place_count[place_count.row_id>3].reset_index()
print(tf)
y=data['place_id']
x=data.drop(['place_id'],axis=1)
print('目标值')
print(y)
print("特征值")
print(x)
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25)
std=StandardScaler()
x_train=std.fit_transform(x_train)
x_test=std.fit_transform(x_test)
knn=KNeighborsClassifier(n_neighbors=5)
knn.fit(x_train,y_train)
y_test_predict=knn.predict(x_test)
print(y_test_predict)
print(knn.score(x_test,y_test))
实例流程
1、数据集的处理
2、分割数据集
3、对数据集进行标准化
4、estimator流程进行分类预测
问题
1、k值取多大?有什么影响?
k值取很小:容易受异常点影响
k值取很大:容易受最近数据太多导致比例变化
2、性能问题?
每个样本都要计算与其他样本的距离,对于上亿的数据,时间复杂度很高
k-近邻算法优缺点
优点:
简单,易于理解,易于实现,无需估计参数,无需训练
无需估计参数:k值为超参数,这里所谓的参数可以理解为数据的权重,后面程序模型建立 的时候会自动估计
缺点:
懒惰算法,对测试样本分类时的计算量大,内存开销大
必须指定K值,K值选择不当则分类精度不能保证,因此需要频繁调整k值看结果
使用场景:小数据场景,几千~几万样本
一般不用,因为有其他的准确率更高,性能更优的选择
k-近邻算法实现
加快搜索速度——基于算法的改进KDTree,API接口里面有实现
在上面的api里有写
分类模型的评估
estimator.score()
一般最常见使用的是准确率,即预测结果正确的百分比
混淆矩阵
在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵(适用于多分类)

为什么需要这些指标?
精确率(Precision)与召回率(Recall)
精确率:预测结果为正例样本中真实为正例的比例(查得准)

召回率:真实为正例的样本中预测结果为正例的比例(查的全,对正样本的区分能力)
不要放过一个真正为正例的,这在疾病预警中很有用
在某些场景,比如医院,召回率比准确率更加重要

其他分类标准
,F1-score,反映了模型的稳健型
不能为了召回率,而忘记准确性,应该在同时将准确性提高
召回率表示有多少正确的被正确识别了

分类模型评估API
sklearn.metrics.classification_report
classification_report
sklearn.metrics.classification_report(y_true, y_pred, target_names=None)
y_true:真实目标值
y_pred:估计器预测目标值
target_names:目标类别名称
return:每个类别精确率与召回率
分类算法-朴素贝叶斯算法
1、概率基础
2、朴素贝叶斯介绍
概率基础
概率定义为一件事情发生的可能性
联合概率和条件概率
联合概率:包含多个条件,且所有条件同时成立的概率
记作:P(A,B)
P(A,B)=P(A)P(B)
条件概率:就是事件A在另外一个事件B已经发生条件下的发生概率
记作:P(A|B)
特性:P(A1,A2|B) = P(A1|B)P(A2|B)
注意:此条件概率的成立,是由于A1,A2相互独立的结果
即职业和体重在这里的相关性不大
案例

类似的文档分类,给出一篇文档,判定类别
实际上是进行了分词,给出的是一个词语列表,这些词是相互独立的
P(科技 |词1,词2,词3…),即在多个词语的条件下判断文章类别
朴素贝叶斯-贝叶斯公式 
公式分为三个部分:
P©:每个文档类别的概率(某文档类别词数/总文档词数)
P(W│C):给定类别下特征(被预测文档中出现的词)的概率
计算方法:P(F1│C)=Ni/N (训练文档中去计算)
Ni为该F1词在C类别所有文档中出现的次数
N为所属类别C下的文档所有词出现的次数和
P(F1,F2,…) 预测文档中每个词的概率
公式套用可以得到
P(科技 |词1,词2,词3…) = P(F1,f2,f3|科技)P(科技)
P(娱乐 |词1,词2….) = P(F1,f2,f3|娱乐)P(娱乐)
训练集统计结果(指定统计词频):
特征\统计 科技 娱乐 汇总(求和)

现有一篇被预测文档:出现了影院,支付宝,云计算,计算属于科技、娱乐的
类别概率?
思考:属于某个类别为0,合适吗?

拉普拉斯平滑
问题:从上面的例子我们得到娱乐概率为0,这是不合理的,如果词频列表里面
有很多出现次数都为0,很可能计算结果都为零
解决方法:拉普拉斯平滑系数
重新计算
平滑
α为指定的系数一般为1,m为训练文档中统计出的特征词个数
P(科技| 影院,⽀付宝,云计算) = P(影院,⽀付宝,云计算|科技)P(科技) =
((8+1)/(100+14))(20/100)(63/100)(30/90) = 0.00456109
P(娱乐| 影院,⽀付宝,云计算)=P(影院,⽀付宝,云计算|娱乐)P(娱乐)=
((56+1)/(121+14))((15+1)/(121+14))((0+1)/((121+14))(60/90) = 0.001
sklearn朴素贝叶斯实现API
sklearn.naive_bayes.MultinomialNB
MultinomialNB
sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
朴素贝叶斯分类
alpha:拉普拉斯平滑系数
这个并非超参数,对结果不会产生决定性影响,大小关系不会改变,只是零值被和谐了
而且准确性很难提高了,因为并没有超参数控制
受训练集影响很大,如果训练集的词语噪点很多,不具备代表性 ,那么结果肯定不好
朴素贝叶斯算法案例
sklearn20类新闻分类
20个新闻组数据集包含20个主题的18000个新闻组帖子
伪代码阐明逻辑
加载文档数据集
划分训练集和测试集
news=fetch_20newsgroups(‘all’)
x_train,x_test,y_train,y_test=train_test_split(news.data,news.target,test_size=0.25)
得到数据集后对文本数据进行数值化,使用TFIDF判断词的重要性,得到重要性数值矩阵
tf=TfidfVectorizer()
x_train=tf.fit_transform(x_train)
x_test=tf.transform(x_test)

使用朴素贝叶斯算法加载训练数据,训练好后加载测试数据得到预测值
mlt=MultinomialNB(alpha=1.0)
mlt.fit(x_train,y_train)
y_test_predict=mlt.predict(x_test)
查看正确率
print(mlt.score(x_test,y_test))
0.8501237186284907
查看每个类别的准确率和召回率
my_recalls=classification_report(y_test,y_test_predict,target_names=news.target_names)

完整代码
def naviebayes():
"""
朴素贝叶斯进行文本分类
:return: None
"""
news = fetch_20newsgroups(subset='all')
# 进行数据分割
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)
# 对数据集进行特征抽取
tf = TfidfVectorizer()
# 以训练集当中的词的列表进行每篇文章重要性统计['a','b','c','d']
x_train = tf.fit_transform(x_train)
print(tf.get_feature_names())
x_test = tf.transform(x_test)
# 进行朴素贝叶斯算法的预测
mlt = MultinomialNB(alpha=1.0)
print(x_train.toarray())
mlt.fit(x_train, y_train)
y_predict = mlt.predict(x_test)
print("预测的文章类别为:", y_predict)
# 得出准确率
print("准确率为:", mlt.score(x_test, y_test))
print("每个类别的精确率和召回率:", classification_report(y_test, y_predict, target_names=news.target_names))
return None
朴素贝叶斯案例流程
1、加载20类新闻数据,并进行分割
2、生成文章特征词
3、朴素贝叶斯estimator流程进行预估
朴素贝叶斯分类优缺点
优点:
朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
(起源于数学理论,非常稳定)
对缺失数据不太敏感,算法也比较简单,常用于文本分类。
分类准确度高,速度快
缺点:
需要文章的单词都是独立性的,这是假设条件前提,事实上有关联,因此不太靠谱
需要知道先验概率P(F1,F2,…|C),因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
模型的选择与调优
1、交叉验证
2、网格搜索
交叉验证:为了让被评估的模型更加准确可信
交叉验证过程
交叉验证:将拿到的数据,分为训练和验证集。以下图为例:将数据分
成5份,其中一份作为验证集。然后经过5次(组)的测试,每次都更换不同
的验证集。即得到5组模型的结果,取平均值作为最终结果。又称5折交叉
验证。
防止只做一次数据,结果的偶然性影响
得到四个模型的准确率平均值,使得结果更加可信

超参数搜索-网格搜索
通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),
这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组
合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建
立模型。
超参数的设置就像调音器一样,只有经过不断的尝试参数,才能得到最适合的旋律

如果存在三个超参数空位,有10个参数,那么就三三组合,尝试所有的类型
⽹格搜索:调参数 K-近邻:超参数K
a [2,3,5,8,10] b [20,70,80] 两两组合 15次组合
超参数搜索-网格搜索API
cv:cross validation
sklearn.model_selection.GridSearchCV
GridSearchCV
sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
对估计器的指定参数值进行详尽搜索
estimator:估计器对象
param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}
cv:指定几折交叉验证
fit:输入训练数据
score:准确率
结果分析:
best_score_:在交叉验证中测试的最好结果
best_estimator_:最好的参数模型
cv_results_:每次交叉验证后的测试集准确率结果和训练集准确率结果
K-近邻网格搜索案例
将前面的k-近邻算法案例改成网格搜索
即对于参数指定使用数组代替,不再具体指定,算法会返回最好的k值应该取谁
指定估计器,k参数数组,几折交叉验证
param={‘n_neighbors’:[2,3,5]}
gc=GridSearchCV(knn,param_grid=param,cv=4)
gc.fit(x_train,y_train)
对测试集进行评估模型得分
gc.score(x_test,y_test)
0.3940831074977416
查看表现最好的模型
print(gc.best_estimator_)

查看表现最好的模型得分
0.3664357777443156
比测试集的分数低,是因为这里取得应该是平均值吧,测试集数据存在偶然性
查看每次交叉验证的结果
print(gc.cv_results_)
看下图,为了简便计算,k只设置了3,5,10三个参数,每次交叉验证设置为2
从split0_test_score开始看验证
通过输入三个参数得到各自的准确率平均值

交叉验证求得分

计算得到平均值,10表现最好

完整代码
def knncls():
"""
K-近邻预测用户签到位置
:return:None
"""
# 读取数据
data = pd.read_csv("./data/FBlocation/train.csv")
# print(data.head(10))
# 处理数据
# 1、缩小数据,查询数据晒讯
data = data.query("x > 1.0 & x < 1.25 & y > 2.5 & y < 2.75")
# 处理时间的数据
time_value = pd.to_datetime(data['time'], unit='s')
print(time_value)
# 把日期格式转换成 字典格式
time_value = pd.DatetimeIndex(time_value)
# 构造一些特征
data['day'] = time_value.day
data['hour'] = time_value.hour
data['weekday'] = time_value.weekday
# 把时间戳特征删除
data = data.drop(['time'], axis=1)
print(data)
# 把签到数量少于n个目标位置删除
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
# 取出数据当中的特征值和目标值
y = data['place_id']
x = data.drop(['place_id'], axis=1)
# 进行数据的分割训练集合测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 特征工程(标准化)
std = StandardScaler()
# 对测试集和训练集的特征值进行标准化
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 进行算法流程 # 超参数
knn = KNeighborsClassifier()
# # fit, predict,score
# knn.fit(x_train, y_train)
#
# # 得出预测结果
# y_predict = knn.predict(x_test)
#
# print("预测的目标签到位置为:", y_predict)
#
# # 得出准确率
# print("预测的准确率:", knn.score(x_test, y_test))
# 构造一些参数的值进行搜索
param = {"n_neighbors": [3, 5, 10]}
# 进行网格搜索
gc = GridSearchCV(knn, param_grid=param, cv=2)
gc.fit(x_train, y_train)
# 预测准确率
print("在测试集上准确率:", gc.score(x_test, y_test))
print("在交叉验证当中最好的结果:", gc.best_score_)
print("选择最好的模型是:", gc.best_estimator_)
print("每个超参数每次交叉验证的结果:", gc.cv_results_)
return None
分类算法-决策树、随机森林
决策树
1、认识决策树
2、信息论基础-银行贷款分析
3、决策树的生成
4、泰坦尼克号乘客生存分类
认识决策树
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法
信息论的创始人
香农是密歇根大学学士,麻省理工学院博士。
1948年,香农发表了划时代的论文——通信的数学原理,奠定了现代信息论的基础
信息的单位:比特
决策树的依据就在这里
案例
假如有32个球队,每个人下赌注,怎样才能猜对哪支球队是冠军?
32支球队,log32=5比特 底为2
64支球队,log64=6比特
信息熵
如果概率未知,假设每只球队获胜的概率相同,那么信息熵是
H=-(1/32 log(1/32)+…)=-1log(1/32)=log32=5
那么,如果根据以往球队的战绩,会发现每只球队实力不均衡,有的球队获胜率可以达到1/5,此时因为信息不同,信息熵将会降低,预测就会逼近准确更近
“谁是世界杯冠军”的信息量应该比5比特少。香农指出,它的准确信息量应该是:
H = -(p1logp1 + p2logp2 + … + p32log32)
为什么加负号呢?因为log本身的属性,让他小于1时取值为负数,而每个信息概率不可能大于1
H的专业术语称之为信息熵,单位为比特。
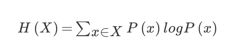
当这32支球队夺冠的几率相同时,对应的信息熵等于5比特,不同时,信息熵将会降低
这里信息熵的应用还有文件压缩等等,可以预估数据的未知可能性
信息和消除不确定性是相联系的
信息熵越大,不确定性越高
那么信息熵对于决策树的作用?
其实就是这个条件对于整体的影响大小,条件的影响性是主次降低的,可以降低信息熵,让不确定性更小
决策树的划分依据之一-信息增益
特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,即公式为
![]()
注:信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度
信息增益的计算
结合前面的贷款数据来看我们的公式:
信息熵的计算:
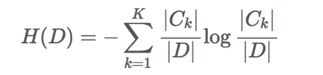
条件熵的计算:·
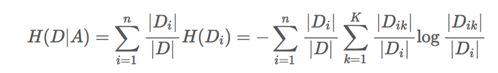
注:C_k表示属于某个类别的样本数,
案例
银行贷款数据

求得年龄的信息熵
g(D, 年龄) = H(D) - H(D’|年龄) =0.971- [1/3H(⻘年)+1/3H(中年)+1/3H(⽼年)]=
H(⻘年) = -(2/5log(2/5)+ 3/5log(3/5))
H(中年) = -(2/5log(2/5)+ 3/5log(3/5))
H(⽼年) = -(4/5log(4/5)+ 1/5log(1/5))

常见决策树使用的算法
ID3
信息增益 最大的准则
C4.5
信息增益比 最大的准则
CART
回归树: 平方误差 最小
分类树: 基尼系数 最小的准则 在sklearn中可以选择划分的原则,划分的更加细致
sklearn决策树API
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
决策树分类器
criterion:默认是’gini’系数,也可以选择信息增益的熵’entropy’
max_depth:树的深度大小
random_state:随机数种子
method:
decision_path:返回决策树的路径
泰坦尼克号数据
在泰坦尼克号和titanic2数据帧描述泰坦尼克号上的个别乘客的生存状态。在泰坦尼克号的数据帧不包含从剧组信息,但它确实包含了乘客的一半的实际年龄。关于泰坦尼克号旅客的数据的主要来源是百科全书Titanica。这里使用的数据集是由各种研究人员开始的。其中包括许多研究人员创建的旅客名单,由Michael A. Findlay编辑。
我们提取的数据集中的特征是票的类别,存活,乘坐班,年龄,登陆,home.dest,房间,票,船和性别。乘坐班是指乘客班(1,2,3),是社会经济阶层的代表。
其中age数据存在缺失。

泰坦尼克号乘客生存分类模型
得到数据
1、pd读取数据
获取数据
titan = pd.read_csv(r"C:\Users\Administrator.DESKTOP-KMH7HN6\Downloads\myPython\data\titanic\tested.csv")
处理数据
2、选择有影响的特征,处理缺失值
x = titan[[‘pclass’, ‘age’, ‘sex’]]

y = titan[‘survived’]
年龄平均数填充
inplace表示允许平均值替换,false表示不替换
x[‘age’].fillna(x[‘age’].mean(), inplace=True)

数据和特征基本处理好后开始划分训练集和数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
3、进行特征工程,pd转换字典,特征抽取
x_train.to_dict(orient=“records”)
orient="records"的意思是键值对转化,每一行的数据,列名代表键,数值代表值
最后变成一个二维表格
对数据集进行独热编码,因为计算机并不能识别性别,工作,年龄信息
为什么先分割再转化独热编码?不能提前分好然后分割数据集吗?
实际生活中,都是先有训练数据集,而测试数据集都是未知的,又如何能一起转化呢?
因为年龄是填充的,这样分割有利于制造差别判定
一般都是先切割数据,再进行转化
dict = DictVectorizer(sparse=False)
x_train = dict.fit_transform(x_train.to_dict(orient=“records”))
x_test = dict.transform(x_test.to_dict(orient=“records”))
测试集数据结果

模型训练
4、决策树估计器流程
调用决策树模型
dec = DecisionTreeClassifier()
max_depth=12可以规定决策树的深度等等参数,这是一个超参数
喂食训练数据
dec.fit(x_train, y_train)
获得准确率得分
dec.score(x_test, y_test)
决策树的结构、本地保存
1、sklearn.tree.export_graphviz() 该函数能够导出DOT格式
tree.export_graphviz(estimator,out_file='tree.dot’,feature_names=[‘’,’’])
export_graphviz(dec,out_file=‘tree.dotl’,feature_names=[‘age’,“pclass”,“female”,“male”])
导出的是二进制格式,需要借助工具查看
2、工具:(能够将dot文件转换为pdf、png)
安装graphviz
ubuntu:sudo apt-get install graphviz Mac:brew install graphviz
3、运行命令
然后我们运行这个命令
$ dot -Tpng tree.dot -o tree.png
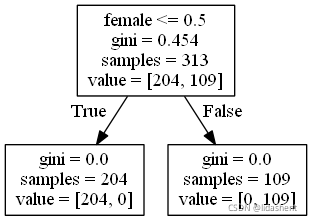
如果数据非常复杂,那么树非常庞大
pd也可从本地和网络中寻找数据
# 获取数据
titan = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt")
# 处理数据,找出特征值和目标值
x = titan[['pclass', 'age', 'sex']]
y = titan['survived']
print(x)
# 缺失值处理
x['age'].fillna(x['age'].mean(), inplace=True)
# 分割数据集到训练集合测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 进行处理(特征工程)特征-》类别-》one_hot编码
dict = DictVectorizer(sparse=False)
x_train = dict.fit_transform(x_train.to_dict(orient="records"))
print(dict.get_feature_names())
x_test = dict.transform(x_test.to_dict(orient="records"))
# print(x_train)
# 用决策树进行预测
# dec = DecisionTreeClassifier()
#
# dec.fit(x_train, y_train)
#
# # 预测准确率
# print("预测的准确率:", dec.score(x_test, y_test))
#
# # 导出决策树的结构
# export_graphviz(dec, out_file="./tree.dot", feature_names=['年龄', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', '女性', '男性'])
决策树的优缺点以及改进
优点:
简单的理解和解释,树木可视化。
需要很少的数据准备,其他技术通常需要数据归一化,
缺点:
决策树学习者可以创建不能很好地推广数据的过于复杂的树,这被称为过拟合。
决策树可能不稳定,因为数据的小变化可能会导致完全不同的树被生成
改进:
减枝cart算法(决策树api提供了此方法,后面说参数调优优化)(如果训练中某个分类被分到的样本很少,就剪掉,主要针对叶子节点)
随机森林
在企业决策方面,决策树具备很好的数据分析能力,在决策过程中应用很多
集成学习方法-随机森林
1、什么是随机森林
2、随机森林的过程、优势
4、泰坦尼克号乘客生存分类分析
集成学习方法
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。
什么是随机森林
定义:在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
例如, 如果你训练了5个树, 其中有4个树的结果是True, 1个数的结果是False, 那么最终结果会是True.
学习算法
根据下列算法而建造每棵树:
用N来表示训练用例(样本)的个数,M表示特征数目。
输入特征数目m,用于确定决策树上一个节点的决策结果;其中m应远小于M。
从N个训练用例(样本)中以有放回抽样的方式,取样N次,形成一个训练集(即bootstrap取样),并用未抽到的用例(样本)作预测,评估其误差。

由此,建立了N个决策树,对每一个结果有m种结果,
为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的
为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
集成学习API
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None)
随机森林分类器
n_estimators:integer,optional(default = 10) 森林里的树木数量
criteria:string,可选(default =“gini”)分割特征的测量方法
max_depth:integer或None,可选(默认=无)树的最大深度
——max_teatures="auto"每个决策树的最大特征数量,特征多了容易过拟合

bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样
对单个决策树优化过程
使用随机森林估计器
rf=RandomForestClassifier(n_job=-1)
使用网格搜索和交叉验证调用随机森林估计器
指定森林中树木数量和树的深度
param={“n_estimatore”:[120,200,300,500,800,1200],“max_depth”:[5,8,15,25,30]}
gc=GridSearchCV(rf,param_grid=param,cv=2)
调用随机森林算法
喂食数据,求出得分与参数最好的模型
rf=RandomForestClassifier(n_jobs=-1)
param={“n_estimatore”:[120,200,300,500,800,1200],“max_depth”:[5,8,15,25,30]}
gc=GridSearchCV(rf,param_grid=param,cv=2)
gc.fit(x_train,y_train)
print(gc.score(x_test,y_test))
print(gc.best.params_)

随机森林并不能像决策树一样可以导出了,单个树决策树可以导出
完整代码
def decision():
"""
决策树对泰坦尼克号进行预测生死
:return: None
"""
# 获取数据
titan = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt")
# 处理数据,找出特征值和目标值
x = titan[['pclass', 'age', 'sex']]
y = titan['survived']
print(x)
# 缺失值处理
x['age'].fillna(x['age'].mean(), inplace=True)
# 分割数据集到训练集合测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 进行处理(特征工程)特征-》类别-》one_hot编码
dict = DictVectorizer(sparse=False)
x_train = dict.fit_transform(x_train.to_dict(orient="records"))
print(dict.get_feature_names())
x_test = dict.transform(x_test.to_dict(orient="records"))
# print(x_train)
# 用决策树进行预测
# dec = DecisionTreeClassifier()
#
# dec.fit(x_train, y_train)
#
# # 预测准确率
# print("预测的准确率:", dec.score(x_test, y_test))
#
# # 导出决策树的结构
# export_graphviz(dec, out_file="./tree.dot", feature_names=['年龄', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', '女性', '男性'])
# 随机森林进行预测 (超参数调优)
rf = RandomForestClassifier(n_jobs=-1)
param = {"n_estimators": [120, 200, 300, 500, 800, 1200], "max_depth": [5, 8, 15, 25, 30]}
# 网格搜索与交叉验证
gc = GridSearchCV(rf, param_grid=param, cv=2)
gc.fit(x_train, y_train)
print("准确率:", gc.score(x_test, y_test))
print("查看选择的参数模型:", gc.best_params_)
return None
随机森林的优点
呵呵,没有缺点,如果有,那就是参数设置需要花点时间寻找合适的
在当前所有算法中,具有极好的准确率
能够有效地运行在大数据集上
能够处理具有高维特征的输入样本,而且不需要降维
能够评估各个特征在分类问题上的重要性
对于缺省值问题也能够获得很好得结果
思维导图