【论文随笔2】COALA: Co-Aligned Autoencoders for Learning Semantically Enriched Audio Representations
原文链接:【论文随笔2】COALA: Co-Aligned Autoencoders for Learning Semantically Enriched Audio Representations - 知乎零----相关背景Contrastive loss(对比损失)Contrastive loss的目标是:同类相吸,异类相斥。 本文提到的Contrastive loss又叫“ NT-Xent loss” (Normalized Temperature-Scaled Cross-Entropy Loss),源于SimCL… https://zhuanlan.zhihu.com/p/373406425
https://zhuanlan.zhihu.com/p/373406425
零----相关背景
Contrastive loss(对比损失)
Contrastive loss的目标是:同类相吸,异类相斥。
本文提到的Contrastive loss又叫“NT-Xent loss” (Normalized Temperature-Scaled Cross-Entropy Loss),源于SimCLR。计算示例如下【1】:
首先,拿出同一批训练样本中的每一对:

图 1
然后,使用 函数来得到两张图片相似的概率:
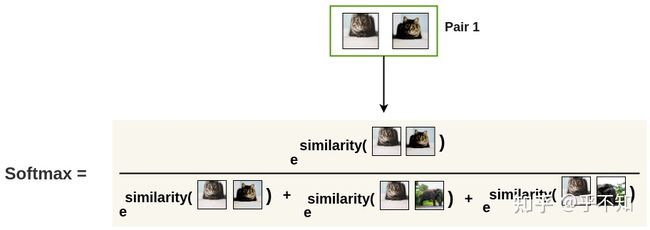
图 2
输出的概率值作为pair1中,第二张猫的照片与第一张猫的照片相似的概率。因此,这一batch中所有剩下的图片,都会被当作不相似图片(负对)进行采样。
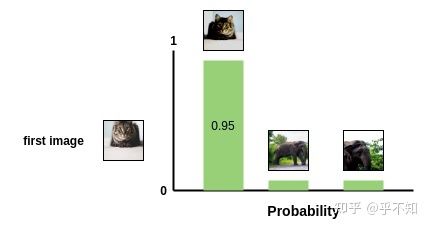
图 3:softmax 输出的结果。
图 2 中的 similarity 的具体算法为:

图 4:similarity 的计算方式,其中 z 是模型学习到的隐藏层向量。
其中, 是可调温度参数,可缩放余弦相似度的范围到 , 是向量的范数。
然后,对图2中的公式取负的log作为损失值 :
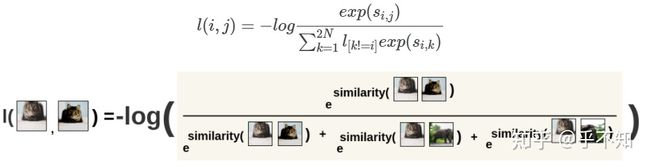
图 5
这里为什么是?batch最开始是 个图像(1,2...,N),经过数据增强,第1张图像变成2张(1a,1b),第2张图像变成2张(2a,2b)。对于1a的同类是谁?是1b。对于1a的异类是谁?是除1b在 中之外的所有图片【2】。
所以图5的公式中,分子是 和 的相似度,分母应该是 和 所有的除了 本身的样本的相似度。以1a,1b为例,假设有(1a,1b),(2a,2b),(3a,3b)等样本,那么,分子是(1a,1b)的相似度,分母应该是(1a,1b)+(1a,2a)+(1a,2b)+(1a,3a)+(1a,3b)
当同一对内两个图片得位置互换时,我们将再次计算其损失:

图 6:The positions of the images in the same pair are interchanged.
最终,计算所有对(pair)的损失,取平均,得“NT-Xent loss”:
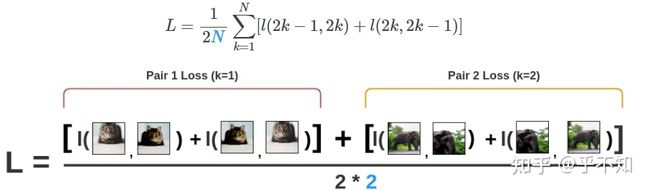
图 7:假设 batch_size=2,由于同一pair内,正反都需要计算,同一个pair算2次,所以再除以2.
基于这个损失函数,模型学习到的表示特征,将会实现将相似的图像特征在空间中靠近。
壹----正文
“COALA: Co-Aligned Autoencoders for Learning Semantically Enriched Audio Representations”:基于DNN的音频表示学习往往需要大量的有标注数据,这需要很大的成本。此文提出了一个将隐层的音频表示与其对应的标签相对齐的方法,以学习声音的声学和语义特征。对齐操作是通过使用对比损失,以最大化音频和标签的表示的一致性来完成的。此文在3个不同的任务(namely, sound event recognition, music genre and musical instrument classification)上,评估了所提出的方法训练出来的特征提取模型的性能。
https://arxiv.org/pdf/2006.08386.pdfarxiv.org/pdf/2006.08386.pdf
xavierfav/coalagithub.com/xavierfav/coala正在上传…重新上传取消
1. 引言(Introduction)
基于音频的机器学习模型经常使用人工设定的特征进行训练,这些特征是依靠心理声学和信号处理专家知识精心设计的。基于DNN的模型往往需要大量的标注数据,才能学习到这些音频的有效特征。最近的一些方法采用自监督模型,致力于从大量的无标签多媒体数据中,学习音频的表示。其中,有些方法利用图像及其相关标签,通过对齐自编器来学习基于内容的表示。这种通过优化交叉重建目标的对齐方式,对于学习数据表示而言,可能过于复杂。
此文想训练一个通用的音频表示提取器,而不是局限于某一特定的音频域。所以,此文利用了网络上的大量音频记录和它们对应的标签,采用对比损失(contrastive loss)将音频片段的声学表示,与标签数据中的语义表示进行对齐,进行跨模态的融合。
2. 方法(Proposed method)
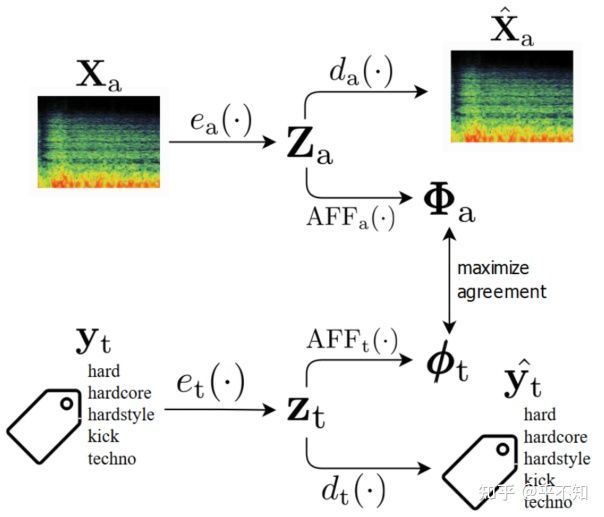
图 8:Illustration of our proposed method. Za and zt are aligned through maximizing their agreement and, at the same time, are used for reconstructing back the original inputs.
2.1) 模型结构
模型主体如图1所示,由两个自编码器构成。
上面的分支,音频自编码器中, 是潜层的音频表示, ,所以 是卷积块的输出。其他信息:
- 输入: 是频谱,具体为log mel-band energies;
- 输出: 是重构出来的频谱;
- 损失函数:KL散度, 。
下面的分支,标签自编码器中, 是输入音频 的标签的潜层表示,
- 输入: 是与音频数据 对应的多热编码向量(multi-hot encoding), ,其中, 是类别数目;
- 输出: 是重构出来的多热标签向量;
- 损失函数:交叉熵, , 是cross-entropy function。
2.2) 对齐声学和语义特征
此文的主要目标之一是将语义信息从标签的潜在表示中,注入到学习到的音频声学特征中,即将音频信号的表示 ,和标签的表示 ,两者进行对齐。由于标签可能覆盖不到音频的某些信息,或者由于标签本身存在错误或信息不丰富,这个对齐的任务将充满挑战。因此,此文使用了两个仿射变换【4】( ),并对齐这些变换的输出。仿射变换由一个全连接层实现即可。
然后,音频分支的表示输出 是一个矩阵,所以会被展平为一个向量 。然后与标签的表示向量 ,基于对比损失(contrastive loss)计算损失值。

图 9:最后的损失函数由3部分组成,详细表述可见原文。
3. 结论(Conclusion)
1)文中提出的方法,学习出来的声学表示特征,比MFCC好;
2)低级声学特征可能更适用于乐器分类,并且自编码器中重构目标的存在,会使得模型更倾向于学习低级的声学特征,以更容易地重构目标;
Our assumption is that recognizing musical instruments can be more easily done using lower-level features reflecting acoustic characteristics of the sounds, and that the reconstruction objective imposed by the autoencoder architecture is forcing the embedding to reflect low-level characteristics present in the spectrogram.
3)对于城市声音或者音乐流派相关的任务,语义信息是很有用的;
However, for recognizing urban sounds or musical genres, a feature that reflects mainly semantic information is needed, which seems to be learned successfully when considering the contrastive objective.
4)此文提出的方法,在小规模数据集上的表现也不错,虽然还不如基于OpenL3的结果;
This shows that our approach which only takes advantage of small-scale content with their original tag metadata is very promising for learning competitive audio features.
5)重构目标能使得模型学习反映音频信号的某些低级声学特征,使得模型其更具有通用性。
This suggests that the reconstruction objective enables to learn features that reflect some low-level acoustic characteristics of audio signals, which makes it more valuable as a general-purpose feature.
References
【1】The Illustrated SimCLR Framework
【2】nachifur:深入剖析SimCLR
【3】千佛山彭于晏:《Contrastive Learning for Visual Representation》笔记
【4】https://en.wikipedia.org/wiki/A