RSE2021/云检测:基于小波变换和连续多尺度空间注意的上下块深度网络云检测
RSE2021/云检测Deep network based on up and down blocks using wavelet transform and successive multi-scale spatial attention for cloud detection基于小波变换和连续多尺度空间注意的上下块深度网络云检测
- 0.摘要
- 1.概述
- 2.方法
- 3.背景
- 4.实验数据
- 5.我们的方法
-
- 5.1.UD-NET
-
- 5.1.1.Down Block
- 5.1.2.Up Block
- 5.2.UDI-Net
- 5.3.暗通道先验
- 5.4.AUDI-Net
- 6.讨论
-
- 6.1.评价指标
- 6.2.UD-Net表现评估
-
- 6.2.1.云检测中UD-Net的定量分析
- 6.2.2.云检测中UD-net的定性分析
- 6.3.UDI-Net性能评估
-
- 6.3.1.UDI-Net在云检测中的定量分析
- 6.3.2.UDI-Net在云检测中的定性分析
- 6.4.AUDI-Net表现评估
-
- 6.4.1.AUDI-Net在云检测中的定量分析
- 6.4.2.AUDI-Net在云检测中的定性分析
- 7.总结
0.摘要
云检测不仅是一项具有挑战性的任务,而且在图像处理中起着重要作用。由于云的多样性和下垫面的复杂性,目前大多数云检测方法仍然面临着巨大的挑战,特别是在检测薄云方面。为此,我们提出了一种检测高分一号WFV图像中云像素的方法。该方法采用深度网络对多尺度全局特征进行学习,将特征学习过程中获得的高级语义信息与低级空间信息相结合,将图像划分为云区域和非云区域。此外,利用Haar小波变换设计Up和Down块,充分利用图像的结构信息,特别是云的纹理信息,可以有针对性地学习。我们关注图像的原始信息,以辅助网络的学习。此外,我们还利用暗通道先验,通过在网络中的多尺度特征图中添加注意机制,设计了一个连续多尺度空间注意模块,以提供持续的性能改进。实验结果表明,该网络在不同场景下都具有良好的性能
1.概述
云在光学遥感影像中的存在是不可避免的,限制了地面信息提取影像的发展。为了有效地提高遥感影像的利用率,云检测起着非常重要的作用。到目前为止,研究人员已经开发了各种用于遥感图像云检测的算法。越来越多的深度学习网络被报道在云检测领域。云检测是一个像素级的预测任务,旨在标记场景的每个像素,不管它是否是云。然而,目前的算法对于云边界和纹理特征弱、强度低的大片薄云效果较差。其中,传统算法容易受到土地覆盖类型、气候条件等因素的影响。因此,在实际应用中仍存在许多挑战。深度神经网络可以自动提取云的特征,但提取的是什么很难解释。在学习过程中,部分时间浪费在无用的信息提取上。在图像处理中,小波变换起着非常重要的作用(Guo and Li, 2013;库马尔等人,2014;Dagadu等,2016;张等,2017;赵,2016)。自1984年(Grossmann and Morlet, 1984)首次提出以来,小波已经成为信号处理的强大工具。小波分析被认为是傅里叶分析的一个突破。由于小波变换具有良好的时频局部特性和缩放特性,卷积神经网络具有较强的适应性和鲁棒性,小波和神经网络可以共同提高深度学习方法的性能。本文提出了一种新的云检测方法,该方法利用深度学习网络灵活融合多尺度特征,特别是暗通道先验特征。此外,还引入了空间注意,利用小波变换充分提取遥感图像的纹理特征
2.方法
通过对云的光谱、颜色、纹理、形状特征、空间上下文信息等因素的定量分析,可以对遥感图像中的云进行检测。通过云探测,可以区分道路、建筑物、水、雪和其他土地覆盖类型的地区的厚云和薄云。我们回顾了进展开发云检测任务。传统的算法依靠阈值分割来进行分割,在某些特定的情况下,我们得到了很好的检测结果,但它依赖于研究者的专业知识和大量的重复测试(Jedlovec et al., 2008)。因此,阈值算法具有较长的研究周期。阈值方法主要基于云和晴空像素的反射率谱,通过特定阈值利用单波段或多波段的辐射差异来区分云和晴空像素。这种方法有很多,例如ISCCP云掩码算法(Rossow and Garder, 1993)、APOLLO (AVHRR Processing scheme Over Clouds, Land and Ocean)方法(Kriebel et al., 2003)、应用于Landsat-7 ETM +数据的Fmask方法等(Zhu et al., 2015)。一般来说,阈值法可以有效识别大部分地区的厚云。然而,当出现稀薄的云、破碎的云像素或沙漠、岩石和人工表面时,很难将阈值设置为合理的值。由于地表结构的复杂性和大气影响的不确定性,阈值设置不当往往会导致大量的误检。此外,形状和纹理特征被用于云检测(Lin et al., 2010;张等人,2019)。由于计算机技术的快速发展,机器学习给研究人员提供了另一个想法,即依靠计算机强大的计算能力来执行复杂的计算。Xu等人使用决策树提取云边界(Xu et al., 2013)。Hu等人将随机森林方法与计算机图像处理相结合,以获得云掩模图(Hu等人,2015)。Yuan和其他研究人员使用支持向量机来区分云和非云区域(Yuan和Hu, 2015)。随着深度学习在图像识别、分类和图像分割等方面的快速发展,基于深度学习的云检测方法得到了广泛的应用。研究人员提出了大量的网络结构来提高云检测的准确性。Xie等人提出了一种结合了超像素算法和卷积神经网络的云检测方法(Xie等人,2017)。Zi等人提出了一种基于PCANet的云检测方法(Zi等人,2018)。MSCFF算法由Li等人提出,对高分1和Landsat- 8等不同数据集都取得了良好的检测精度(Li等人,2019)。此外,Yan等人在网络中引入了金字塔池,提出了MFFSNet算法,不仅在厚云和雪中具有较高的检测精度,在薄云和云阴影中也具有较高的检测精度(Yan et al., 2018)。Jacob等人提出了具有编码器-解码器卷积神经网络结构的遥感网络(RS-Net),该网络在遥感图像中的云检测方面表现良好(Jeppesen et al., 2019)。提出了一种新的用于GF-5预览RGB图像云分割的双分支CNN架构(MFGNet),该架构引入了金字塔-中间池注意力和空间注意力,以提取浅层和深层信息(Yu等人,2020)。Li等人最近提出了一种基于弱监督深度学习的云检测(WDCD)方法(Li et al., 2020)。Zhang等人在暗通道子网的空间注意模块的基础上,设计了Gabor变换模块和通道注意模块,以加强网络对纹理特征和暗通道特征的学习(Zhang等人,2020)。构建卷积神经网络的深度学习算法一直被认为效率更高。
3.背景
卷积神经网络(CNNs) (Lecun et al., 1998;Sermanet et al., 2013;Simonyan和Zisserman, 2014;Szegedy et al., 2015)是一种高效的端到端深度分层特征学习模型,可以捕获高分辨率卫星图像的内在特征,已被证明在计算机视觉中是有效的,例如目前关于云检测的任务。自动特征提取被认为是对以前的方法的主要改进,以前的方法都是手动形成的。云检测的本质是语义分割。Shelhamer和Long提出的全卷积网络(FCN)已广泛应用于图像语义分割(Shelhamer et al., 2017)。这些语义信息可以通过使用一系列卷积层生成精确而详细的分割映射。直接将特征图放大到原始尺寸的方法过于粗糙,即不能足够精确地检测到目标的边界。相比之下,编码器-解码器网络表现出更好的性能,已成功应用于许多计算机视觉任务,如人体姿态估计(Newell等人,2016),目标检测(Lin等人,2017;Shrivastava等人,2016)和语义分割(Peng等人,2017;Giusti等,2013;古尔德等人,2009年;Pinheiro和Collobert, 2014;波伦等,2017;戴等,2017;Russakovsky等,2015;Schwing和Urtasun, 2015;Sermanet et al., 2013)。许多解决方案,如SegNet (Ronneberger et al., 2015)、U-Net (Badrinarayanan et al., 2017)、RS-Net等被用于语义分割。该译码器路径采用对称结构和给定的编码器路径,其中使用了一系列的上采样层和卷积层。这种结构的本质是编码器路径使用学习到的特征来恢复解码阶段目标的位置。注意,改变特征映射大小的过程(使用池化和插值)不是最优的。因此,我们提出了一些模块来改进该方法。深度学习神经网络的特点是需要计算的参数很多,随着参数数量的增加,网络训练时间也随之增加

图1所示。说明核大小为3 ×3和不同速率的Atrous卷积(6,12,18)。标准卷积对应于速率为1的Atrous卷积。采用大的空洞率值,扩大了模型的视场,实现了多尺度的目标编码
为了在不增加网络参数数量的前提下,在卷积过程中扩大接受域,设计了Atrous卷积。同时,它可以解决更大的特征图分辨率和更大的接受域之间的矛盾需求(Chen et al., 2017)。通过在适当的位置插入零,一个核可以以不同的速率旋转。阿特鲁卷积显式地调整了滤波器的视场,有效地扩大了滤波器的视场,以便在不增加参数数量或计算量的情况下合并更大的上下文。提出了Atrous空间金字塔池(ASPP),将不同膨胀率的Atrous卷积生成的特征图进行串联,使输出特征图中的神经元包含多个接受野大小,编码多尺度信息,最终提高性能(Chen et al., 2018)。换句话说,它用多个有效视场互补的过滤器探测原始图像,从而在多个尺度上捕捉物体以及有用的图像上下文。图1显示了atrous卷积的图解
近年来,关注机制逐渐成为深度学习中最热门的方法和研究问题之一。它已广泛应用于识别、语音识别和自然语言处理等领域。先前的文献对注意机制的意义进行了广泛的研究(Mnih et al., 2014;Ba et al., 2014;Bahdanau et al., 2014;徐等,2015;Gregor等,2015;Jaderberg等人,2015)。它改进了源语言的表达方式,并在解码过程中动态地选择与源语言相关的信息,从而显著地改善了基本编码器-解码器框架的不足。也就是说,它不仅表明了关注的重点,而且还改进了信息的表示。Oktay提出了注意力u - net,并设计了注意力门模块来增强相关区域(Oktay等人,2018)。受到(Hu et al., 2018)的启发,提出了卷积块注意模块(Convolutional Block Attention Module, CBAM),一种简单但有效的前馈卷积神经网络注意模块,通过使用中间特征图来推断注意地图(Woo et al., 2018)。

图2所示。空间注意模块示意图。如图所示,空间注意模块利用两个输出和一个共享网络,沿通道轴最大池和平均池,并将它们转发到卷积层。
如图2所示,在Spatial Attention模块中,我们首先使用平均池化(average-pooling)和最大池化(max-pooling)操作来聚合特征地图的通道信息,生成两个二维地图:Favg和Fmax。它们分别表示跨通道的平均池特征和最大池特征。然后这些映射被一个标准的卷积层连接和卷积在一起。最后网络经过Sigmoid激活函数后生成二维空间注意图M(F),等于归一化代表不同空间重要性的因子,并指示强调或抑制的位置。简而言之,空间注意力的计算如下

其中f3×3表示一个滤波大小为3×3的卷积操作
4.实验数据

图3所示。实验数据预处理说明:高分一号WFV图像按相应角度旋转并裁剪出来。去掉没有任何地理信息和云信息的部分的冗余信息。标签数据相应地旋转,其中旋转角度与图像的旋转角度相同
高分一号卫星是由中国航天科技集团公司(CASC)发射的。高分一号WFV影像由于具有较高的时空分辨率和广阔的观测范围,在环境、农业、土地资源、应急灾害等重要领域得到了广泛的应用。高分一号WFV影像具有16米分辨率,4天时间分辨率,适用于大规模地球观测,具有跨越可见光到近红外光谱区域的4个多光谱波段。高分一号WFV卫星图像提供了广泛的应用服务,覆盖了防灾救灾、地理测绘、环境和资源调查以及精准农业支持等多个领域(Chen et al., 2016;李等,2015;春岭、昭光,2015;Lei等人,2015)。它们也被广泛应用于云检测领域(Li等人,2019;燕等,2018;Yang等人,2019)。高分-1 WFV云和云影覆盖了本文中称为高分-1 WFV的验证数据集,该数据集由武汉大学创建,用于对高分-1 WFV图像上的云检测方法的性能评估(Li等人,2017b)。我们的实验数据包括108个2a级场景和相应的云像素标记的标签。它们是从不同的全球土地覆盖类型和不同的云条件中收集的。有五种土地覆盖类型,即贫瘠、植被、城市、水和雪。正如许多方法被提出一样,(Yan等人,2018;Li等人,2019)我们的方法由两个阶段组成:模型训练和模型测试。实验数据根据全局分布分为训练数据和测试数据,分别在Li等人(2019)开发的基于NASA Visible Earth的地图中标记,用于模型训练和测试。训练数据包含86张图像,另一部分包含22张图像用于测试。每一部分包含所有土地覆盖类型。此外,我们通过图像的边界来确定图像的倾斜角度。然后,我们将高分- 1 WFV图像旋转相应的角度,裁剪出如图3所示没有任何地理信息和云信息的部分,从而消除冗余信息。此外,我们对标签数据进行相应的旋转,其中旋转角度与图像的旋转角度相同。然后,我们将图像和标签都切割成512 & a - 512的大小,用于后续的训练和测试
5.我们的方法
在本文中,我们的贡献包括以下三个部分:
- 基于Haar小波设计Up块和Down块,构建编码器-解码器网络,本文将该网络称为UD-Net。我们将小波变换与深度学习神经网络相结合。该网络可以提取云区域的纹理特征,自动学习云的特征。
- 强调原始图像的信息,这对图像分割的准确性至关重要。我们对网络的原始输入图像进行不同采样率的Atrous卷积。不同采样率的Atrous卷积可以有效捕获多尺度信息,实现对不同接收场云特征的学习。可以从原始图像中收集足够的位置信息。因此,它可以用来补充图像恢复过程中所缺乏的信息
- 设计了连续多尺度空间模块,用于增强多尺度特征图的有用空间信息,抑制无效信息。它可以显著提高网络的效率和针对性。同时,我们使用He et al.提出的暗通道先验(He et al., 2011)来辅助网络的学习。暗通道先验在云区表现出优异的特性,特别是高对比度。在薄云区,它也显示出比其他通道更高的亮度。暗通道先验能很好地区分云和地表覆盖类型的像元。因此,我们使用暗通道先验来辅助网络学习云的特征。对多尺度暗通道先验特征映射执行注意模块,对编码路径中特征映射的有用信息进行强调,对无用信息进行抑制。因此,它可以更好地指导网络在解码阶段对上一层传输的信息进行分析,大大提高了算法的性能
下面将讨论上述三种方法的具体实现,并对UD-Net、UDDI-Net和AUDI-Net的结构进行描述
5.1.UD-NET
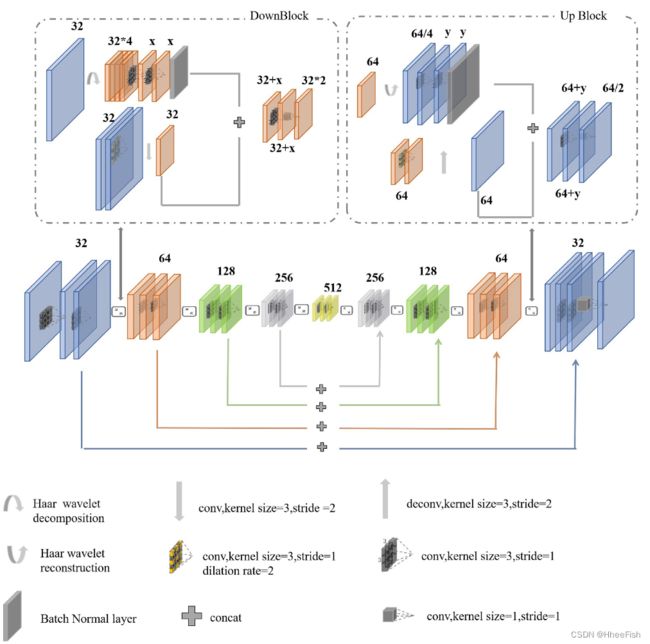
图4所示。所设计的UD-Net的结构。它由两个路径组成:编码器路径和解码器路径。对这两条路径中对应相同大小的特征映射的两层进行对称处理,以更好地学习和恢复图像信息
根据FCN和RS-Net,我们认为用于图像分割的深度学习网络一般由以下两条路径组成:编码器路径和解码器路径。为了更好地学习和恢复图像信息,需要对这两条路径中对应相同大小的特征映射的两层进行对称处理。因此,我们设计了以下的块和对称网络结构。
在编码器-解码器网络结构中,使用池化作为下采样方法会丢失大量与原始图像相关的信息,如空间信息。虽然步长为2的卷积层也可以实现下采样,但我们想要分割的目标的学习特征是不够的。对于解码器路径的上采样,插值方法会导致相对位置信息的丢失,并且不能突出我们想要分割的区域。因此,我们使用提出的Up和Down块来构建一个编码器-解码器网络,称为UD-Net,用于云检测。设计的网络结构如图4所示。在我们的方法中,将大小为512 ×512 ×4的高分1 WFV图像作为输入数据。拟议网络的结构可以简单地描述为表1所示。

Conv*2表示有两个卷积层。在每个卷积层后面设置激活层,并使用整流线性单元(ReLU)作为激活函数
由于输出的激活函数为Sigmoid,网络的预测是一个从0到1的云置信度量,因此必须确定一个阈值进行分类。在本文中,为了更好地权衡精度和召回指标,我们在评估模型时将阈值固定在0.5。本文采用的RS-Net比较算法也使用相同的阈值(Jeppesen et al., 2019)。此外,通过对其他论文的研究,大量的实验证明,以0.5为阈值的预测结果具有最均衡的性能。
从图4和表1,我们可以观察到我们的网络是大致对称的。低层特征图具有丰富的空间信息但缺乏语义信息,高层特征图则反之。我们融合了多尺度特征,而不是通过一次对最高特征图进行上采样来恢复原始图像的细节。上下块的描述将在以下小节中介绍
5.1.1.Down Block
在大多数图像的应用中,图像分割被认为是一个不可或缺的应用。此外,纹理总是被认为是重要的,有时它们是图像分割性能的唯一保证。近年来,由于小波变换具有多分辨率分析的特点,能够同时表示图像在时域和频域的局部特征,小波变换已成为纹理分析的有效工具
如果小波变换应用于各个领域,那么变换基的选择就会出现问题。Haar小波在时域上是不连续的,但在进行图像分解和重构时,可以很容易地对图像进行分析和合成。因此,采用Haar小波作为二维离散小波分解的基函数。Haar小波处理通过计算相邻元素的和和差来处理数据。首先对相邻的水平元素应用Haar小波,然后对相邻的垂直元素应用。对原始图像进行小波分解后,可以得到一系列不同分辨率的子图像,如图5所示。不同分辨率的子图像显示不同的频率,如LL为低频区,LH、HL、HH分别为水平分量、垂直分量、对角分量。由于大多数图像信息保留在低频分量中,它被认为是原始图像的近似。其他高频子图像包含细节或次要特征。对于每个低频分量,可以用Haar小波对LL进行一次处理,并进一步降维
离散Haar小波变换计算如下。给定离散信号f的值为f1,f2,…fN,我们使用以下方法,根据f的值计算一对子信号的公式称为平均A和波动D

其中m=1,2,…N/2。首先,对每一行像素值进行一维小波变换;该操作给出了平均值以及每一行的详细系数。然后,对于这些转换后的行,再次对每一列应用1D变换。Haar小波分解示意图如图5所示。图6为第一级应用Haar小波变换后的图像。

图5所示。小波分解的结构。对原始图像进行小波分解后,可以得到一系列不同分辨率的子图像。LL为低频区域,可以再次用Haar小波进行处理,并进一步降维

图6所示。图像经过一级haar小波变换后的结果。LL为低频区,LH、HL、HH分别为水平分量、垂直分量、对角分量

下采样用于降低图像的维数,获得更多的语义特征。在一定程度上可以避免过拟合。因此,我们设计了Down块来实现下采样。我们的Down块包括一个小波分解层、五个卷积层、一个分层卷积层和一个批归一化层。下块的结构如图4所示。我们的Down块分为两个分支,其中一个分支是小波分解。每个通道分别进行Haar小波分解,得到4个高度和宽度相同的平行特征图,然后在通道上拼接。特征图的大小变成了原来的四分之一,通道的深度变成了原来的四倍。然后,添加两个卷积层,其内核大小为3×3。具体来说,卷积的内核大小可以选择,并且可以根据网络的具体特性灵活地进行更改。我们用x来表示卷积核的个数。最后,添加了一个批处理归一化层。另一个分支用于通过卷积实现下采样。我们在卷积层之前添加一个迭代卷积层,步长为2。两个卷积层都有x个核,核的大小是3 ×3。Atrous卷积的优点是在保持图像大小和更好地保留空间位置信息的同时增加接收场。这对于图像分割尤为关键。
通过连接两个分支的输出,可以得到包含云结构信息的全局特征图。输出特征映射经过一个卷积层,保留相同数量的通道。最后,执行一个具有2个内核的瓶颈层
与池化层相比,我们的Down块不仅可以利用小波变换学习更细致的纹理特征,使网络有针对性地学习更多的信息,还可以利用卷积层扩大接受域,减少局部信息的丢失
5.1.2.Up Block
上采样用于重建对象的详细信息。高级别特征包含更多的语义信息,低级别特征包含更多的空间信息。我们设计的Up块可以充分利用高级特征的信息来完成分割。利用Haar小波重构和Atrous卷积,设计了一种结构与下块对称的上采样方法。对编码器路径上的图像进行哈尔小波分解后,再对解码器路径上的图像进行哈尔小波重构,可以更好地恢复图像

Up块包含1个小波重构层、5个卷积层、1个随机卷积层和1个批归一化层。如图所示,我们的Up块也分为两个分支。一是小波重构层。在这一层之后,图像的高度和宽度将增加一倍,通道的深度将是原来的四分之一。然后,采用两个卷积层学习重构信息。与Down块类似,卷积核的个数是可选的,我们用y表示这个参数。由于在编码器路径中使用小波分解作为下采样方法,在解码器路径中使用小波重构可以更好地重构对象的细节,并充分利用前一层提供的特征。在我们的实验中也证实了同时使用小波分解和小波重构比单独使用小波分解和小波重构能获得更好的结果。另一个分支用于在原卷积层之后增加反卷积层。然后,将两个分支的特征映射串联起来,经过一个卷积层,通道数恒定,得到输出。最后,执行具有一半y核的瓶颈层
在构建UD-Net的过程中,考虑到结构不是太复杂,我们在Down块中适当选择参数x,在Up块中适当选择参数y。我们设x为该模块的输入特征图的通道数,认为y与x相同,这样网络可以依次加深中间特征图的通道,从而达到语义信息可以被充分提取。
传统算法通常通过提取云的纹理特征来检测云。可见,纹理特征对于云的检测是至关重要的。在深度学习算法中,信息会自动从整个图像中提取出来。需要注意的是,纹理特征是由网络自动提取的,可以用来详细地还原图像,从而保存图像更重要的信息。由于在编码器-解码器网络中加入了小波变换,使得UD-Net学习到的信息更具针对性。最大池化或平均池化只能保留图像的低频特征。用Down块代替Maximum pooling或average pooling,既保留了低频特征,又保留了丰富的高频特征。高频特征的保留减少了信息的丢失,但最重要的是提取了云的纹理信息。网络可以学习和编码有针对性的纹理特征,从而充分利用云特征。此外,网络的高级特征图在获得更多语义信息的同时,丢失了大量的空间信息。下采样时,图像的原始信息会丢失。预计它将尽可能多地保留原始资料。通过这种方式,可以使用更多的信息来恢复解码器路径中图像的细节。解码器路径中的Up块与和Down块对称。使用小波重构可以充分利用从编码器路径传输的学习到的特征。总体而言,UD-Net实现了尽可能多地保存信息,充分提取纹理特征,并利用纹理特征恢复图像细节。
5.2.UDI-Net

图7所示。UDI-Net的结构。ASPP模块后接原始图像,并将输出拼接到UD-Net第一级特征映射通道上
根据U-Net、RS-Net和SegNet的结构以及其他用于分割的网络的结构,解码器路径与编码器路径几乎对称,从而生成u型结构。与位置信息丰富的底层特征层相比,更深层次的网络特征图包含更丰富的语义信息。解码器路径的作用是将低分辨率编码器特征映射到全输入分辨率特征映射,以便按像素分类。解码器路径中仍有许多通道。这些通道允许网络将上下文信息传播到更高的分辨率层。因此,该网络可以充分利用云的多尺度特性
此外,原始图像被认为包含最丰富的位置信息。期望解码器路径尽可能多地使用图像的原始信息。然而,在目前提出的u型结构中,编码器路径深化了原始图像的通道,以充分提取云的特征。换句话说,原始图像进行卷积的卷积核比输入通道的数量多。在解码器路径中的最后一个特征映射与处理后的原始特征映射连接,并进一步提取特征
众所周知,深度卷积神经网络的高级特征图具有丰富的语义信息。因此,如何利用这些特征图的信息一直是研究人员关注的重点。然而,通常不考虑底层特征图的空间信息,一般通过简单的卷积层将其融合到解码器路径中。我们特别强调了这些底层特征映射在图像恢复中的重要性经过深度卷积神经网络处理后,在解码器路径末端的复原图像不可避免地丢失了原始图像中存在的大量细节信息。为了补充丢失的信息,我们设计了一个网络,称为UDI-Net。UDI-Net的结构如图7所示
重要的是,多尺度信息必须必须正确编码才能被解决。为了解决这一问题,在不牺牲空间分辨率的前提下,引入Atrous卷积来生成具有更大接受域的特征。利用多个具有不同采样率的平行分层卷积层称为“分层空间金字塔池”(ASPP),通过使用多个具有不同采样率的并行滤波器来利用多尺度特征。不同空洞率的ASPP能有效地捕获多尺度信息。
因此,考虑到尽可能多地保留原始图像的结构特征和位置信息,我们提出了一种先将输入图像的原始信息由编码器-解码器网络的最后一层利用的方法,称为UDI-Net。具体来说,ASPP模块后面跟着原始图像。然后将输出与UD-Net中的一级特征映射在通道上拼接,如图7所示。提取信息的特征图,加上从解码器路径传输的特征图,不仅使网络扩大了网络的接受域,还能获得云的准确位置信息以及一定的语义信息
5.3.暗通道先验
在卫星遥感成像过程中,云和雾经常存在。讨论了几个有待解决的问题。它们的存在降低了图像的分辨率,使得从获得的图像中获取清晰的特征信息变得困难。而且严重影响了图像中目标的特征和信息提取。基于云与雾在外观上的相似性,云检测在一定程度上与遥感图像的去雾有关。暗通道先验在图像去雾化领域发挥着重要作用(Kumar等人,2015;Li等人,2017a)。在探测遥感影像云的过程中,也证明了暗通道先验的存在。He et al.(2011)首先提出了暗通道先验的概念。对于图像J,暗通道Jdark可表示为

Ω(x)是一个以x为中心的局部patch。
云与雾在辐射和纹理特征上有明显的相似之处。另外,可以确认的是,在大多数非天空斑块中,至少有一个颜色通道在某些像素处的强度非常低。由于图像分割是一个端到端的任务,它被期望保留尽可能多的原始信息在图像中。我们在提取暗通道时选择patch Ω(x)的大小为1 ×1。值得注意的是,云遮挡区域所有通道的最小值与非云像素有很大差异。这一发现表明暗通道先验有利于从下垫面提取云的特征。更具体地说,它可以用来增强云和非云区域中各种像素之间的亮度对比。我们通过实验比较了高分- 1 WFV图像各通道在黑暗中的亮度对比度,发现暗通道先验的亮度对比度明显高于红、绿、蓝通道。云区在暗通道先验上显示出更明显的亮度特征。对于红、绿、蓝和近红外通道,相对于地面真实情况,部分云区明显不能表达云的特征,但暗通道先验表现出优异的性能。与地面真相相比,暗通道先验最能显示云的空间信息。我们圈出暗通道先验比其他通道表现更好的区域。具体来说,高亮显示的对象在其他通道中具有更高的像素值。但在暗通道之前,突出显示的对象显示为低像素值。我们可以很容易地区分云彩和高亮的物体。薄云区在暗通道先验中也有更好的表现。不同场景的边界在其他通道中以高像素的形式反映出来。在暗通道先验条件下,该信息可以被很好地抑制。如下所示,包含云区的几种遥感图像的暗通道先验与红、绿、蓝、近红外(NIR)通道的差异如图8所示。
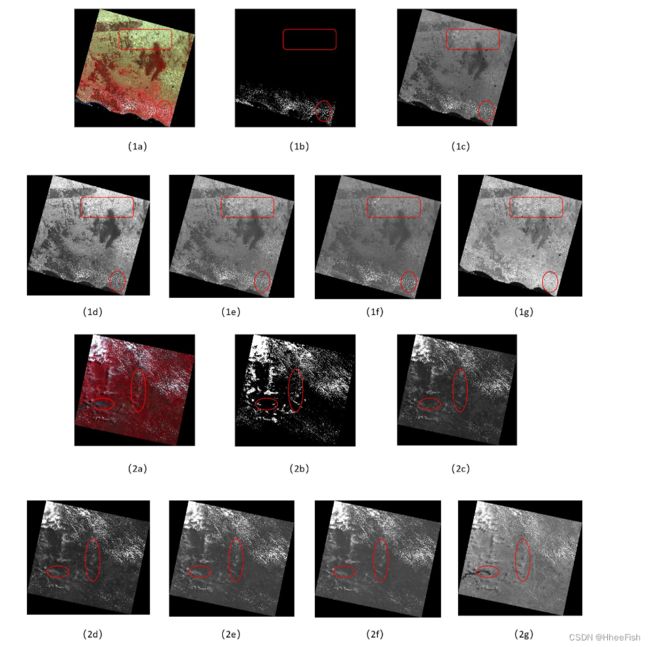
图8所示。各通道特征图与暗通道先验的比较。(a)原始图像(b)地面真实图像©暗通道先验(d)红色波段(e)绿色波段(f)蓝色波段(g)近红外波段。应该注意的区域在图中圈了出来
我们利用暗通道的先验不仅可以获得更明显的云区信息,使网络能够学习到更精确的特征。另一方面,通过对高分-1 WFV图像进行预处理,并在训练前提取暗通道,网络可以获得更高的效率和更快的收敛速度
5.4.AUDI-Net

图9所示。多尺度暗信道先验(MDCP)模块的结构说明。计算原始图像的暗通道先验特征图。通过最大池化和卷积运算得到多尺度暗通道先验特征图,并将其标记为不同的数字和颜色
我们使用暗通道先验来辅助网络的自动学习过程。如图9所示,我们设计了多尺度暗通道先验(MDCP)模块,用于生成下面提到的连续多尺度空间注意模块的输入。利用该模块,网络可以生成多尺度暗通道先验特征图,作为UDI-Net网络的辅助信息。
如前所述,更加重视原始图像的特征是非常重要的。因此,如图9所示,可以看出输入图像被调整到几个尺度∈{256,128,64,32}。首先计算原始图像的暗通道先验特征图,通过最大池化和卷积运算得到多尺度暗通道先验特征图;然后,将多尺度特征图应用于连续多尺度空间注意模块。这样,网络才能充分利用云的特性,从而更好地运行

图10所示。连续多尺度空间注意模块的结构。圆圈符号表示CBAM图中所示的相应特征图。三角形符号表示用于加权的多比例尺特征图,其有用信息将得到强化。在我们的方法中,它们是编码器路径中相应大小的特征映射,如图11所示。方号表示已加权的输出特征图。需要注意的是,不同的颜色和数字代表不同的尺寸
受卷积块注意模块(CBAM)中应用的空间注意模块的启发(Woo等人,2018),我们设计了连续多尺度空间注意模块。其结构如图10所示。与(Woo et al., 2018)不同的是,我们没有使用连续多尺度空间注意模块来强调暗通道先验特征图的位置。我们只使用之前的暗通道来辅助网络进行云学习。具体而言,我们设计了CBAM算法,并将其应用于暗通道先验,以利用云更突出的信息。然后将注意权重与编码器路径上的多尺度特征图相乘,强调深度学习过程中学习到的更多有用信息,指导解码器路径分析来自前几层的信息传递,提供持续的性能提升。该模块在暗通道先验信息的辅助下,可以使网络将注意力集中在有用位置的信息上,而不是对每个像素都同等关注。因此,提出了AUDI- Net,它可以在云上获取更详细的信息,抑制一些琐碎区域的信息。此外,网络可以利用有限的资源从大量的信息中提取出高价值的信息,大大提高了网络的效率和准确性。

图11所示。AUDI-Net的结构。该方法采用基于小波变换的上下块,引入图像的原始信息。此外,该模型利用了多尺度暗通道先验模块(CBAM)和连续多尺度空间注意模块
如图11所示,得到的每个像素具有不同权重的特征图与编码器-解码器网络中相应的层数相乘,这样我们就可以专注于特定的云区域。此外,由于暗通道先验的引入,网络对云区域的识别更加准确。网络可以学习对多尺度特征进行加权。连续多尺度空间注意模块为每个特征图分配归一化因子,以增强特征提取,从而达到更好的分割效果。连续多尺度空间注意模块学习到的不同位置的权重与网络的中间特征图密切相关,如下所述。云的学习特征的过程被自动干预,强调了网络应该学习的目标的位置,并减少了噪声的干扰。这种改进可以证明这样一个事实,即网络的收敛速度更快,检测精度变得更准确
在现有的算法中,网络不能充分提取薄云的特征。由于薄云和雾有相似的物理特性,许多去雾算法被用于去除薄云。暗通道先验常用于去雾算法中。我们的方法使用暗通道先验来获取更准确的云位置信息,特别是在原始图像中位置信息不明显的薄云区域。多尺度暗通道先验(MDCP)与连续多尺度空间注意(continuous Multi-scale Spatial Attention)相结合,使得网络不仅对厚云区更加关注,对薄云区也更加关注。此外,非云区域,如高亮的地物和雪,在暗通道先验的某些像素处具有非常低的强度。云可以清楚地与高亮的地面物体和雪区区分开。对云的误检概率可以大大降低。
6.讨论
训练过程在Intel Core CPU i9-9900K 3.60 GHz、2 ×Nvidia GTX 2080的PC上使用python进行,实验在Keras框架下进行。训练使用二元交叉熵作为损失函数来确定网络的参数,使网络具有最小的损失。在梯度下降法的基础上,利用Adam优化器减小梯度,使网络结果与地面真实值之间的差异最小化。实验时,初始学习率设为0.00001。对于每个训练周期,我们的方法audii - net的计算时间为4000 s。对于每个大小为0f 512 ×512的图像,计算时间不超过0.1 s。在测试数据集上,一个历元测试的计算时间平均为550 s。为了分析该算法的性能,采用了两种方法。一种是对预测结果与实际情况差异的主观观察,另一种是定量比较
6.1.评价指标
这里,为了定量评估所提方法的性能,使用了五个指标,即总体精度(OA)、精度(Precision)、召回率(Recall)、F_score和虚警率(FAR)。这些指标可以计算如下

其中TP表示云像素的正确预测,TN表示无云像素的正确预测,FP和FN表示不正确的检测结果,其中FP表示云被检测为非云的像素,P表示地面真实图像的云像素
一般情况下,在ground truth中不存在云像素的情况下,应在分母中加入无穷小的ε,以避免出现分母为0的情况。我们选ε =e所有的指标都是在每个图像的基础上计算。然后在整个测试样本上对这些数字进行平均,以得到不同性能表中引用的数字
6.2.UD-Net表现评估
6.2.1.云检测中UD-Net的定量分析

表2:不同上、下块组合个数下的拟建UD-Net评价指标比较,用m表示
分别对不同组合的上下块进行了训练和测试。表2描述了这些网络的度量性能。将Up和Down块的组合从编码器-解码器网络的低层空间特征层添加到高层语义特征层。其中表2中的m表示他们在UD-Net中的数字。实验证明,随着Up和Down块组合数量的增加,UD-Net的性能会更好。
为了检验所提出的Up块和Down块的性能,我们对Up- Net、D-Net和UD-Net三种网络进行了训练和测试,并将结果与基本的编码器-解码器网络的性能进行了比较。首先,我们在编码器路径中使用提出的Down块,在解码器路径中使用简单插值作为上采样方法来构建网络。这个网络被称为D-Net。此外,我们在解码器路径中使用Up块,而在编码器路径中使用最大池化作为下采样方法来设计Up- net。最后,如图4所示,我们同时使用Up和Down块来构建UD-Net。
为了分析Up和Down模块的功能,我们设计并证明了它们的优越性,并使用基本的编码器-解码器网络进行比较。

表3使用Up块和Down块的方法与编码器-解码器网络的评价指标比较。
与基本编码器-解码器网络相比,Up-Net和D-Net在评价指标方面的改进见表3。具体而言,Up块显著提高了网络的精度和FAR。与编码器-解码器网络相比,精度从89.89%提高到93.87%,FAR从8.32%下降到7.01%。此外,OA和F_score也有一定的提高。Up-Net的OA从96.73%提高到97.05%。F_score增加了3.83%。也就是说,UP块的主要功能是减少非云像素被检测为云像素的像素数,降低FAR,提高精度
至于Down块,OA, Recall和F_score的提升是非常明显的。引入Down块后,TP增加,正确检测到更多的云像素。未检测到的云像素减少。与编码器-解码器网络相比,OA提高了0.39%,召回率提高了1.8%。F_score表现得很好,它增加了4.22%。需要注意的是,由于对称的网络结构更具有稳定性,所以Up和Down块在网络中扮演着不同的角色,因此使用Up块可以减少误检,使用Down块可以检测出更多的云像素。因此,一般而言,UD-Net比Up-Net和D-Net表现出更好的性能。与基本的编码器-解码器网络相比,这五个指标都得到了改进,大量的实验也证明了所提出的UD-Net具有较高的稳定性。OA提高到97.27%。与编码器-解码器网络相比,它增加了0.54%。FAR降低了2.83%。这样,我们认为使用小波变换的深度编码器-解码器网络在遥感图像的云检测中能表现出更好的性能
6.2.2.云检测中UD-net的定性分析


图12所示。对不同场景的检测结果进行视觉比较,包括城市、水、贫瘠、积雪和植被。(a)输入图像。(b)基本事实。通过©编码器-解码器网络,(d)拟议的UD-Net和(e)拟议的uddi - net获得的检测结果
如图12所示,我们给出了对应于表3的云检测的视觉性能。可以看出,基本编码器-解码器网络生成的边界是粗糙的。在第一张和第6张图像中,我们观察到在大云区存在漏检现象。UD-Net显著改善了这种情况。从第二、第三和第四幅图像中,我们可以使用编码器-解码器网络在非云高亮区域发现错误检测的像素,但UD-Net的性能更好。从第4、5、7张图像中,我们可以发现基本的编码器-解码器网络经常错误地将不同场景的边界检测为云。但是,对UD-Net的误检非常罕见。由此可见,基于小波变换设计的Up和Down块能够更好地利用纹理信息,有针对性地学习遥感图像中云的特征
6.3.UDI-Net性能评估
6.3.1.UDI-Net在云检测中的定量分析
然后,在UD-Net的基础上设计了UDI-Net,以证明原始图像的特征在遥感图像云检测中的重要性
我们利用UD-Net上原始图像的特点来构建UDI-Net。相应的指标如表4所示。可以看出,虽然OA基本没有变化,但是精度和FAR有了明显的提高,优于Up-Net、D-Net和UD-Net。FAR显著降低到3.72%,比基本编码器-解码器网络低4.6%,比UD-Net低1.77%。此外,Pre-cison有了改进。提高到96.12%,比基本编码器-解码器网络提高了6.23%。根据评价指标公式,可以分析出误检为云的像素数明显减少;从而证明了利用深度编解码器网络进行云检测时,原始图像的信息是必不可少的

图13所示。对包括5种土地覆盖类型在内的22幅测试图像进行了UD-Net和UDI-Net的FAR比较
我们还展示了22张测试图像的UD-Net和UDI-Net的FAR比较直方图。如图13所示,除第一张测试图像外,其余21张测试图像的FAR都有了明显的提高。第15张测试图像的FAR下降幅度最大,达到6.95%。由此证明了用于训练网络的原始图像的信息对于构成丢失的图像信息是有用的。错误检测到的云的像素数量显著减少
6.3.2.UDI-Net在云检测中的定性分析
从图12可以看出,与基本编码器-解码器网络和UD-Net相比,UDI-Net在云检测过程中减少了误检云像素的数量。第三张和第四张图片中有高光非云区域。基本的编码器-解码器网络和UD-Net都表现出较差的检测性能,提出的UDI-Net性能更好。在第7张图中,不同的土地覆盖类型有明显的边界。在这些方面,其他算法显示了一些错误检测,但是我们的UDI-Net得到了显著改进。此外,部分测试图像未检测到云像素的情况也有一定改善,如图12所示。
6.4.AUDI-Net表现评估
6.4.1.AUDI-Net在云检测中的定量分析
最后,我们介绍了网络中的连续多尺度空间注意模块。很明显,随着网络复杂性的增加,在训练数据的限制下,网络容易发生过拟合。随着网络结构复杂性的增加,网络的效率和性能都在下降。因此,我们适当调整了上面提到的Down和Up块的参数x和y。考虑到对称网络结构可以使网络更加稳定,我们将x设为y。在本文中,我们将这两个参数分别设为8,16,20,24,32。
6.4.2.AUDI-Net在云检测中的定性分析

图14所示。对于参数x和y的不同值的AUDI-Net, OA值(蓝色实线,标注OA)和FAR值(橙色实线,标注FAR)(要解释此图图例中对颜色的引用,读者可参考本文的网页版本)。
图14为不同通道的AUDI-Net结果。研究还表明,随着网络复杂性的增加,包括OA和FAR在内的性能都在不断提高。受限于我们的GPU内存,我们进行了最大参数为32的实验。在实际应用中,可以根据实验资源的情况选择合适的参数。如果可能,具有更深通道的网络的性能可以显示更好的结果。但当网络深度增加时,网络的效率会降低,这取决于训练数据的数量。
为了验证该算法的性能,我们使用了Up和Down块,引入了基于暗通道先验的空间注意块,并利用原始图像的特点,将该算法与其他几种算法(包括SegNet、DeepLabv3+和RS-Net)进行了比较。
- SegNet
SegNet的新奇之处在于解码器对其低分辨率输入特征映射进行上采样的方式。具体地说,编码器由与滤波器组的卷积、元素的非线性、最大池化和子采样组成,以获得特征图。对于每个样本,池化期间计算的最大位置的索引被存储并传递给解码器。解码器使用在相应编码器的最大池化步骤中计算的池化索引来执行非线性上采样。上采样的映射是稀疏的,然后用可训练的滤波器进行卷积生成密集的特征图。不需要学习上采样,它使得内存与精度的权衡涉及到实现良好的分割性能
- DeepLabv3+
在FCN的基础上提出了丰富的分割网络。DeepLabv3遵循FCN的全卷积运算,引入了孔洞卷积和金字塔池。近年来,它在各种图像处理任务中得到了广泛的应用。DeepLab系列网络近年来不断改进,DeepLabv3+结合了编码器-解码器结构和Atrous空间金字塔池(ASPP)的结构。深度神经网络采用空间金字塔池模块或编解码器结构进行语义分割。前者通过多速率和多有效视场的滤波或池操作探测传入的特征,能够对多尺度上下文信息进行编码,而后者则通过逐步恢复空间信息来获取更清晰的对象边界。该方法在PASCAL VOC 2012语义图像分割数据集上取得了较好的效果。
- RS-Net
RS-Net基于U-net架构,U-net最初是为生物医学应用而设计的。通过使用l2 -正则化、dropout和批归一化层,对模型进行正则化以避免过拟合。l2 -正则化将权重的平方和添加到损失函数中,从而防止个别神经元占主导地位(Ng, 2004),并在所有卷积层中使用。Dropout是一种将神经元的输出随机设为零的方法(Srivastava et al., 2014)。这有效地迫使数据在网络中采用不同的路径,从而防止过拟合。批处理归一化是一种在整个网络中进行特征归一化的方法(Ioffe和Szegedy, 2015),它应用于编码器的每个卷积之后。它只在整个体系结构的最后一个批处理规范化层之后使用dropout,而不是在每个卷积块之后使用dropout
为了保证实验结果的准确性,获得更好的比较结果,所有用于比较的实验代码都是从算法作者给出的URL中下载的。我们通过使用相同的数据集来训练和测试所有的网络。我们的audit - net在所有五个指标中都达到了最好的性能。云检测的平均总体准确率(OA)和虚警率(FAR)分别高达97.51%和3.88%。与编码器-解码器网络相比,OA提高了0.78%。FAR下降了4.44%

图14所示。对于参数x和y的不同值的audii - net, OA值(蓝色实线,标注OA)和FAR值(橙色实线,标注FAR)(要解释此图图例中对颜色的引用,读者可参考本文的网页版本)。
分析了不同地表覆盖类型场景下的云探测性能。由表5可以发现,在所有场景中,所提算法AUDI-Net的OA优于其他三种算法,特别是在雪地和水中。值得注意的是,在城市和雪地环境下,AUDI-Net的FAR有了明显的提高。这充分证明了原始图像信息对分割的重要性。从表5还可以看出,uddi - net的FAR已经大大降低,特别是在水域。在图像分割任务中,精度和召回往往是相互制约的。其中一项指标的改善往往伴随着另一项指标的下降。从表5中,我们也可以观察到在某些场景中Precision或Recall有一定的下降。然而,在所有场景中,使用用于平衡召回率和精度的综合指标,F_score得到了提高。由此可见,我们的算法在整体性能上有很大的提高。

图15所示。对不同方法的检测结果在城市、水体、荒地、雪地、植被等不同场景下进行可视化比较。(a)输入图像。(b)基本事实。通过© Segnet, (d) DeepLabv3+, (e) RS-Net和(f)我们的audit - net获得检测结果
图15显示了不同方法在云检测中的视觉性能。这里,我们在五个代表性的场景下,分别是城市、水、贫瘠、雪和植被。从图12中红圈所标记的区域可以看出,我们的算法可以更好地检测出第二、第三、第四场景中的薄云。在第一个和第五个场景中,其他算法错误地将高亮区域的非云像素检测为云像素,但我们的算法在这种情况下证明了一些改进。该算法检测出的错误分类像素较少。图16给出了我们在不同通道下提出的audit - net的不同检测结果。可以看出,随着网络通道的加深,我们得到了更好的检测结果

图16所示。不同参数x和y下,audii - net检测结果的视觉比较。(a)输入图像。(b)基本事实。参数x和y分别设置为© 8, (d) 16, (e) 20, (f) 24, (g) 32。
7.总结
对于高分-1 WFV图像,本文提出的基于小波变换的Up和Down块的UD-Net、引入图像原始信息的UD-Net以及包含多尺度暗通道先验模块和连续多尺度空间注意模块的AUDI-Net在实现厚云检测精度的同时,在像素水平上显著提高了薄云检测的精度。我们的算法在云检测任务中保持了更好的准确性,从而避免了过度检测的问题。在突出的非云区、不同土地覆盖类型的交界处和雪区,我们的网络表现出良好的分割效果。同时,它对薄云和点云也很有效。一方面,我们在上采样和下采样时结合卷积和小波变换,以减少信息的丢失,强调云的纹理特征;另一方面,在网络中使用原始图像上的信息,以平衡在图像恢复过程中丢失的详细信息。同时,由于暗通道先验的优良特性,薄云的特征更加突出。暗通道先验和cam被用来帮助网络聚焦于有用的信息
为了评估所提模型的有效性,利用SegNet、DeepLabv3+和最新RS-Net的云检测结果进行实验比较。为了进一步评价所提方法的性能,计算了遥感测试图像的OA、Precision、Recall、F_score和FAR,综合描述了检测方法的性能。通过定性和定量分析,我们可以得出结论,我们的算法在所有土地覆盖类型的图像上都有更好的表现。最后,我们的算法对薄云、高亮像素和雪区的检测结果符合我们的预期