Invisible Backdoor Attack with Sample-Specific Triggers
2022.1.10第一篇 精读(ICCV2021)
本文已授权投稿于我爱计算机视觉公众号

论文链接: Invisible Backdoor Attack with Sample-Specific Triggers
代码链接:Invisible Backdoor Attack with Sample-Specific Triggers
文章目录
- Prior Knowledge
-
- 什么是后门攻击
- 后门攻击的实际背景
- 后门攻击和对抗攻击的区别
- Introduction
- Contributions
- A Closer Look of Existing Defenses
-
- Pruning-based Defenses
- Trigger Synthesis based Defenses
- Saliency Map based Defenses
- STRIP
- The Proposed Attack
- Experiment
- Conclusion
- References
Prior Knowledge
本篇文章属于后门攻击范畴,在讲解之前,我先简单的介绍一下一些先置知识:
什么是后门攻击
后门攻击旨在将隐藏后门嵌入深度神经网络(DNN)中,使被攻击模型在良性样本(benign samples)上表现良好,而如果隐藏的后门被攻击者定义的触发器(triggers)激活,其预测将被恶意更改。
后门攻击的实际背景
众所周知现有的深度神经网络越来越往大模型,大数据上靠了,很多研究人员由于无法承担如此高的计算消耗,不得以使用第三方资源来训练深度神经网络。例如,可以使用第三方数据(来自互联网或第三方公司的数据),使用第三方服务器(Google Cloud)来训练模型,甚至直接使用第三方API做任务。这就为攻击者在你模型训练阶段做手脚提供了机会。
后门攻击和对抗攻击的区别
笔者眼中后门攻击和对抗攻击的区别:后门攻击是指当且仅当输人为触发样本(triggers)时,模型才会产生特定的隐藏行为(一般表示为分类错误);否则模型工作表现保持正常,个人感觉主要强调隐蔽的攻击。而对抗攻击则不同,它旨在让模型分类错误,个人感觉主要为直接攻击。此外对抗攻击在模型部署后对其推理阶段进行攻击,而后门攻击则针对多个阶段都能进行攻击,具体参见:Backdoor-Learning。
Introduction
现有的后门攻击方法添加的triggers是sample-agnostic的,即不同的中毒样本使用相同的triggers,这导致这些后门攻击方法很容易被现有的后门防御方法瓦解。基于此,本文提出了一种新的后门攻击方法:通过生成sample-specific的triggers实现攻击,且该方法能攻破现有的后门防御方法。
下图展示了sample-agnostic的BadNets方法和本文所提的sample-specific的后门攻击方法的差异:
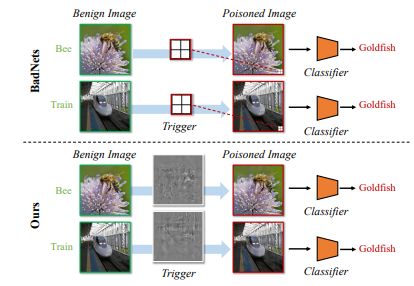
Contributions
- 作者对当前主流后门防御的成功条件进行了全面的讨论,揭示他们的成功都依赖于triggers是sample-agnostic的先决条件。
- 本文探索了一种新的攻击范式:其triggers是sample-specific且不易察觉的。它可以绕过现有的后门防御方法。
- 作者进行了大量的实验来验证了所提方法的有效性。
A Closer Look of Existing Defenses
作者认为现有后门防御方法的成功主要基于triggers是sample-agnostic的假设,一旦违反这一假设,他们的有效性将受到很大影响。下面讨论了几种现有防御方法的假设。
Pruning-based Defenses
基于剪枝地防御认为:由于triggers是sample-agnostic的,那么只要剪调编码triggers对应地神经元就可以抵御后门攻击,而这种方法对sample-specific的triggers是无效的。
Trigger Synthesis based Defenses
基于合成triggers的防御方法(Neural Cleanse[1])假设当然也需要有一个sample-agnostic的trigger,否则合成的triggers毫无意义。
Saliency Map based Defenses
基于Saliency Map的防御先计算每张图片的Saliency Map,再根据不同图片之间的显著性相同的区域从而定位triggers,该方法对sample-specific的triggers同样无效。
STRIP
STRIP[2]方法通过将各种图像模式叠加到可疑的图像。如果生成的样本的预测是一致的,那么这个被检查的样本将被认为是中毒样本。可以看出STRIP还是依赖于triggers是sample-agnostic的假设。
The Proposed Attack
如何设计sample-specific的triggers呢?作者受到基于深度神经网络的图像隐写术启发,生成的triggers是不可见的可加性噪声,包含目标标签的代表性字符串。下图很清晰的反映了本文所提的后门攻击的流程:
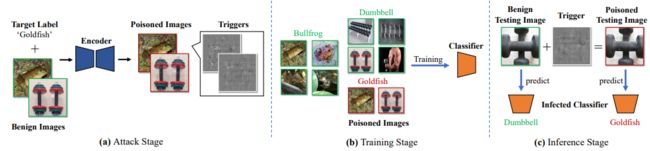
下图展示了编码器-解码器的训练过程。 编码器与解码器同时在良性训练集上训练。具体来说,编码器被训练以将字符串嵌入到图像中,同时最小化输入图像和编码图像之间的感知差异,而解码器被训练以从编码图像中恢复隐藏信息。

至此中毒的数据集制作完成,攻击者可以将其发送给使用者,使用者拿该数据集进行正常训练时,模型中就嵌入了隐藏的后门。
Experiment
本文在MS-Celeb-1M和ImageNet进行了实验验证:

上图展示了本文所提的攻击方法与BadNets和Blended Attack的比较,可以看出本文所提方法是sample-specific且扰动不可见的。
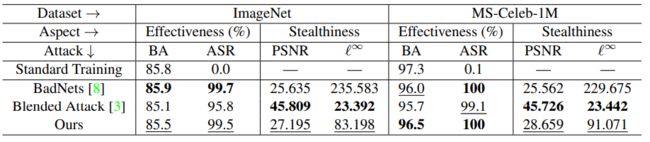
上表展示了本文所提方法的攻击成功率仅比BadNets稍差,且精度相对于正常训练也下降很小。虽然本文所提的方法攻击成功率较BadNets低,但是其隐秘性更好(这里用峰值信噪比PSNR和 l ∞ l_{\infty} l∞来衡量)

上图展示了不同后门攻击方法针对基于剪枝的防御良性精度(BA)和攻击成功率(ASR)的曲线,可以看出本文所提方法能使基于剪枝的防御失效。

上图展示了Neural Cleanse[1]合成出来的triggers,可以看出针对BadNets和Blended Attack的合成triggers包含与攻击者使用的相似的模式(即右下角的白色方块),而对本文所提的方法合成出来的triggers是毫无意义。
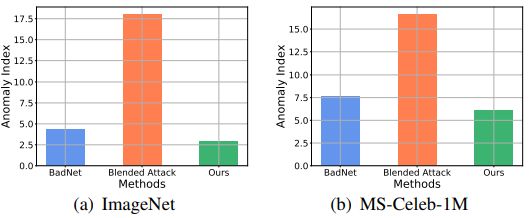
上图展示了BadNets、Blended Attack和本文所提方法的异常指数,越小表明Neural Cleanse越难防御。

上图可以看出本文所提方法针对基于Saliency Map的防御也能抵御。
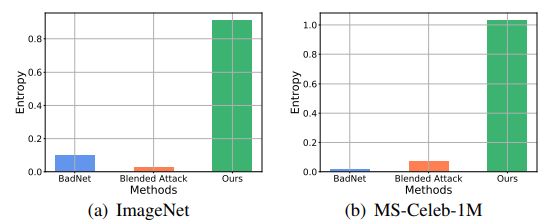
上图展示了STRIP[2]对不同后门攻击方法的防御,其中熵越大,STRIP 越难以防御。
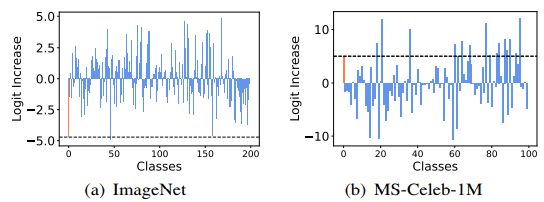
DF-TND[3]通过在精心设计的通用对抗攻击前后观察每个标签的 logit 增加来检测可疑 DNN 是否包含隐藏的后门。如果仅在目标标签上出现 logit增加峰值,则DF-TND方法可以成功检测。如上图所示,目标类的logit增量(图中红色条)在两个数据集上都不是最大的。这表明所提攻击也可以绕过DF-TND。
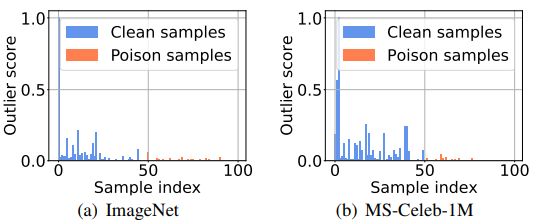
Spectral Signatures[4]发现了后门攻击可以在特征表示的协方差谱中留下可检测的痕迹。迹也叫做光谱特征,它是使用奇异值分解来检测的。此方法计算每个样本的异常值分数,该方法可以成功检测(干净的样品有较小值和中毒的样本有较大的值),上图展示了采样的样本的分数,可以发现中毒样本的分数反而抵御正常样本,因此本文所提方法也能绕过Spectral Signatures。

上表反映了选择不同目标类的良性精度和攻击成功率。

由于本文所用的trigger是sample-agnostic的,因此作者进行了实验,将用于某个样本上的trigger放在另一个样本上,得到上表所示的结果,证明了trigger的sample-agnostic。

上图反映了不同中毒样本比例的良性精度和攻击成功率。

上表反映了本文所提的后门攻击方法具有可迁移性。

上表展示了基于out-of-dataset的图像生成的中毒样本同样可以实现近 100% 的攻击成功率。 这表明攻击者可以用out-of-dataset的图像来激活被攻击深度神经网络中的隐藏后门。
Conclusion
本文提出了一种sample-specific的triggers,并通过大量实验证明该后门攻击方法能攻破现有很多后门防御方法,同时取得较高的攻击成功率和隐蔽性。
References
[1] Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks
[2] STRIP: A Defence Against Trojan Attacks on Deep Neural Networks
[3] Practical detection of trojan neural networks: Data-limited and data-free cases
[4] Spectral signatures in backdoor attacks