研究表明:论文被大V宣传后,引用次数暴涨2~3倍!
随着AI领域的迅猛发展,学术成果的传播方式发生了显著转变。
期刊审稿周期长,当你还在和审稿人battle时,方法先过时了。而会议虽然没有期刊长,但也有几个月的时间差,为了保护成果的创新性并扩大影响力,很多有名的大组都会选择先在在线预印本平台ArXiv上首发,学术成果更迭速度越来越快。
这也导致了每天arxiv上发表的论文根本看不过来。
此时社交媒体上出现了一批论文分享者,他们挑出AI/ML领域里真正有趣、重要的东西,让大家更容易理解和接触学术成果。
比如我们“夕小瑶科技说”就经常给大家分享有趣的论文,嘿嘿~
社交媒体上的论文分享者除了帮助大家筛选论文外,其分享的行为也扩大了论文本身的影响力!
有多大呢?
今天介绍的这篇论文给出的结论是:被大V分享的论文,被引用的次数比其他的多2-3倍!

论文标题:
Tweets to Citations: Unveiling the Impact of Social Media Influencers on AI Research Visibility
论文链接:
https://arxiv.org/pdf/2401.13782.pdf
这篇文章主要选取了X(前身为Twitter)上两位非常有影响力的用户AK (@_akhaliq)和Aran Komatsuzaki (@arankomatsuzaki),追踪经由他们分享后的论文的引用次数,并设置了对照组。还深入探讨了分享者对论文作者的地理、性别和机构是否有偏好等问题。
下图是两位大V在X上的用户页面截图,可以看到粉丝众多。
▲@_akhaliq
▲@arankomatsuzaki
他们的分享形式一般为:论文标题+一句话总结+论文链接+论文首页截图,如下图所示。简单清晰,重点突出。
▲分享形式
每天分享几篇论文,浏览量都超过上千,为其分享的论文带来不少的曝光度。所以其引用量超出未被分享的论文2-3倍,也不难理解了。

当然主观分析不靠谱,还是要用数据说话,接下来我们来看看详细的图表数据以及作者的分析过程。
1. 数据集:超过8000篇论文的综合数据集
本文构建了一个包含超过8000篇论文的综合数据集,这些论文涵盖了2018年12月至2023年10月期间,两位社交媒体大V在X和Hugging Face等平台上分享的所有相关论文。
为了进行对照研究,作者还构建了一个对照组,该组由与分享论文在出版年份、出版地点和摘要主题上一一匹配的论文组成。通过这种方法,确保了两组论文在质量上的可比性,从而排除了大V只分享“高质量”论文(自然会获得更多引用)的常见假设。
2. 研究方法
作者假设论文的引用次数主要受到发表时间、论文质量和主题的影响。为了量化这些因素,我们使用发表的会议和年份作为论文质量的代理变量,并使用论文标题和摘要的文本嵌入来近似论文主题。
数据收集过程包括三个部分:
1. 收集目标集
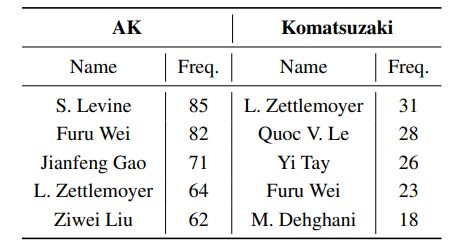
首先找到@_akhaliq和@arankomatsuzaki两位大V所推荐的论文列表,使用Semantic Scholar API查询每个文档的标题、摘要、发表年份、发表场所和被引用次数。删除缺少所需属性的任何论文。下表是两位用户共享的前五位最常见的作者以及他们的论文数量。
2. 对照组首先收集了与目标集中的论文在同一会议和同一年份上发表的大规模数据集。具体而言,对于每个在会议v中年份y出版的论文实例,通过查询Semantic Scholar API来获取在会议v和年份y出版的所有论文。共得到了247,993篇唯一的论文,以及124,940篇具有所有所需属性的论文。这些数据构成了与目标集匹配的语料库。
3. 匹配算法
将目标集与对照组的论文进行匹配,对分类变量(发表会议和主题)进行精确匹配,并对连续变量(主题嵌入)使用欧几里得距离匹配。余弦相似度的截断值设定为0.6,确保目标集和对照组在主题上的高度相似性,保留了AK的推文论文的91%和Komatsuzaki的推文论文的96%。
匹配对在主题上非常相似,几乎总是涵盖相同的研究子领域(例如,应用于图像生成的扩散模型),解决相同的问题,并使用相似或相同的方法。如下图所示:

4. 评审分数
此外,为了验证该方法成功控制了论文质量,还检查了目标组和对照组在六个主要机器学习会议的论文评审分数:
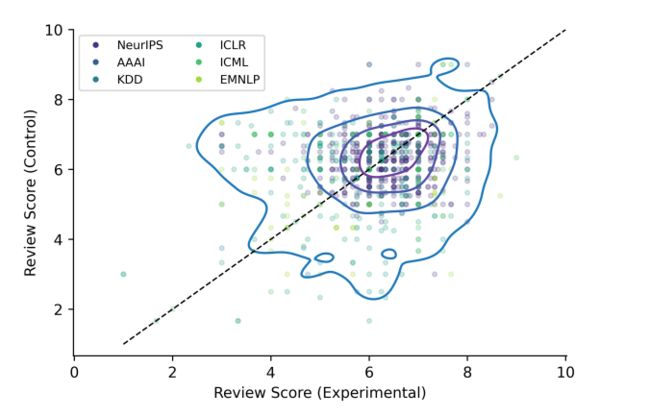
结果发现,两组的论文的评审分数分布相似,这说明两组论文质量几乎相等,进一步证实了的匹配方法的有效性。
3. 影响力分析:引用次数与社交媒体分享的关系
作者使用直方图(a,b)和小提琴图(c,d)分别展示目标组(Experimental)和对照组(control)的引用次数分布。如下图所示
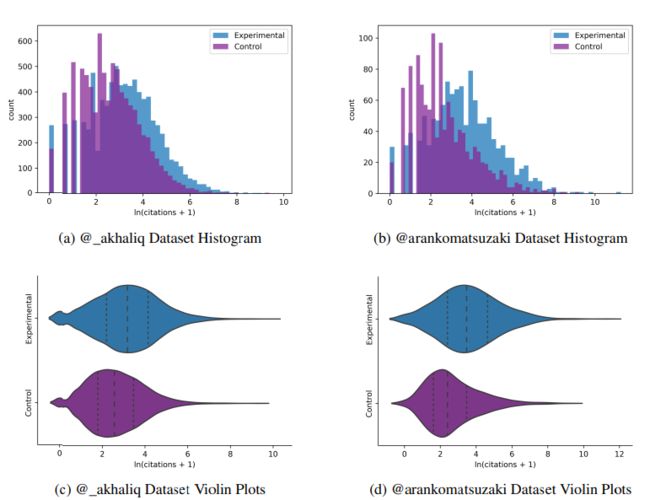
结果显示,AK分享的论文的中位引用次数为24,而控制组为14;Komatsuzaki分享的论文的中位引用次数为31,而控制组为12。这些结果表明,与对照组相比,被大V分享的论文在引用次数上有显著提高。
作者还使用了2-样本Q-Q图比较目标组和对照组在每个分位点上的分布情况。为了构建图表,引用计数被对数缩放,标准化为对照组的分布(z-score),并按顺序配对进行排序。虚线表示一个等分布;线上方的点表示实验组的分位数更高,反之亦然。如下图所示:

图表显示,目标组的分布始终较高,尤其是靠近中位数的部分。这表明大V分享对于改变论文的引用次数等结果变量在实际上具有显著的影响。
另外作者还使用了Epps-Singleton (ES)、Kolmogorov-Smirnov (KS) 和 Mann-Whitney U (MWU) 等统计测试来确立这一差异的统计显著性,所有测试的p值都远低于严格的α = 0.001标准。如下表所示:
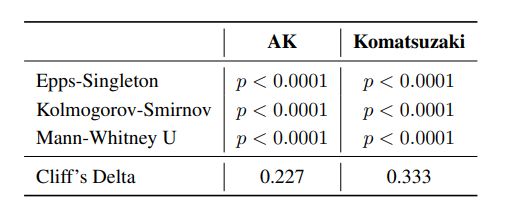
这些检验显示了实验组和对照组分布存在显著差异。
虽然传统上,顶级会议接受(即审稿分数)一直是未来引用次数的主要指标,但该研究表明,大V的分享行为对论文的影响力也不容小觑。,这也体现了社区发现和阅读论文方式的转变。
4. 地理与性别多样性讨论
1. 地理分布的影响
鉴于AK和Aran Komatsuzaki的美国背景,作者探讨了探讨他们分享的论文是否存在地理偏见。
各国论文出版数量变化
作者参考斯坦福HAI 2023 AI指数报告中AI存储库出版物的地理分布,统计了各个国家在人工智能领域发表论文的数量。如下图所示:

可以看到,美国在AI领域的论文发表数量略有下降,这可能表明人工智能领域的成熟,研究越来越分散在全球范围内。同时,欧盟和英国在2010年至2017年持续下降之后,开始出现适度增长,而中国的份额呈现持续上升姿态。
影响者分享论文的地域统计
作者使用Semantic Scholar和dblp收集每个目标集中列出的所有作者的隶属数据。然后,使用Nominatim地理编码API找到每个隶属机构的大致纬度和经度。使用在线公开可用的地址手动调整明显不准确的坐标。从这些信息中,使用Nominatim进行反向地理编码,找到每个隶属机构的国家,然后使用多数投票为每个出版物分配一个国家。结果如下图所示:

▲全球影响力文献作者的地理热力图显示其独特机构的分布。
从上图中,我们可以看到两位影响者分享了来自世界各地的论文。其中美国和欧洲尤为热门。
影响者分享论文的趋势变化
最后,作者将各个国家汇总到HAI报告中使用的相同地理区域,并使用类似的格式进行绘图。

影响者在2018年至2021年的分享模式,与论文发表的全球趋势明显不同。
具体来说,AK分享的出版物显示出“未知”类别的急剧下降,美国份额的戏剧性的上升。这似乎表明了隶属关系报告的改善,而不是AK分享习惯的变化,因为来自其他地区的份额相对稳定。
Komatsuzaki的数据显示了对美国隶属论文的持续关注,直到后来才开始出现其他地理区域。
总的来说,虽然AI出版物的全球格局表明多样性的增加和研究产出的更均匀分布,但我数据呈现了偏向美国的倾斜对齐。
另外,作者还表示该统计不够完善:仅使用论文上显示的隶属关系可能会对美国产生固有的偏见。例如,许多隶属于跨国组织的研究人员被分配到美国(总部所在地),但他们却在另一个地区的分支机构工作。此外,还必须注意两位影响者数据中“未知”类别的突出性,未找到隶属关系。
2. 性别多样性的现状
在计算机科学和工程领域,性别多样性至关重要,这些领域历史上一直由男性主导。
首先为了了解该领域整体性别分布的情况,作者参考了2021-2022年Taulbee调查报告的美国计算机科学及相关领域博士学位获得者和教员的性别分布。
然后通过仅筛选每篇论文的第一作者,使用了AMiner Scholar Gender Prediction API,该API根据姓名和隶属关系(如果可用)将作者分类为“男性”、“女性”或“未知”。
结果显示,在@_akhaliq数据集中,可以识别性别的作者中男女比例为80:20,而在@arankomatsuzaki数据集中,该比例为81:19。
这些比例与Taulbee调查报告的计算机科学博士学位获得者中的77:23比例大致相符,与教员中的76:24比例略有偏差。
这表明女性研究者正在增加,但与男性研究者的数量还有很大差距。
总结&讨论
由此可见,社交媒体上的大V们在AI/ML研究中真的很重要。他们分享研究论文,让更多人看到这些论文。本文研究发现,被大V分享的论文,被引用的次数比其他的多2-3倍。这说明大V们不只是分享好论文,他们还能帮大家理解和关注重要的研究成果。他们的推广能力真的很强!
但也有几点内容值得我们思考:
-
现在信息这么多,每天arxiv上发表的论文根本看不过来,这些大V帮我们挑出AI/ML领域里真正有趣、重要的东西,让大家更容易理解和接触。不过,总是听他们说也可能让我们错过一些其他的好东西。所以,我们需要一个多样化、有竞争的在线学术环境,这样每个人都能看到更多的研究和想法。
-
现在社交媒体上的大V们在AI/ML学术圈里越来越有影响力。这意味着我们可能需要重新考虑怎么选论文、怎么评审。希望会议和学术机构能跟上这个变化,改进他们的系统和过程,确保高质量的研究能被大家看到和传播。
-
社交媒体上的大V们确实帮了忙,让更多人看到了ML领域的研究。但本文的分析发现,他们分享的论文大多是关于美国的。虽然这反映了美国在AI/ML领域的领先地位,但我们也应该看到其他国家的研究。另外,ML领域里男性和女性的比例不太平衡。虽然大V们分享的内容没有明显的性别偏见,但这个差异还是提醒我们要努力增加这个领域的性别多样性。
现如今,社交媒体和学术研究在AI/ML领域越来越紧密。从论文发表者的角度来说,为了扩大论文的影响力,在arxiv发表论文后,也可以考虑多多在社交媒体上宣传自己的工作。毕竟在这个信息爆炸的时代,“酒香也怕巷子深”!
也欢迎大家多多在“夕小瑶科技说”上分享自己有趣的工作哦~