论文速读:Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation
Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation
https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123490103.pdf
Abstract
Convolution exploits locality for efficiency at a cost of missing long range context. Self-attention has been adopted to augment CNNs with non-local interactions. Recent works prove it possible to stack self-attention layers to obtain a fully attentional network by restricting the attention to a local region.
In this paper, we attempt to remove this constraint by factorizing 2D self-attention into two 1D selfattentions. This reduces computation complexity and allows performing attention within a larger or even global region. In companion, we also propose a position-sensitive self-attention design. Combining both yields our position-sensitive axial-attention layer, a novel building block that one could stack to form axial-attention models for image classification and dense prediction.
We demonstrate the effectiveness of our model on four large-scale datasets. In particular, our model outperforms all existing stand-alone self-attention models on ImageNet. Our Axial-DeepLab improves 2.8% PQ over bottom-up state-of-the-art on COCO test-dev. This previous state-of-the-art is attained by our small variant that is 3.8× parameter-efficient and 27 × computation-efficient. Axial-DeepLab also achieves state-of-the-art results on Mapillary Vistas and Cityscapes.
卷积利用局部性来提高效率,但代价是丢失了长距离上下文。自注意被用来增强 CNN 的非局部交互。最近的研究表明,通过将注意力限制在局部区域,可以通过堆叠自注意层来获得一个完全注意网络。
本文试图通过将二维自注意分解为两个一维自注意来消除这种约束。这降低了计算复杂度,并允许在更大甚至全局区域内执行注意力。同时,本文也提出了位置敏感的自注意设计。结合这两种方法可以得到位置敏感轴向注意层,这是一种新型的构建块,可以将其叠加形成用于图像分类和密集预测的轴向注意模型。
本文在四个大规模数据集上证明了我们的模型的有效性。特别地,本文的模型优于 ImageNet 上所有现有的独立自注意模型。与自底向上的最先进的 COCO 测试开发相比,本文的 Axisal-DeepLab提高了 2.8% 的 PQ。这个先前最先进的技术是由本文的小型变种实现的,它的参数效率为 3.8x,计算效率为 27x。Axisal-DeepLab 还在 Mapillary Vista 和 Cityscape 上获得了最先进的结果。
Method
Position-Sensitive Self-Attention
Self-Attention
自注意:自注意机制通常被应用于视觉模型中,作为增加 CNN 输出的附加组件。给定一个输入特征 map, x ∈ R^{h×w×d_in},其中高度 h,宽度 w,和通道 d_in,在位置 o = (i, j) 的输出为 y_o ∈R {d_out} ,根据 (1)式计算了输入的预测。

其中,query 为 ![]() ,key 为
,key 为 ![]() ,value 为
,value 为 ![]()
该机制基于affinities ![]() ,将 v_p 值集中到全局,允许在整个特征图中捕获相关但非局部的上下文,而不是像卷积只捕获局部关系。然而,当输入的空间维度很大时,自注意的计算代价非常高 (O(h^2w^2)),限制了其使用,只能使用于下采样特征图或小图像。另一个缺点是,全局池化不能利用位置信息,而位置信息对于捕捉视觉任务中的空间结构或形状至关重要。
,将 v_p 值集中到全局,允许在整个特征图中捕获相关但非局部的上下文,而不是像卷积只捕获局部关系。然而,当输入的空间维度很大时,自注意的计算代价非常高 (O(h^2w^2)),限制了其使用,只能使用于下采样特征图或小图像。另一个缺点是,全局池化不能利用位置信息,而位置信息对于捕捉视觉任务中的空间结构或形状至关重要。
在 [65] (Stand-alone self-attention in vision models. In: NeurIPS (2019))中,通过向自注意添加局部约束和位置编码,这两个问题得到了缓解。对于每个位置 o,提取一个本地 mxm 平方区域作为内存库,用于计算输出 y_o。这大大减少了它的计算量到 O(hwm^2),允许自注意模块作为独立的层部署,以形成一个完全自注意的神经网络。
此外,一个学习到的相对位置编码项被合并到 affinities 中,产生一个动态的 ‘在接受区应该看哪里’ 的先验 (即,局部 mxm 的区域)。[65] 提出的方法可表示为公式

其中,N_{mxm}(o) 是以位置 o = (i, j) 为中心的局部 mxm 的正方形区域,可学习向量 ![]() 是添加的相对位置编码。内积
是添加的相对位置编码。内积 ![]() 度量从位置 p = (a, b) 到位置 o = (i, j) 的兼容性。
度量从位置 p = (a, b) 到位置 o = (i, j) 的兼容性。
本文不考虑绝对位置编码 ![]() ,因为与相对位置编码相比,它们没有很好地泛化 [65]。在下面几段中,为了简洁起见,省略了 “相对” 一词。
,因为与相对位置编码相比,它们没有很好地泛化 [65]。在下面几段中,为了简洁起见,省略了 “相对” 一词。
在实际中,d_q 和 d_out 比 d_in 要小得多,可以将式 (2) 中的单头注意扩展到多头注意,以捕捉 affinities 的混合。特别地,通过在 x_o 上并行地应用 N 个单点注意 (用不同的 ![]() ),然后将每个头的结果串接得到最终输出 z_o,即
),然后将每个头的结果串接得到最终输出 z_o,即 ![]() 。注意,位置编码通常在头之间共享,因此它们引入了额外的边缘参数。
。注意,位置编码通常在头之间共享,因此它们引入了额外的边缘参数。
Position-Sensitivity
注意到之前的位置偏差只取决于 query 像素 x_o,而不是 key 像素 x_p。但是,键 x_p 也可以有关于要注意的位置的信息。因此,除了依赖于查询的偏差 ![]() 外,本文还增加了一个与键相关的位置偏差项
外,本文还增加了一个与键相关的位置偏差项 ![]() 。
。
类似地,v_p 值在 Eq.(2) 中不包含任何位置信息。在大的接收域或存储库的情况下,y_o 不太可能包含 v_p 来自的精确位置。因此,以前的模型必须在使用更小的接收域 (即小 mxm 区域) 和抛弃精确的空间结构之间进行权衡。
本文使输出 y_o 能够根据查询键的 affinities ![]() 检索内容 v_p 之外的相对位置
检索内容 v_p 之外的相对位置 ![]() 。在形式上为公式(3)。
。在形式上为公式(3)。

其中,可学习的 ![]() 是 key 的位置编码,
是 key 的位置编码, ![]()
![]() 是值的位置编码。这两个向量都没有引入太多的参数,因为它们在一层的注意头之间共享,并且局部像素
是值的位置编码。这两个向量都没有引入太多的参数,因为它们在一层的注意头之间共享,并且局部像素 ![]() 的数量通常很小。
的数量通常很小。
将这种设计称为位置敏感的自注意,它可以在合理的计算开销下捕获具有精确位置信息的远程交互。

Axial-Attention
Stand-alone 自注意模型提出了局部约束,显著降低了视觉任务的计算成本。然而,这样的约束牺牲了全局连接,使得注意力的接收域不大于具有相同内核大小的深度卷积。此外,在局部正方形区域执行的局部自注意的复杂度仍然是区域长度的 2 次方,引入了另一个超参数来权衡性能和计算复杂度。
Stand-alone self-attention in vision models. In: NeurIPS (2019)
在本工作中,在独立的自注意中采用轴向注意,既保证了全局连接,又保证了高效的计算。具体来说,首先将图像的宽度轴上的轴向注意层定义为简单的一维位置敏感的自注意,并对高度轴使用类似的定义。具体来说,沿宽度轴的轴向注意层定义如下:

一个轴向注意层沿着一个特定的轴传播信息。为了获取全局信息,分别对高度轴和宽度轴连续使用了两个轴注意层。轴向注意层和轴向注意层均采用多头注意机制。轴向关注将复杂性降低到O(hwm)。这使全局接收域成为可能,这是通过直接设置跨度 m 到整个输入特征来实现的。也可以使用固定的 m 值,以减少大型特性图的内存占用。
Axial-ResNet
为了将 ResNet转换为 Axisal -ResNet,本文将残差瓶颈块(residual bottleneck block)中的 3x3 卷积替换为两个多头轴向注意层 (一个为高度轴,另一个为宽度轴)。在相应的轴注意层之后,在每个轴上进行可选的跨步。两个 1x1 卷积被保留来 shuffle 特征。这就形成了残差轴向注意块,如图 2 所示,该模块被多次堆叠以获得 Axisal-ResNets。
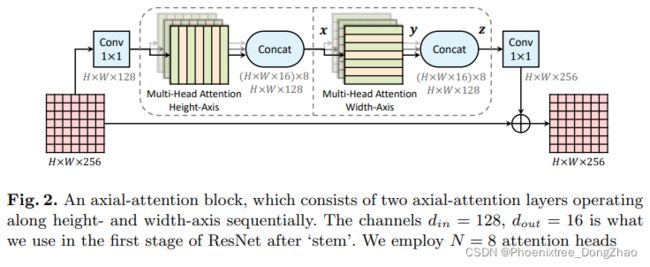
注意,本文没有在两个轴向注意层之间使用 1x1 卷积,因为矩阵乘法 (W_Q, W_K, W_V) 立即跟随。此外,保留了原始 ResNet 中的干 (即第一个跨步的 7x7 卷积和 3x3 max-pooling),从而得到了 conv-stem 模型,卷积在第一层使用,注意层在其他任何地方使用。在 convc -stem 模型中,将跨距 (span) m 设置为从第一个块开始的整个输入,其中 feature map 为 56x56。在实验中,本文还建立了一个全轴向注意模型,称为 full Axisal-ResNet,它进一步将轴向注意应用于 stem。本文并没有设计一个特殊的空间变化的注意力 stem,而是简单地堆叠三个轴向注意力瓶颈块。此外,为了降低计算成本,在 Full Axisal-ResNets 的前几个块中采用了局部约束 (即一个局部 mxm 平方区域)。
Axial- DeepLab:
为了进一步将 Axial-ResNet 转换为 Axial-DeepLab 用于分割任务,本文做了如下讨论的一些更改。
首先,为了提取密集的 feature map, DeepLab 改变 ResNet 中最后一个或两个阶段的 stride 和 atrous 速率。
类似地,删除了最后一个阶段的 stride,但没有实现 atrous 注意模块,因为轴向注意已经捕获了整个输入的全局信息。
本文用输出步幅 16 (即输入分辨率与最终骨干特征分辨率的比值) 提取特征映射。本文不追使用输出步幅 8,因为它的计算量很高。
其次,本文没有采用 atrous 空间金字塔池化模块 (ASPP) [13,14],因为本文的轴向注意块也可以有效地编码多尺度或全局信息。在实验中显示,没有 ASPP 的 Axisal-DeepLab 优于有 ASPP 和没有 ASPP 的 Panoptic-DeepLab。
最后,在 Panopic - DeepLab 之后,本文采用了三种卷积、双解码器和预测头的完全相同的干。头部产生语义分割和与类无关的实例分割,通过多数投票合并,形成最终的全景分割。在输入非常大(例如 2177x2177) 且内存有限的情况下,本文在所有轴向注意块中采用大跨度 m = 65。请注意,我们没有将轴向跨度视为一个超参数,因为它已经足够覆盖多个数据集上的长距离甚至全局上下文,设置较小的跨度并不会显著减少 M-Adds。
Panoptic-deeplab: A simple, strong, and fast baseline for bottom-up panoptic segmentation. In: CVPR (2020)