PyTorch图像分类从模型自定义到测试
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达01.什么是 Pytorch
一句话总结 Pytorch = Python + Torch。
Torch 是纽约大学的一个机器学习开源框架,几年前在学术界非常流行,包括 Lecun等大佬都在使用。但是由于使用的是一种绝大部分人绝对没有听过的 Lua 语言,导致很多人都被吓退。后来随着 Python 的生态越来越完善,Facebook 人工智能研究院推出了Pytorch并开源。Pytorch不是简单的封装 Torch并提供Python接口,而是对Tensor以上的所有代码进行了重构,同TensorFlow一样,增加了自动求导。
后来Caffe2全部并入Pytorch,如今已经成为了非常流行的框架。很多最新的研究如风格化、GAN 等大多数采用Pytorch源码,这也是我们必须要讲解它的原因。
1.1 特点
(1)动态图计算。TensorFlow从静态图发展到了动态图机制Eager Execution,pytorch则一开始就是动态图机制。动态图机制的好处就是随时随地修改,随处debug,没有类似编译的过程。
(2)简单。相比TensorFlow中Tensor、Variable、Session等概念充斥,数据读取接口频繁更新,tf.nn、tf.layers、tf.contrib各自重复,Pytorch则是从Tensor到Variable再到nn.Module,最新的Pytorch已经将Tensor和Variable合并,这分别就是从数据张量到网络的抽象层次的递进。有人调侃TensorFlow的设计是“make it complicated”,那么 Pytorch的设计就是“keep it simple”。
1.2 重要概念
(1)Tensor/Variable
每一个框架都有基本的数据结构,Caffe是blob,TensorFlow和Pytorch都是Tensor,都是高维数组。Pytorch中的Tensor使用与Numpy的数组非常相似,两者可以互转且共享内存。
tensor包括cpu和gpu两种类型,如torch.FloatTensortorch.cuda.FloatTensorvirable,就分别表示cpu和gpu下的32位浮点数。
tensor包含一些属性。data,即Tensor内容;Grad,是与data对应的梯度;requires_grad,是否容许进行反向传播的学习,更多的可以去查看API。
(2)nn.module
抽象好的网络数据结构,可以表示为网络的一层,也可以表示为一个网络结构,这是一个基类。在实际使用过程中,经常会定义自己的网络,并继承nn.Module。具体的使用,我们看下面的网络定义吧。
(3)torchvision包,包含了目前流行的数据集,模型结构和常用的图片转换工具
02.Pytorch 训练
安装咱们就不说了,接下来的任务就是开始训练模型。训练模型包括数据准备、模型定义、结果保存与分析。
2.1 数据读取
前面已经介绍了Caffe和TensorFlow的数据读取,两者的输入都是图片list,但是读取操作过程差异非常大,Pytorch与这两个又有很大的差异。这一次,直接利用文件夹作为输入,这是 Pytorch更加方便的做法。数据读取的完整代码如下:
data_dir = '../../../../datas/head/'
data_transforms = {
'train': transforms.Compose([
transforms.RandomSizedCrop(48),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])
]),
'val': transforms.Compose([
transforms.Scale(64),
transforms.CenterCrop(48),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])
]),
}
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x]) for x in ['train', 'val']}
dataloders = {x: torch.utils.data.DataLoader(image_datasets[x],
batch_size=16,
shuffle=True,
num_workers=4) for x in ['train', 'val']}
下面一个一个解释,完整代码请移步 Git 工程。
(1)datasets.ImageFolder
Pytorch的torchvision模块中提供了一个dataset 包,它包含了一些基本的数据集如mnist、coco、imagenet和一个通用的数据加载器ImageFolder。
它会以这样的形式组织数据,具体的请到Git工程中查看。
root/left/1.png
root/left/2.png
root/left/3.png
root/right/1.png
root/right/2.png
root/right/3.png
imagefolder有3个成员变量。
self.classes:用一个list保存类名,就是文件夹的名字。
self.class_to_idx:类名对应的索引,可以理解为 0、1、2、3 等。
self.imgs:保存(imgpath,class),是图片和类别的数组。
不同文件夹下的图,会被当作不同的类,天生就用于图像分类任务。
(2)Transforms
这一点跟Caffe非常类似,就是定义了一系列数据集的预处理和增强操作。到此,数据接口就定义完毕了,接下来在训练代码中看如何使用迭代器进行数据读取就可以了,包括 scale、减均值等。
(3)torch.utils.data.DataLoader
这就是创建了一个 batch,生成真正网络的输入。关于更多 Pytorch 的数据读取方法,请自行学习。
2.2 模型定义
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class simpleconv3(nn.Module):`
def __init__(self):
super(simpleconv3,self).__init__()
self.conv1 = nn.Conv2d(3, 12, 3, 2)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(12, 24, 3, 2)
self.bn2 = nn.BatchNorm2d(24)
self.conv3 = nn.Conv2d(24, 48, 3, 2)
self.bn3 = nn.BatchNorm2d(48)
self.fc1 = nn.Linear(48 * 5 * 5 , 1200)
self.fc2 = nn.Linear(1200 , 128)
self.fc3 = nn.Linear(128 , 2)
def forward(self , x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = x.view(-1 , 48 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
我们的例子都是采用一个简单的3层卷积 + 2层全连接层的网络结构。根据上面的网络结构的定义,需要做以下事情。
(1)simpleconv3(nn.Module)
继承nn.Module,前面已经说过,Pytorch的网络层是包含在nn.Module 里,所以所有的网络定义,都需要继承该网络层,并实现super方法,如下:
super(simpleconv3,self).__init__()
这个就当作一个标准执行就可以了。
(2)网络结构的定义都在nn包里,举例说明:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
完整的接口如上,定义的第一个卷积层如下:
nn.Conv2d(3, 12, 3, 2)
即输入通道为3,输出通道为12,卷积核大小为3,stride=2,其他的层就不一一介绍了,大家可以自己去看nn的API。
(3)forward
backward方法不需要自己实现,但是forward函数是必须要自己实现的,从上面可以看出,forward 函数也是非常简单,串接各个网络层就可以了。
对比Caffe和TensorFlow可以看出,Pytorch的网络定义更加简单,初始化方法都没有显示出现,因为 Pytorch已经提供了默认初始化。
如果我们想实现自己的初始化,可以这么做:
init.xavier_uniform(self.conv1.weight)init.constant(self.conv1.bias, 0.1)
它会对conv1的权重和偏置进行初始化。如果要对所有conv层使用 xavier 初始化呢?可以定义一个函数:
def weights_init(m):
if isinstance(m, nn.Conv2d):
xavier(m.weight.data)
xavier(m.bias.data)
net = Net()
net.apply(weights_init)
03.模型训练
网络定义和数据加载都定义好之后,就可以进行训练了,老规矩先上代码:
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
for phase in ['train', 'val']:
if phase == 'train':
scheduler.step()
model.train(True)
else:
model.train(False)
running_loss = 0.0 running_corrects = 0.0
for data in dataloders[phase]:
inputs, labels = data
if use_gpu:
inputs = Variable(inputs.cuda())
labels = Variable(labels.cuda())
else:
inputs, labels = Variable(inputs), Variable(labels)
optimizer.zero_grad()
outputs = model(inputs)
_, preds = torch.max(outputs.data, 1)
loss = criterion(outputs, labels)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.data.item()
running_corrects += torch.sum(preds == labels).item()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects / dataset_sizes[phase]
if phase == 'train':
writer.add_scalar('data/trainloss', epoch_loss, epoch)
writer.add_scalar('data/trainacc', epoch_acc, epoch)
else:
writer.add_scalar('data/valloss', epoch_loss, epoch)
writer.add_scalar('data/valacc', epoch_acc, epoch)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
writer.export_scalars_to_json("./all_scalars.json")
writer.close()
return model
分析一下上面的代码,外层循环是epoches,然后利用 for data in dataloders[phase] 循环取一个epoch 的数据,并塞入variable,送入model。需要注意的是,每一次forward要将梯度清零,即optimizer.zero_grad(),因为梯度会记录前一次的状态,然后计算loss进行反向传播。
loss.backward()
optimizer.step()
下面可以分别得到预测结果和loss,每一次epoch 完成计算。
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects / dataset_sizes[phase]
_, preds = torch.max(outputs.data, 1)
loss = criterion(outputs, labels)
可视化是非常重要的,鉴于TensorFlow的可视化非常方便,我们选择了一个开源工具包,tensorboardx,安装方法为pip install tensorboardx,使用非常简单。
第一步,引入包定义创建:
from tensorboardX import SummaryWriter
writer = SummaryWriter()
第二步,记录变量,如train阶段的 loss,writer.add_scalar('data/trainloss', epoch_loss, epoch)。
按照以上操作就完成了,完整代码可以看配套的Git 项目,我们看看训练中的记录。Loss和acc的曲线图如下:
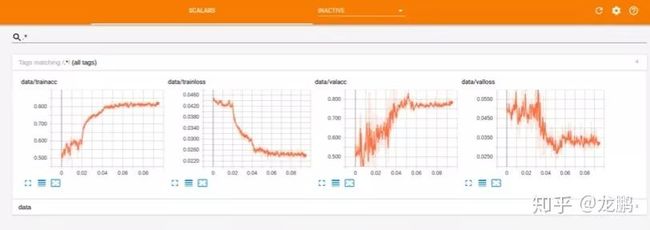
网络的收敛没有Caffe和TensorFlow好,大家可以自己去调试调试参数了,随便折腾吧。
04.Pytorch 测试
上面已经训练好了模型,接下来的目标就是要用它来做inference了,同样给出代码。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
from torch.autograd import Variable
import torchvision
from torchvision import datasets, models, transforms
import time
import os
from PIL import Image
import sys
import torch.nn.functional as F
from net import simpleconv3
data_transforms = transforms.Compose([
transforms.Resize(48),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])])
net = simpleconv3()
modelpath = sys.argv[1]
net.load_state_dict(torch.load(modelpath,map_location=lambda storage,loc: storage))
imagepath = sys.argv[2]
image = Image.open(imagepath)
imgblob = data_transforms(image).unsqueeze(0)
imgblob = Variable(imgblob)
torch.no_grad()
predict = F.softmax(net(imgblob))
print(predict)
从上面的代码可知,做了几件事:
定义网络并使用torch.load和load_state_dict载入模型。
用PIL的Image包读取图片,这里没有用OpenCV,因为Pytorch默认的图片读取工具就是PIL的Image,它会将图片按照RGB的格式,归一化到 0~1 之间。读取图片之后,必须转化为Tensor变量。
evaluation的时候,必须设置torch.no_grad(),然后就可以调用 softmax 函数得到结果了。
05.总结
本节讲了如何用 Pytorch 完成一个分类任务,并学习了可视化以及使用训练好的模型做测试。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

