暂退法dropout----详解与分析(多层感知机)
文章目录
-
- 暂退法
-
- 暂退法原理公式分析
- 从零开始实现
-
- 定义暂退函数
- 定义模型参数
- 定义模型
- 训练和测试
- 简洁实现
暂退法
暂退法(Dropout),同 L 2 L_2 L2 正则化的目标一致,也是处理神经网络模型 过拟合(训练集拟合程度高,测试集拟合程度低) 的一种有效方法。
大家可以想一下,为什么神经网络模型会出现过拟合这种现象呢?
其中主要原因有以下几种
- 样本数据分布区间不稳定,样本值会出现范围很大的变化区间
- 神经网络模型过于复杂,神经元过多,考虑了过多不必要的样本特征
- 训练样本少
其中,第一种过拟合原因我们可以通过数据预处理、数据缩放等方法解决,第三种过拟合方法我们可以添加样本数据集的方法解决。
针对于第二种过拟合方法,我们便可以使用暂退法解决,它的主要思想是通过减少神经网络隐藏层中隐藏单元的数量来降低模型复杂度,从而避免过拟合。
原理图如下:

暂退法原理公式分析
暂退法的详细实现步骤是通过人为输入的一个概率p来确定舍弃单元数量的,当 p = 0 p = 0 p=0 时,代表不去除隐藏单元,当 p = 1 p = 1 p=1 时,则去除所有隐藏单元。
它的具体公式如下:
h ′ = { 0 , 概率为 p ( 可以认为小于概率 p 的值均为 0 ) h 1 − p , 其它情况 ( 可以认为大于概率 p 是的取值 ) h' = \begin{cases}0, 概率为p(可以认为小于概率p的值均为0) \\ \frac{h}{1-p}, 其它情况(可以认为大于概率p是的取值)\end{cases} h′={0,概率为p(可以认为小于概率p的值均为0)1−ph,其它情况(可以认为大于概率p是的取值)
我们可以分析下该暂退法算法(出自李沐老师的《动手学深度学习》):
import torch
def dropout_layer(X, dropout): #dropout即参数概率 p
assert 0 <= dropout <= 1 #概率p必须大于等于0,小于等于 1
if dropout == 1:
return torch.zeros_like(X) #将所有X重置为0,此时无论X与哪个矩阵作乘法,始终为0,可视为消去了所有隐藏单元
if dropout == 0:
return X #即不对X作任何改变,不使用暂退法
#返回一个符合概率p的(0,1)分布张量,大于p的x为1, 小于p的x为0,这样就实现了一般情况
#小于概率p的x置为0, 大于概率p的x置为1
mask = (torch.rand(X.shape) > dropout).float()
return (mask * X) / (1 - dropout) # 返回应用过暂退法(dropout)后的X隐藏单元
现在先定义一个X,如下
X = torch.arange(16).reshape((2,8))
X
tensor([[ 0, 1, 2, 3, 4, 5, 6, 7],
[ 8, 9, 10, 11, 12, 13, 14, 15]])
假如此时我设置暂退概率为 1, 则返回
torch.zeros_like(X)
tensor([[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0]])
此时可以看到,所有的神经单元值均为0, 它与任何值相乘均为0,故删除了所有隐藏单元。
现在设置暂退概率为 0,则返回
X
tensor([[ 0, 1, 2, 3, 4, 5, 6, 7],
[ 8, 9, 10, 11, 12, 13, 14, 15]])
表示不会进行删除任何隐藏单元,不应用暂退法。
现在我们设置暂退概率 p = 0.5,则
rand_num = torch.rand(X.shape) #随机生成一个2*8的张量,代表随机概率
rand_num
tensor([[0.5991, 0.8182, 0.1398, 0.3372, 0.8484, 0.1511, 0.0581, 0.4121],
[0.2145, 0.1434, 0.3349, 0.6356, 0.3669, 0.5025, 0.8767, 0.8602]])
此时将所有大于概率0.5的值设置为1,否则置为0, 则(生成的张量对应公式的其它情况)
mask = (rand_num > 0.5).float() #将所有大于概率0.5的值置为1,否则置为0
mask
tensor([[1., 1., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 1., 0., 1., 1., 1.]])
现在计算应用暂退法(p=0.5)后的神经元张量:
dropout_X = (mask * X) / (1 - 0.5)
dropout_X
tensor([[ 0., 2., 0., 0., 8., 0., 0., 0.],
[ 0., 0., 0., 22., 0., 26., 28., 30.]])
所以此时我们就得到了暂退概率为0.5的新的神经单元张量。
从零开始实现
定义暂退函数
如上,定义模型所需要的暂退函数
import torch
from torch import nn
from d2l import torch as d2l
def dropout_layer(X, dropout): #dropout即参数概率 p
assert 0 <= dropout <= 1 #概率p必须大于等于0,小于等于 1
if dropout == 1:
return torch.zeros_like(X) #将所有X重置为0,此时无论X与哪个矩阵作乘法,始终为0,可视为消去了所有隐藏单元
if dropout == 0:
return X #即不对X作任何改变,不使用暂退法
#返回一个符合概率p的(0,1)分布张量,大于p的x为1, 小于p的x为0,这样就实现了一般情况
#小于概率p的x置为0, 大于概率p的x置为1
mask = (torch.rand(X.shape) > dropout).float()
return (mask * X) / (1 - dropout) # 返回应用过暂退法(dropout)后的X隐藏单元
我们可以通过下面几个例子来测试dropout_layer函数。 我们将输入X通过暂退法操作,暂退概率分别为0、0.5和1。
X = torch.arange(16).reshape((2,8)) #定义X张量
#分别设定暂退概率为 1、0、0.2、0.5
dropout_layer(X, 1), dropout_layer(X, 0), dropout_layer(X, 0.2), dropout_layer(X, 0.5)
(tensor([[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0]]),
tensor([[ 0, 1, 2, 3, 4, 5, 6, 7],
[ 8, 9, 10, 11, 12, 13, 14, 15]]),
tensor([[ 0.0000, 1.2500, 2.5000, 3.7500, 5.0000, 6.2500, 7.5000, 8.7500],
[10.0000, 11.2500, 12.5000, 13.7500, 15.0000, 0.0000, 17.5000, 0.0000]]),
tensor([[ 0., 2., 0., 0., 8., 10., 0., 0.],
[16., 18., 0., 22., 24., 0., 28., 30.]]))
定义模型参数
同样,我们使用之前引入的Fashion-MNIST数据集。 我们定义具有两个隐藏层的多层感知机,每个隐藏层包含256个单元。
#定义特征个数、隐层1的隐单元、隐层2的隐单元、输出类别个数
num_inputs, num_hiddens1, num_hiddens2, num_outputs = 784, 256, 256, 10
定义模型
我们可以将暂退法应用于每个隐藏层的输出(在激活函数之后), 并且可以为每一层分别设置暂退概率: 常见的技巧是在靠近输入层的地方设置较低的暂退概率。 下面的模型将第一个和第二个隐藏层的暂退概率分别设置为0.2和0.5, 并且暂退法只在训练期间有效。
dropout1, dropout2 = 0.2, 0.5 #设置隐层1、隐层2的暂退概率
class Net(nn.Module):
#神经网络的初始化操作
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2, is_training=True):
super(Net,self).__init__() #父类初始化
self.num_inputs = num_inputs #输入特征数量
self.is_training = is_training #输入训练标志
self.lin1 = nn.Linear(num_inputs, num_hiddens1) #线性模型1
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2) #线性模型2
self.lin3 = nn.Linear(num_hiddens2, num_outputs) #线性模型3
self.relu = nn.ReLU() #激活函数
def forward(self, X):
#计算出隐层H1的隐单元值
H1 = self.relu(self.lin1(X.reshape((-1, num_inputs))))
#在第一个全连接层后添加暂退dropout层
if self.is_training == True:
H1 = dropout_layer(H1, dropout1) #为隐藏层H1添加暂退概率,减少模型的复杂度
H2 = self.relu(self.lin2(H1))
#在第二个全连接层后添加暂退dropout层
if self.is_training == True:
H2 = dropout_layer(H2, dropout2) #为隐藏层H2添加暂退概率,减少模型的复杂度
out = self.lin3(H2) #输出分类的类别分布概率
return out
#深度学习模型net
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
训练和测试
这类似于前面描述的多层感知机训练和测试。
num_epochs, lr, batch_size = 10, 0.5, 256 #定义迭代次数10,学习率0.5, 小批量样本数据集为256
loss = nn.CrossEntropyLoss(reduction='none') #定义交叉熵损失函数
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size) #获取训练集迭代器和测试集迭代器
updater = torch.optim.SGD(net.parameters(), lr) #定义优化函数,更新权重
#开始训练数据集
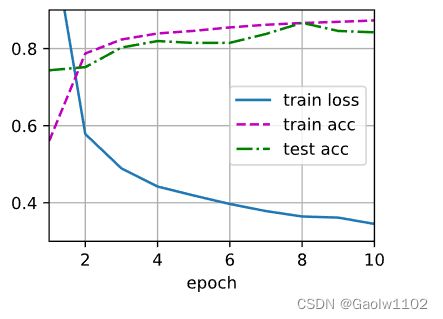
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
简洁实现
对于深度学习框架的高级API,我们只需在每个全连接层之后添加一个Dropout层, 将暂退概率作为唯一的参数传递给它的构造函数。 在训练时,Dropout层将根据指定的暂退概率随机丢弃上一层的输出(相当于下一层的输入)。 在测试时,Dropout层仅传递数据。
#使用pytorch高级API直接定义神经网络net
net_concise = nn.Sequential(nn.Flatten(), #降维打击函数,把高阶的图片张量数据展开为一阶
nn.Linear(num_inputs, num_hiddens1), #定义第一个线性模型,从输入特征层到隐层1层的模型
nn.ReLU(), #应用激活函数
nn.Dropout(dropout1), #应用暂退函数
nn.Linear(num_hiddens1, num_hiddens2), #定义第二个线性模型,从隐层1层到隐层2层的模型
nn.ReLU(), #应用激活函数
nn.Dropout(dropout2), #应用暂退函数
nn.Linear(num_hiddens2, num_outputs)) #定义第三个线性模型,从隐层2层到输出层的模型
#以正态分布初始化神经网络权重
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net_concise.apply(init_weights)
Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=784, out_features=256, bias=True)
(2): ReLU()
(3): Dropout(p=0.2, inplace=False)
(4): Linear(in_features=256, out_features=256, bias=True)
(5): ReLU()
(6): Dropout(p=0.5, inplace=False)
(7): Linear(in_features=256, out_features=10, bias=True)
)
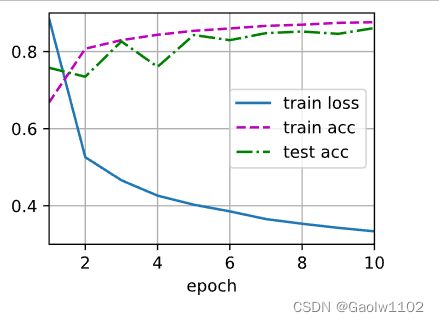
接下来,我们对模型进行训练和测试。
updater_concise = torch.optim.SGD(net_concise.parameters(), lr)
d2l.train_ch3(net_concise, train_iter, test_iter, loss, num_epochs, updater_concise)