AlexNet模型详解及代码实现
AlexNet模型详解及代码实现
- 一、 背景
-
-
- 1. ReLU非线性
- 2. GPU并行训练
- 3. 局部响应归一化(Local Response Normalization)
- 4. 重叠池化(Overlapping Pooling)
- 5. Dropout
- 6. 数据增强(Data Augmentation)
-
- 二、AlexNet网络模型详解及代码实现
-
- 1. AlexNet模型详解
- 2. 代码实现
- 三、参考资料
一、 背景
AlexNet是在2012年由Alex Krizhevsky等人提出的,该网络在ImageNet大赛上夺得了冠军,并且错误率比第二名高了很多。
论文地址:ImageNet Classification with Deep Convolutional Neural Networks
AlexNet论文中的亮点:
- 使用ReLU激活函数加速收敛
- 使用两个 GPU 并行,加速训练。
- 提出局部响应归一化(Local Response Normalization, LRN)增加泛化特性
- 使用了重叠池化(Overlapping Pooling)避免过拟合。
- 使用Dropout机制和数据增强策略减少过拟合
1. ReLU非线性
激活函数一般采用tanh或者sigmoid,但是tanh和sigmoid都是饱和激活函数,考虑到梯度下降的训练时间问题,所以引入了修正线性单元(ReLU)作为激活函数,即: f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x),其不存在饱和区,导数始终为1,梯度更大,计算量也更少,训练时间也越快。
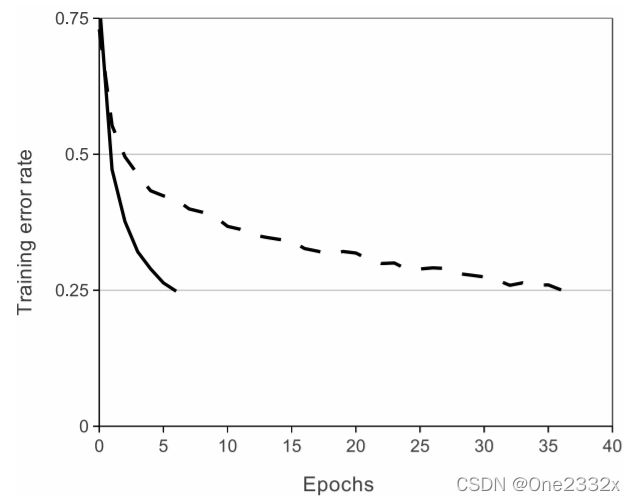
tanh(虚线)与ReLU(实线)的收敛速度对比如下图所示:
补充: 饱和非线性和非饱和非线性
- 饱和非线性
饱和的激活函数会将输出结果缩放到有限的区间,例如:
tanh激活函数为 f ( x ) = e x − e − x e x + e − x f(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}} f(x)=ex+e−xex−e−x的范围是[-1,1],所以它是饱和的。

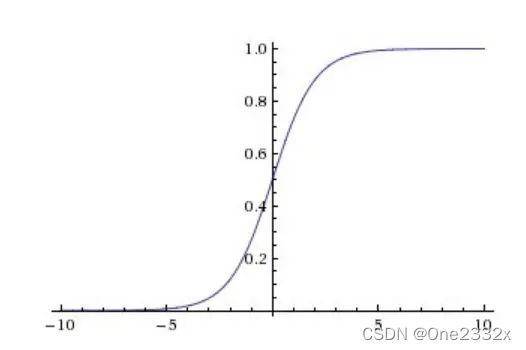
sigmoid激活函数为 f ( x ) = 1 1 + e − x f(x)=\frac{1}{1+e^{-x}} f(x)=1+e−x1,它的范围是[0,1],所以它是饱和的。
- 非饱和非线性
非饱和的激活函数会将输出结果缩放到无穷区间。即: ( ∣ lim z → − ∞ F ( z ) ∣ = + ∞ ) ∨ ( ∣ lim z → + ∞ F ( z ) ∣ = + ∞ (|\lim\limits_{z \rightarrow-\infty}F(z)|=+\infty)∨(|\lim\limits_{z\rightarrow+\infty}F(z)|=+\infty (∣z→−∞limF(z)∣=+∞)∨(∣z→+∞limF(z)∣=+∞
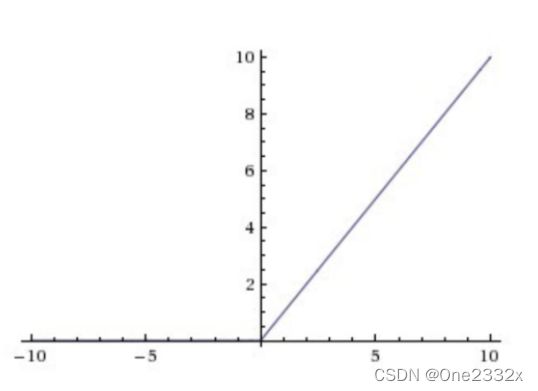
ReLu激活函数为 f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x),当 x x x趋近于正无穷时, f ( x ) f(x) f(x)也趋近于正无穷,所以该函数是饱和的。
2. GPU并行训练
单个GTX 580 GPU只有3GB内存,这限制了能由它训练出网络的最大规模,在论文中,作者提出用两个GPU来训练网络,当前的GPU能够很方便的进行交叉GPU并行,因为它们可以直接相互读取内存,而不用经过主机内存。作者采取的并行化方式是 每个GPU放一半的核(或者神经元),另外还有一个小技巧:GPU只在特定层之间通信。例如第三层的输入为第二层的所有特征图。但是,第四层的输入仅仅是第三层在同一GPU上的特征图。在交叉验证时,连接模式的选择是一个问题,而这个也恰好允许我们精确地调整通信的数量,直到他占计算数量的一个合理比例,如下图所示。
3. 局部响应归一化(Local Response Normalization)
在神经生物学有一个概念叫做侧抑制(lateral inhibitio),指的是被激活的神经元抑制相邻神经元。归一化(normalization)的目的是“抑制”,局部归一化就是借鉴了侧抑制的思想来实现局部抑制,尤其当我们使用ReLU 的时候这种“侧抑制”很管用。因为ReLU的响应结果是无界的(可以非常大)所以需要归一化。
局部响应归一化 (LRN) 的核心思想就是利用近邻数据进行归一化,其公式如下图所示:
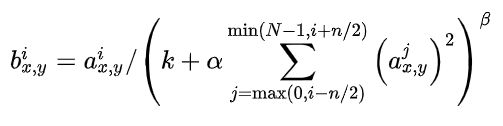
其中: a x , y i a^i_{x,y} ax,yi表示第i个卷积核,作用于位置 ( x , y ) (x,y) (x,y)然后进行ReLU后,得到的神经元输出。N表示该层卷积核的总数目。 k , n , α , β k,n,α,β k,n,α,β为超参数,其值通过验证集确定。 n n n表示同一位置上,领近的卷积核的数目。
但是,LRN是有争议的,在论文Very Deep Convolutional Networks for Large-Scale Image Recognition中指出LRN基本没有什么作用。
4. 重叠池化(Overlapping Pooling)
在LeNet中池化是不重叠的,即池化窗口的大小 z z z和滑动步长 s s s是相等的,在AlexNet中使用的池化(Pooling)却是可重叠的,也就是说,在池化的时候,每次移动的步长小于池化的窗口长度及( s < z s
5. Dropout
结合不同模型的预测值,是一种减小测试误差的不错的方式,但是其代价极其昂贵。因此,使用 dropout 技术,以 0.5 的概率,将每个隐藏神经元的值设定为 0。被 dropout 的神经元将不参与前向和反向传播。
在训练阶段的每次前向传播中,都会重新进行 dropout。因此,每次有新的输入时,模型会被随机采样成不同的架构,但是所有的架构共享权值。该技术可以减少神经元之间的相互依赖性。因此,模型被强制学习更加稳健的特征。
在论文中,作者在测试时,使用所有的神经元,并将其输出值乘以 0.5,以保证总的等效输出值不变,在网络的的前两层全连接层之间使用 dropout。如果不使用 dropout ,模型可能会过拟合,但是使用 dropout,模型训练将需要近两倍的迭代次数。
dropout详解可以参考博客:深度学习中Dropout原理解析
6. 数据增强(Data Augmentation)
论文中提出了两种特殊的数据增强方式,这两种方式都可以从原始图像通过非常少的计算量产生变换的图像,因此变换图像不需要存储在硬盘上。在我们的实现中,变换图像通过CPU的Python代码生成,而此时GPU正在训练前一批图像。因此,实际上这些数据增强方案是计算免费的。
第一种数据增强方式包括产生图像变换和水平翻转。做法就是从256×256图像上通过随机提取224 × 224的图像块实现了这种方式,然后在这些提取的图像块上进行训练。这通过一个2048因子增大了训练集,尽管最终的训练样本是高度相关的。没有这个方案,网络会有大量的过拟合问题,这会迫使我们使用更小的网络。在测试时,网络会提取5个224 × 224的图像块(四个角上的图像块和中心的图像块)和它们的水平翻转(因此总共10个图像块)进行预测,然后对网络在10个图像块上的softmax层进行平均。
第二种数据增强的方式包括改变训练图像的RGB通道的强度。特别的,本文对整个ImageNet训练集的RGB像素值进行了PCA。对每一幅训练图像,本文加上多倍的主成分,倍数的值为相应的特征值乘以一个均值为0标准差为0.1的高斯函数产生的随机变量。因此对每一个RGB图像像素 I x y = [ I x y R , I x y G , I x y B ] T I_{xy}=[I^R_{xy},I^G_{xy},I^B_{xy}]^T Ixy=[IxyR,IxyG,IxyB]T加上 [ p 1 , p 2 , p 3 ] [ α 1 λ 1 , α 2 λ 2 , α 3 λ 3 ] T [p_1,p_2,p_3][α_1λ_1,α_2λ_2,α_3λ_3]^T [p1,p2,p3][α1λ1,α2λ2,α3λ3]T,其中 p i , λ i p_i,λ_i pi,λi分别是RGB像素值3 × 3协方差矩阵的第i ii个特征向量和特征值, α i α_i αi是前面提到的随机变量。对于某个训练图像的所有像素,每个 α i α_i αi只获取一次,直到图像进行下一次训练时才重新获取。这个方案近似抓住了自然图像的一个重要特性,即光照的颜色和强度发生变化时,目标身份是不变的。这个方案减少了top 1错误率1%以上。
二、AlexNet网络模型详解及代码实现
1. AlexNet模型详解
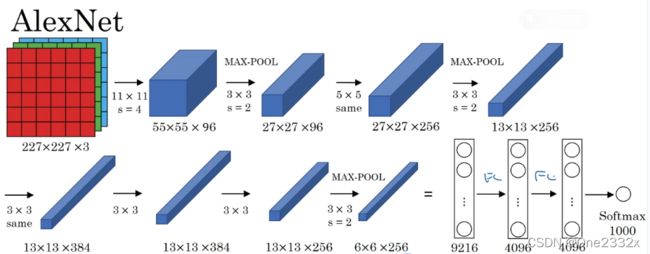
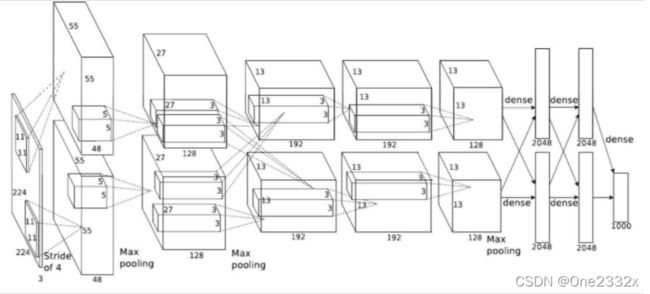
如上图所示,AlexNet网络结构是由5个卷积层和3个全连接层组成。
详细过程为:
- Conv1
- 输入图像大小: 224 * 224 * 3(RGB图像),但是会将输入图像预处理为227 * 227 * 3的图像
- 卷积核(filter)大小:11 * 11
- 卷积核个数:96
- 步长(stride):4
- padding方式:VALID
- 输出featureMap大小:55 * 55 * 96 [(227-11+0)/4+1=55]
- Pool1
- 输入图像大小:55 * 55 * 96
- 采样大小:3 * 3
- 步长:2
- padding方式:VALID
- 输出featureMap大小:27 * 27 * 96 [(55-3)/2+1=27]
- Conv2
- 输入图像大小: 27 * 27 * 96
- 卷积核(filter)大小:5 * 5
- 卷积核个数:256
- 步长(stride):1
- padding方式:SAME
- 输出featureMap大小:27 * 27 * 256
- Pool2
- 输入图像大小:27 * 27 * 256
- 采样大小:3 * 3
- 步长:2
- padding方式:VALID
- 输出featureMap大小:13 * 13 * 256 [(27-3)/2+1=13]
- Conv3
- 输入图像大小: 13 * 13 * 256
- 卷积核(filter)大小:3 * 3
- 卷积核个数:384
- 步长(stride):1
- padding方式:SAME
- 输出featureMap大小:13 * 13 * 384
- Conv4
- 输入图像大小: 13 * 13 * 384
- 卷积核(filter)大小:3 * 3
- 卷积核个数:384
- 步长(stride):1
- padding方式:SAME
- 输出featureMap大小:13 * 13 * 384
- Conv5
- 输入图像大小: 13 * 13 * 384
- 卷积核(filter)大小:3 * 3
- 卷积核个数:256
- 步长(stride):1
- padding方式:SAME
- 输出featureMap大小:13 * 13 * 256
- Pool3
- 输入图像大小:13 * 13 * 256
- 采样大小:3 * 3
- 步长:2
- padding方式:VALID
- 输出featureMap大小:6 * 6 * 256 [(13-3)/2+1=6]
- FC6
全连接层,这里使用4096个神经元,对256个大小为6X6特征图,进行一个全连接,也就是将6X6大小的特征图,进行卷积变为一个特征点,然后对于4096个神经元中的一个点,是由256个特征图中某些个特征图卷积之后得到的特征点乘以相应的权重之后,再加上一个偏置得到,之后再进行一个dropout操作,也就是随机从4096个节点中丢掉一些节点信息(清0操作),然后就得到新的4096个神经元。 - FC7
同上 - F8
采用的是1000个神经元,然后对FC7中4096个神经元进行全连接,然后通过sofmax,得到1000个类别的概率值,也就是预测值。
2. 代码实现
from keras.models import Sequential
from keras.layers import Dense, Flatten, Dropout
from keras.layers.convolutional import Conv2D, MaxPooling2D
import numpy as np
seed = 7
np.random.seed(seed)
# 创建模型序列
model = Sequential()
# 第一层卷积网络,使用96个卷积核,大小为11x11步长为4, 要求输入的图片为227x227, 3个通道,不填充,激活函数使用relu
model.add(Conv2D(96, (11, 11), strides=(4, 4), input_shape=(227, 227, 3), padding='valid', activation='relu',
kernel_initializer='uniform'))
# 池化层
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
# 第二层卷积
model.add(Conv2D(256, (5, 5), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform'))
# 池化层
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
# 第三层卷积
model.add(Conv2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform'))
# 第四层卷积
model.add(Conv2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform'))
# 第五层卷积
model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
model.summary()
运行结果如下:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 55, 55, 96) 34944
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 27, 27, 96) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 27, 27, 256) 614656
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 13, 13, 256) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 13, 13, 384) 885120
_________________________________________________________________
conv2d_3 (Conv2D) (None, 13, 13, 384) 1327488
_________________________________________________________________
conv2d_4 (Conv2D) (None, 13, 13, 256) 884992
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 6, 6, 256) 0
_________________________________________________________________
flatten (Flatten) (None, 9216) 0
_________________________________________________________________
dense (Dense) (None, 4096) 37752832
_________________________________________________________________
dropout (Dropout) (None, 4096) 0
_________________________________________________________________
dense_1 (Dense) (None, 4096) 16781312
_________________________________________________________________
dropout_1 (Dropout) (None, 4096) 0
_________________________________________________________________
dense_2 (Dense) (None, 1000) 4097000
=================================================================
Total params: 62,378,344
Trainable params: 62,378,344
Non-trainable params: 0
_________________________________________________________________
三、参考资料
AlexNet 论文详解
AlexNet 论文翻译——中英文对照
【CNN模型笔记(二)】AlexNet模型+代码实现
Alexnet网络结构详解
初探Alexnet网络结构