深度学习视频基础(四):误差反向传播算法
4、反向传播算法
4.1计算图
反向传播算法又称误差反向传播、BP算法( Backpropagation,缩写为BP)。
BP算法的学习过程由正向传播过程和反向传播过程组成。
在正向传播过程中,输入信息通过输入层经隐含层,逐层处理并传向输出层。如果在输出层得不到期望的输出值,则取输出与期望之间的差异作为损失值,转入反向传播,逐层求出目标函数对各神经元权值的偏导数,构成目标函数对权值向量的梯量,作为修改权值的依据,网络的学习在权值修改过程中完成。误差达到所期望值时,网络学习结束。
前向传播:
前向传播:输入层数据开始从前向后,数据逐步传递至输出层。
反向传播:损失函数开始从后向前,梯度逐步传递至第一层
反向传播作用:用于权重更新,使网络输出更接近标签。

梯度下降:沿梯度负方向更新,是目标值减小。
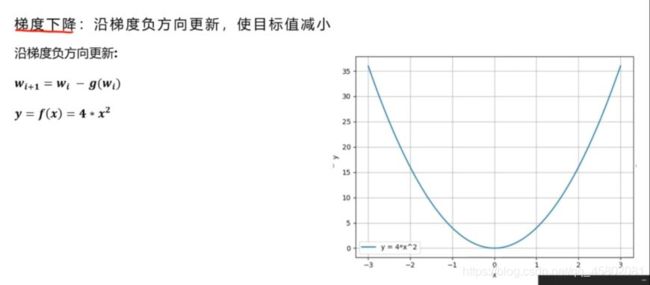
如:f(x)=4*x2
x0 = 1,y = 16
我们想要y值减小,
求偏导8x,x0的偏导值16.
梯度负方向更新:
x1 = x0 - 偏导值16 = -14.
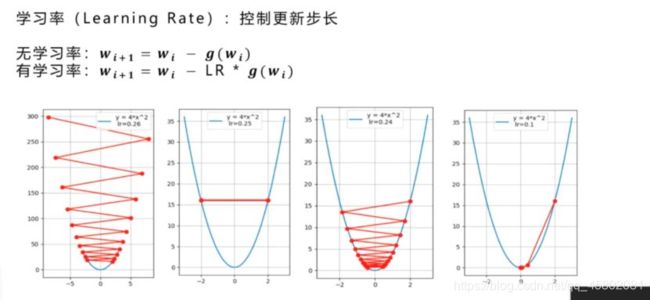
很明显,x1=-14时,y值更大,所以要注意学习率RL问题。

学习率(Learning Rate):控制步长。
**
4.1.1计算图
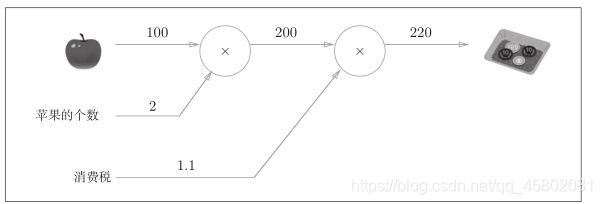
例1:太郎在超市买了2个100日元一个的苹果,消费税是10%,请计算支付金额。
如图:

可以将“2”和“1.1”分别作为变量“苹果的个数”和“消费税”标在○外面。
例2:
太郎在超市买了2个苹果、3个橘子。其中,苹果每个100日元,橘子每个150日元。消费税是10%,请计算支付金额。
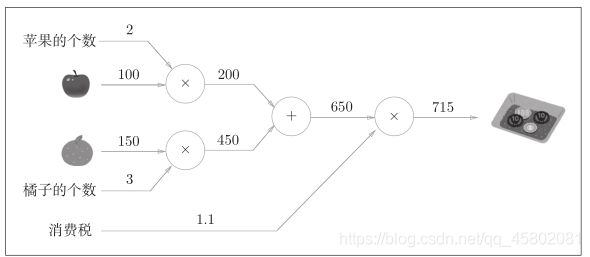
计算结果从左向右传递
如下流程进行:

“从左向右进行计算”是一种正方向上的传播,简称为正向传播(forward propagation)。正向传播是从计算图出发点到结束点的传播。
从图上看的话,就是从右向左的传播。实际上,这种传播称为反向传播(backward propagation)。
4.1.2 局部计算
计算图的特征是可以通过传递“局部计算”获得最终结果。“局部”这个词的意思是“与自己相关的某个小范围”。局部计算是指,无论全局发生了什么,都能只根据与自己相关的信息输出接下来的结果。
例:在超市买了2个苹果和其他很多东西
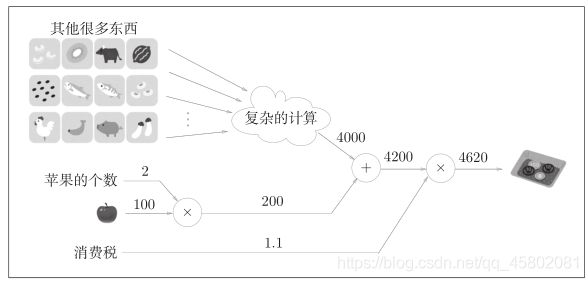
假设(经过复杂的计算)购买的其他很多东西总共花费4000日元。这里的重点是,各个节点处的计算都是局部计算。这意味着,例如苹果和其他很多东西的求和运算(4000 + 200 → 4200)并不关心4000这个数字是如何计算而来的,只要把两个数字相加就可以了。换言之,各个节点处只需进行与自己有关的计算(在这个例子中是对输入的两个数字进行加法运算),不用考虑全局。
计算图可以集中精力于局部计算。无论全局的计算有多么复杂,各个步骤所要做的就是对象节点的局部计算。
4.1.3利用计算图解题
使用计算图最大的原因是,可以通过反
向传播高效计算导数。
例1中,我们计算了购买2个苹果时加上消费税最终需要支付的金额。这里,假设我们想知道苹果价格的上涨会在多大程度上影响最终的支付金额,即求“支付金额关于苹果的价格的导数”。设苹果的价格为x,支付金额为L,则相当于求L对x的偏导。这个导数的值表示当苹果的价格稍微上涨时,支付金额会增加多少。
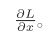
“支付金额关于苹果的价格的导数”的值可以通过计算图的反向传播求出来。
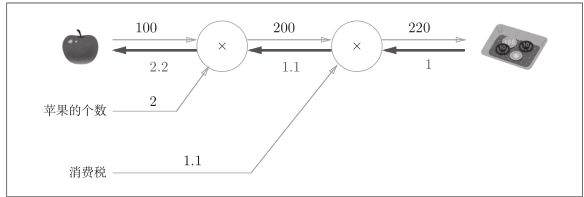
将导数的值写在箭头的下方。在这个例子中,反向传播从右向左传递导数的值(1 → 1.1 → 2.2)。从这个结果中可知,“支付金额关于苹果的价格的导数”的值是2.2。这意味着,如果苹果的价格上涨1日元,最终的支付金额会增加2.2日元。
4.2链式法则
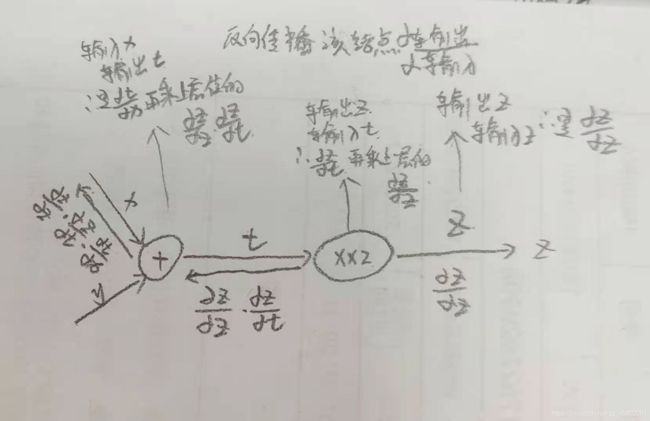
4.2.1计算图的反向传播


4.2.2链式法则
复合函数:多个函数构成

如果某个函数由复合函数表示,则该复合函数的导数可以用构成复合函数的各个函数的导数的乘积表示。
复合函数求偏导

4.2.3链式法则和计算图


4.3 反向传播
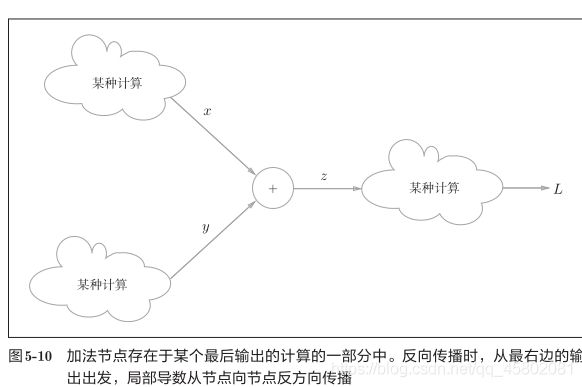
4.31 加法节点的反向传播
以z = x + y为对象,观察它的反向传播。
z = x + y的导数可由下式(解析性地)计算出来。

计算图表示
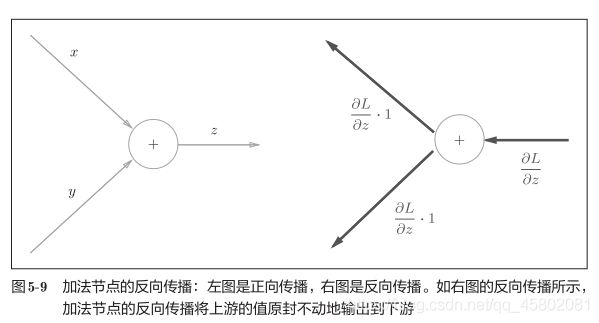
![]()

具体举例:
假设有“10 + 5=15”这一计算,反向传播时,从上游会传来值1.3。

因为加法节点的反向传播只是将输入信号输出到下一个节点,传入多少,向下一节就传入多少,所以如图所示,反向传播将1.3向下一个节点传递。
4.3.2 乘法节点的反向传播
例:z = xy。这个式子的导数

乘法的反向传播会将上游的值乘以正向传播时的输入信号的“翻转值”
后传递给下游。
翻转值表示一种翻转关系,如图所示,正向传播时信号是x的话,反向传播时则是y;正向传播时信号是y的话,反向传播时则是x。

如下图,1.3 × 5 =6.5、1.3 × 10 = 13计算。另外,加法的反向传播只是将上游的值传给下游,并不需要正向传播的输入信号。但是,乘法的反向传播需要正向传播时的输入信号值。因此,实现乘法节点的反向传播时,要保存正向传播的输入信号。
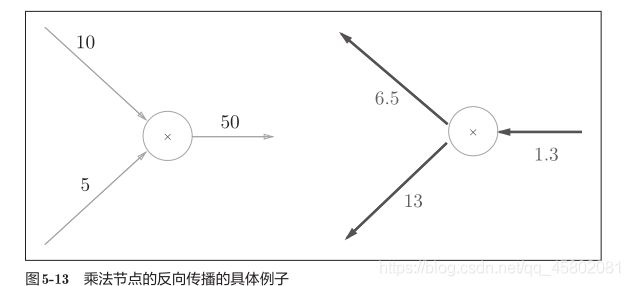
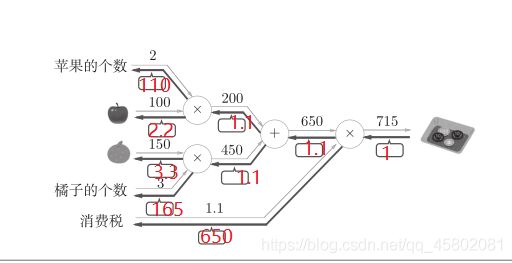
4.3.3 举例
购买苹果的例子。这里要解的问题是苹果的价格、苹果的个数、消费税这3个变量各自如何影响最终支付的金额。这个问题相当于求“支付金额关于苹果的价格的导数”“支付金额关于苹果的个数的导数”“支付金额关于消费税的导数”。用计算图的反向传播来解的话。


乘法节点的反向传播会将输入信号翻转后传给下游。
苹果的价格的导数是2.2,苹果的个数的导数是110,消费税的导数是200。
可以解释为,如果消费税和苹果的价格增加相同的值,则消费税将对最终价格产生200倍大小的影响,苹果的价格将产生2.2倍大小的影响。
不过,因为这个例子中消费税和苹果的价格的量纲不同,所以才形成了这样的结果(消费税的1是100%,苹果的价格的1是1日元)。
4.4 简单层的实现
计算图的乘法节点称为“乘法层” ( MulLayer ),加法节点称为“加法层”( AddLayer )。
4.4.1 乘法层的实现
层的实现中有两个共通的方法(接口) forward() 和 backward() 。 forward()对应正向传播, backward() 对应反向传播。
现在来实现乘法层。乘法层作为 MulLayer 类
class MulLayer:
def __init__(self):
self.x = None
self.y = None
def forward(self, x, y):
self.x = x
self.y = y
out = x * y
return out
def backward(self, dout):
dx = dout * self.y
dy = dout * self.x
return dx, dy
init() 中会初始化实例变量 x 和 y ,它们用于保存正向传播时的输入值。
forward() 接收 x 和 y 两个参数,将它们相乘后输出。
backward() 将从上游传来的导数( dout )乘以正向传播的翻转值,然后传给下游。
买苹果
from layer_naive import *
apple = 100
apple_num = 2
tax = 1.1
mul_apple_layer = MulLayer()
mul_tax_layer = MulLayer()
# forward
apple_price = mul_apple_layer.forward(apple, apple_num)
price = mul_tax_layer.forward(apple_price, tax)
# backward
dprice = 1
dapple_price, dtax = mul_tax_layer.backward(dprice)
dapple, dapple_num = mul_apple_layer.backward(dapple_price)
print("price:", int(price))
print("dApple:", dapple)
print("dApple_num:", int(dapple_num))
print("dTax:", dtax)
price: 220
dApple: 2.2
dApple_num: 110
dTax: 200
4.4.2 加法层的实现
class AddLayer:
def __init__(self):
pass
def forward(self, x, y):
out = x + y
return out
def backward(self, dout):
dx = dout * 1
dy = dout * 1
return dx, dy
加法层不需要特意进行初始化,所以 init() 中什么也不运行( pass语句表示“什么也不运行”)。加法层的 forward() 接收 x 和 y 两个参数,将它们相加后输出。 backward() 将上游传来的导数( dout )原封不动地传递给下游。
购买2个苹果和3个橘子的例子
# coding: utf-8
from layer_naive import *
apple = 100
apple_num = 2
orange = 150
orange_num = 3
tax = 1.1
# layer
mul_apple_layer = MulLayer()
mul_orange_layer = MulLayer()
add_apple_orange_layer = AddLayer()
mul_tax_layer = MulLayer()
# forward
apple_price = mul_apple_layer.forward(apple, apple_num) # (1)
orange_price = mul_orange_layer.forward(orange, orange_num) # (2)
all_price = add_apple_orange_layer.forward(apple_price, orange_price) # (3)
price = mul_tax_layer.forward(all_price, tax) # (4)
# backward
dprice = 1
dall_price, dtax = mul_tax_layer.backward(dprice) # (4)
dapple_price, dorange_price = add_apple_orange_layer.backward(dall_price) # (3)
dorange, dorange_num = mul_orange_layer.backward(dorange_price) # (2)
dapple, dapple_num = mul_apple_layer.backward(dapple_price) # (1)
print("price:", int(price))
print("dApple:", dapple)
print("dApple_num:", int(dapple_num))
print("dOrange:", dorange)
print("dOrange_num:", int(dorange_num))
print("dTax:", dtax)
price: 715
dApple: 2.2
dApple_num: 110
dOrange: 3.3000000000000003
dOrange_num: 165
dTax: 650
首先,生成必要的层,以合适的顺序调用正向传播的 forward() 方法。然后,用与正向传播相反的顺序调用反向传播的 backward() 方法,就可以求出想要的导数。
4.5 激活函数层的实现
4.5.1 ReLU层的实现
激活函数ReLU(Rectified Linear Unit 整流线性单元)由下式表示

求出y关于x的导数:

如果正向传播时的输入x大于0,则反向传播会将上游的值原封不动地传给下游。反过来,如果正向传播时的x小于等于0,则反向传播中传给下游的信号将停在此处。
如下图所示:

class Relu:
def __init__(self):
self.mask = None
def forward(self, x):
self.mask = (x <= 0)
out = x.copy()
out[self.mask] = 0
return out
def backward(self, dout):
dout[self.mask] = 0
dx = dout
return dx
Relu 类有实例变量 mask 。这个变量 mask 是由 True/False 构成的NumPy数组,它会把正向传播时的输入 x 的元素中小于等于0的地方保存为 True ,其他地方(大于0的元素)保存为 False 。如下例所示, mask 变量保存了由 True/False 构成的NumPy数组。

如图5-18所示,如果正向传播时的输入值小于等于0,则反向传播的值为0。
因此,反向传播中会使用正向传播时保存的 mask ,将从上游传来的 dout 的
mask 中的元素为 True 的地方设为0。
ReLU层的作用就像电路中的开关一样。正向传播时,有电流通过
的话,就将开关设为ON(开);没有电流通过的话,就将开关设为OFF(关)。反向传播时,开关为ON的话,电流会直接通过;开关为OFF的话,
则不会有电流通过。
4.5.2 Sigmoid层的实现
sigmoid函数由下式表示
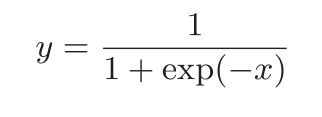
计算图表示

“exp”节点会进行y = exp(x)的计算,“/”节点会进行 的计算。
图5-19的计算图的反向传播
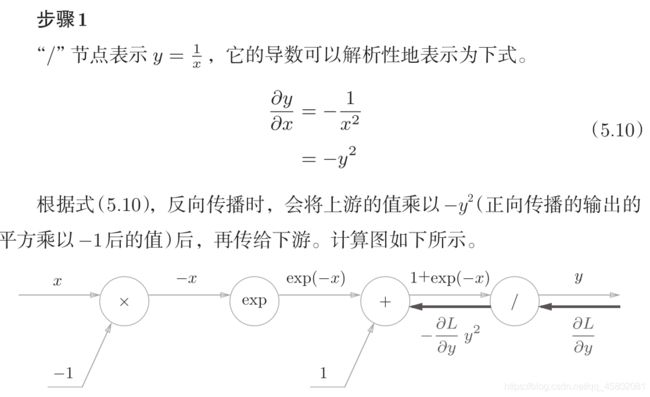


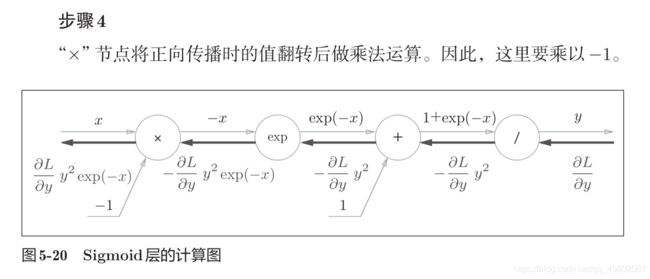

可以不用在意Sigmoid层中琐碎的细节,而只需要专注它的输入和输出,

只根据正向传播的输出就能计算出结果来。

class Sigmoid:
def __init__(self):
self.out = None
def forward(self, x):
out = sigmoid(x)
self.out = out
return out
def backward(self, dout):
dx = dout * (1.0 - self.out) * self.out
return dx
4.6 Affine/Softmax层的实现
4.6.1 Affine层(放射层)
这一层用来处理矩阵运算
矩阵的乘积运算的要点是使对应行列维度的元素个数一致。

神经网络的正向传播中进行的矩阵的乘积运算在几何学领域被称为“仿
射变换” 。因此,这里将进行仿射变换的处理实现为“Affine层”。
如下例:

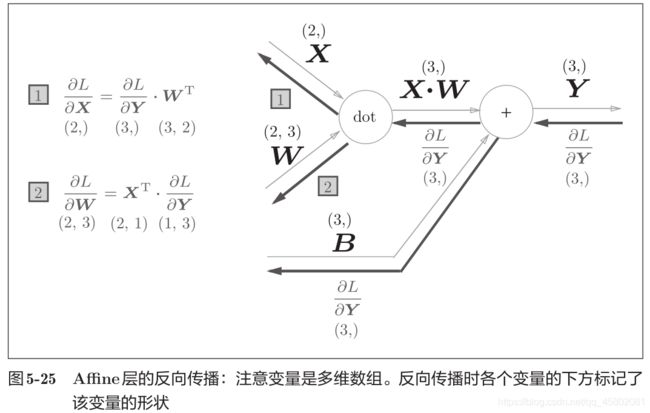
X、W、B 分别是形状为(2,)、(2, 3)、(3,)的多维数组。
神经元的加权和可以用 Y = np.dot(X, W) + B 计算出来。计算图如下:
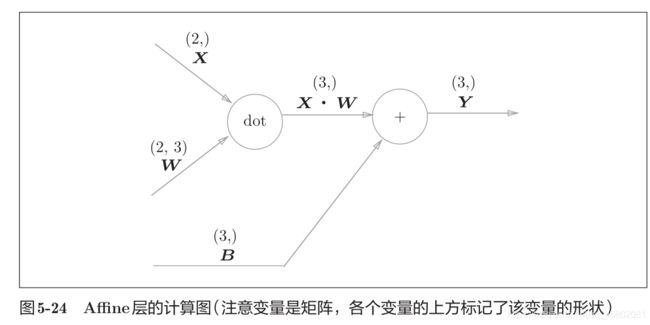
计算上图的反向传播图:
以矩阵为对象的反向传播,按矩阵的各个元素进行计算时,步骤和以标量为对象的计算图相同。
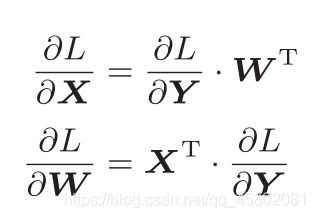


4.6.2 批版本Affine层
前面介绍的Affi ne层的输入X是以单个数据为对象的。现在我们考虑N个数据一起进行正向传播的情况,也就是批版本的Affine层。
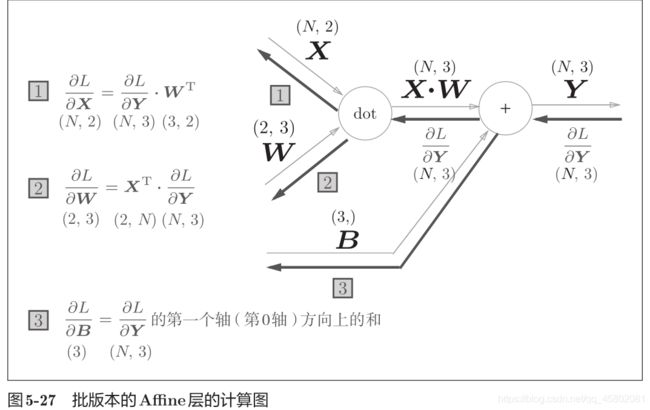

正向传播时,偏置会被加到每一个数据(第1个、第2个……)上。因此,反向传播时,各个数据的反向传播的值需要汇总为偏置的元素。

假定数据有2个(N = 2)。偏置的反向传播会对这2个数据的导数按元素进行求和。因此,这里使用了 np.sum() 对第0轴(以数据为单位的轴, axis=0 )方向上的元素进行求和。
class Affine:
def __init__(self, W, b):
self.W =W
self.b = b
self.x = None
self.original_x_shape = None
# 权重和偏置参数的导数
self.dW = None
self.db = None
def forward(self, x):
# 对应张量
self.original_x_shape = x.shape
x = x.reshape(x.shape[0], -1)
self.x = x
out = np.dot(self.x, self.W) + self.b
return out
def backward(self, dout):
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
dx = dx.reshape(*self.original_x_shape) # 还原输入数据的形状(对应张量)
return dx
4.6.3 Softmax-with-Loss 层
输出层的softmax函数,softmax函数会将输入值正规化之后再输出.
比如手写数字识别时,Softmax层的输出:

Softmax层将输入值正规化(将输出值的和调整为1)之后再输出。另外,因为手写数字识别要进行10类分类,所以向Softmax层的输入也有10个。
下面来实现Softmax层。考虑到这里也包含作为损失函数的交叉熵误差(cross entropy error),所以称为“Softmax-with-Loss层”

图5-30的计算图中,softmax函数记为Softmax层,交叉熵误差记为Cross Entropy Error层。这里假设要进行3类分类,从前面的层接收3个输入(得分)。如图5-30所示,Softmax层将输入(a1,a2,a3)正规化,输出(y1,y2,y3)。Cross Entropy Error层接收Softmax的输出(y1,y2,y3)和教师标签(t1,t2,t3),从这些数据中输出损失L

图5-30中要注意的是反向传播的结果。Softmax层的反向传播得到了(y1−t1, y2−t2,y3−t3)这样“漂亮”的结果。由于(y1,y2,y3)是Softmax层的输出,(t1,t2,t3)是监督数据,所以(y1−t1,y2−t2,y3−t3)是Softmax层的输出和教师标签的差分。
神经网络学习的目的就是通过调整权重参数,使神经网络的输出(Softmax
的输出)接近教师标签。因此,必须将神经网络的输出与教师标签的误差高
效地传递给前面的层。
刚刚的(y 1 − t 1 , y 2 − t 2 , y 3 − t 3 )正是Softmax层的输出与教师标签的差,直截了当地表示了当前神经网络的输出与教师标签的误差。
比如思考教师标签是(0, 1, 0),Softmax层的输出是(0.3, 0.2, 0.5)的情形。因为正确解标签处的概率是0.2(20%),这个时候的神经网络未能进行正确的识别。此时,Softmax层的反向传播传递的是(0.3, −0.8, 0.5)这样一个大的误差。因为这个大的误差会向前面的层传播,所以Softmax层前面的层会从这个大的误差中学习到“大”的内容。
class SoftmaxWithLoss:
def __init__(self):
self.loss = None
self.y = None # softmax的输出
self.t = None # 监督数据
def forward(self, x, t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
if self.t.size == self.y.size: # 监督数据是one-hot-vector的情况
dx = (self.y - self.t) / batch_size
else:
dx = self.y.copy()
dx[np.arange(batch_size), self.t] -= 1
dx = dx / batch_size
return dx
4.7误差反向传播法的实现
4.7.1 神经网络学习的全貌图
神经网络的学习步骤:
前提
神经网络中有合适的权重和偏置,调整权重和偏置以便拟合训练数据的过程称为学习。
神经网络的学习分为下面4个步骤。
步骤1(mini-batch)
从训练数据中随机选择一部分数据。
步骤2(计算梯度)
计算损失函数关于各个权重参数的梯度。
步骤3(更新参数)
将权重参数沿梯度方向进行微小的更新。
步骤4(重复)
重复步骤1、步骤2、步骤3。
4.7.2 对应误差反向传播法的神经网络的实现
把2层神经网络实现为 TwoLayerNet
首先,将这个类的实例变量和方法整理成表5-1和表5-2。


# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
from common.layers import *
from common.gradient import numerical_gradient
from collections import OrderedDict
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std = 0.01):
# 初始化权重
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
# 生成层
self.layers = OrderedDict()
self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1'])
self.layers['Relu1'] = Relu()
self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2'])
self.lastLayer = SoftmaxWithLoss()
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
# x:输入数据, t:监督数据
def loss(self, x, t):
y = self.predict(x)
return self.lastLayer.forward(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
if t.ndim != 1 : t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
# x:输入数据, t:监督数据
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
def gradient(self, x, t):
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.lastLayer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 设定
grads = {}
grads['W1'], grads['b1'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W2'], grads['b2'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
将神经网络的层保存为OrderedDict 这一点非常重要。 OrderedDict 是有序字典,“有序”是指它可以记住向字典里添加元素的顺序。因此,神经网络的正向传播只需按照添加元素的顺序调用各层的 forward() 方法就可以完成处理,而反向传播只需要按照相反的顺序调用各层即可。
因为Affine层和ReLU层的内部会正确处理正向传播和反向传播,所以这里要做的事情仅仅是以正确的顺序连接各层,再按顺序(或者逆序)调用各层。
4.7.3 误差反向传播法的梯度确认
两种求梯度的方法:一种是基于数值微分的方法,另一种是解析性地求解数学式的方法。后一种方法通过使用误差反向传播法,即使存在大量的参数,也可以高效地计算梯度。
5.7.4 使用误差反向传播法的学习
# coding: utf-8
import sys, os
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet
# 读入数据
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
iters_num = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 梯度
#grad = network.numerical_gradient(x_batch, t_batch)
grad = network.gradient(x_batch, t_batch)
# 更新
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print(train_acc, test_acc)