机器学习:银行贷款违约预测模型
一种数据科学方法,用于预测和了解申请人的个人资料,以最大程度地降低未来贷款违约的风险。

关于该项目
该数据集包含有关信贷申请人的信息。在全球范围内,银行使用这种数据集和信息数据类型来创建模型,以帮助决定接受/拒绝谁的贷款。
在进行所有探索性数据分析、清理和处理我们可能(将)发现的所有异常之后,一个好/坏申请人的模式将暴露在机器学习模型中学习。
机器学习问题和目标
我们正在处理一个有监督的二元分类问题。目标是训练最好的机器学习模型,以最大限度地提高深入了解过去客户资料的预测能力,最大限度地降低未来贷款违约的风险。
性能指标
鉴于我们正在处理高度不平衡的数据,用于模型评估的指标是 ROC AUC 。
项目结构
该项目分为三类:
-
EDA:探索性数据分析
-
数据整理:清理和特征选择
-
机器学习:预测建模
数据集
数据集为lendingclub数据集。
功能描述
-
id:贷款申请的唯一 ID。
-
等级:LC分配的贷款等级。
-
year_inc:借款人在注册时提供的自报年收入。
-
short_emp : 1 受雇 1 年或更短时间。
-
emp_length_num : 就业年限。可能的值介于 0 和 10 之间,其中 0 表示不到一年,而 10 表示十年或更长时间。
-
home_ownership:房屋所有权的类型。
-
dti(债务与收入比率):使用借款人每月债务支付总额与债务总额(不包括抵押贷款和申请的信用证贷款)除以借款人自我报告的月收入计算得出的比率。
-
目的:借款人为贷款请求提供的类别。
-
term:贷款的付款次数。值以月为单位,可以是 36 或 60。
-
last_delinq_none : 1 当借款人至少有一次拖欠事件时。
-
last_major_derog_none : 1 个借款人至少有 90 天的差评。
-
revol_util:循环线利用率,或借款人使用的信贷量相对于所有可用的循环信贷。
-
total_rec_late_fee:迄今为止收到的滞纳金。
-
od_ratio:透支比率。
-
bad_loan:未支付贷款时为 1。
导入依赖库
import pandas as pd
import numpy as np
import seaborn as sns
import pingouin as pg
import scipy
from scipy.stats import chi2
from scipy.stats import chi2_contingency
from scipy.stats import pearsonr, spearmanr
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn import tree
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
from sklearn.linear_model import Perceptron
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import precision_recall_curve, roc_auc_score, confusion_matrix, accuracy_score, recall_score, precision_score, f1_score,auc, roc_curve, plot_confusion_matrix
from category_encoders import BinaryEncoder
from IPython.display import Image
import pydotplus
import matplotlib.pyplot as plt
%matplotlib inline
color = sns.color_palette()
seed = 42
加载和显示数据集:
data = pd.read_csv('lending_club_loan_dataset.csv', low_memory=False
>> data.head()

如果大家对金融风控建模感兴趣,可了解《python金融风控评分卡模型和数据分析(加强版)》
EDA:解释性数据分析
数值属性的主要统计数据:
>> data.describe().round(3)
该数据集有 2000 个观测值和包括目标在内的 15 个变量,分为 11 个数字特征和 4 个类别特征。
存在缺失值的变量:“home_ownership”为 7.46%,“dti”为 0.77%,“last_major_derog_none”为 97.13%。
从均值和中位数的差异,以及变量“annual_inc”、“revol_util”和“total_rec_late_fee”的最大值的距离来看,似乎有一些异常值。
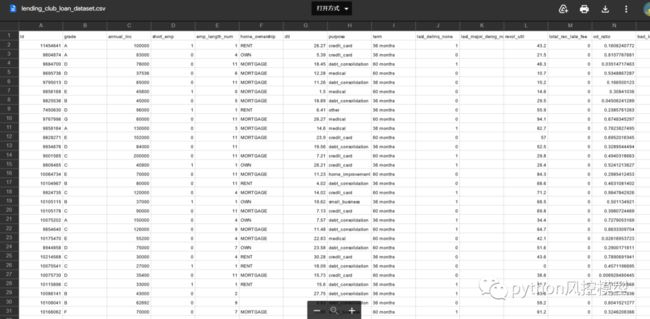
分类属性的主要统计数据:
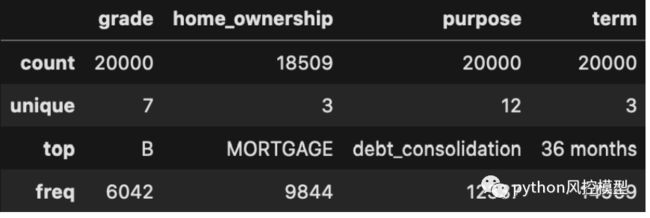
**不平衡的数据:**目标有 80% 的违约结果(值 1),而 20% 的贷款最终被支付/未违约(值 0)
EDA 功能
使用和滥用图形来描述数据集中的所有特征。首先为每个图表定义一些函数:箱线图、直方图、条形图和饼图、散点图、数据透视图以及统计描述。
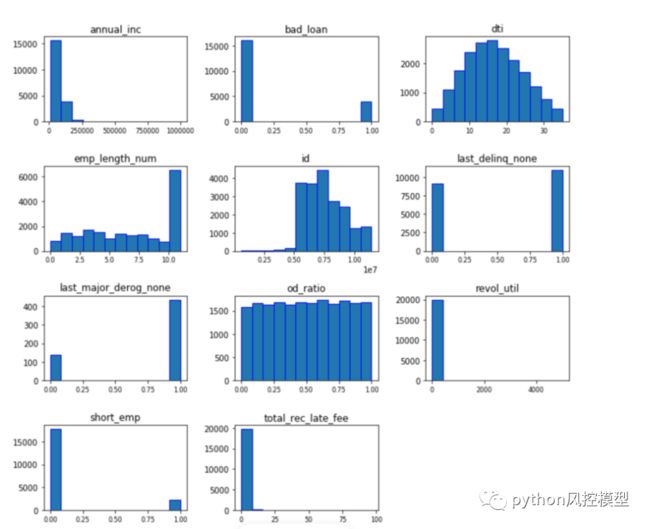
类别分布的可视化:

直方图告诉我们,收入越高,违约趋势越高。

散点图显示了“年收入”和“债务收入比”之间的弱负相关。
相关值为 -0.23,这意味着随着 yearn_inc 的减少,实例 1 的贷款(违约/未支付)增加。

就业年限。可能的值介于 0 和 10 之间,其中 0 表示不到一年,而 10 表示十年或更长时间。
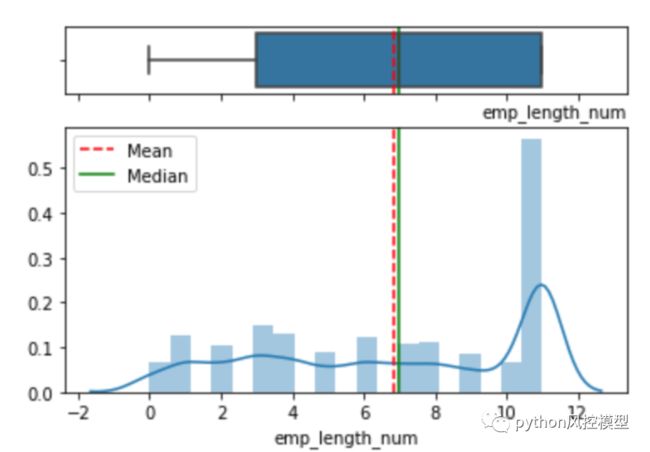
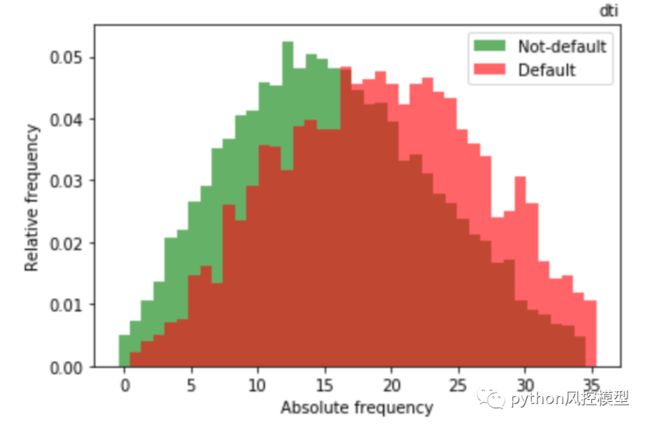
特征:dti(债务收入比)
使用借款人每月债务支付总额与债务总额(不包括抵押贷款和申请的信用证贷款)除以借款人自我报告的月收入计算得出的比率。

与良好贷款相比,不良贷款(违约)的分布平均具有更高的“dti”值(债务与收入比率)。
等级Grade:趋势是当等级等级降低时,违约贷款的可能性增加。

revol_util
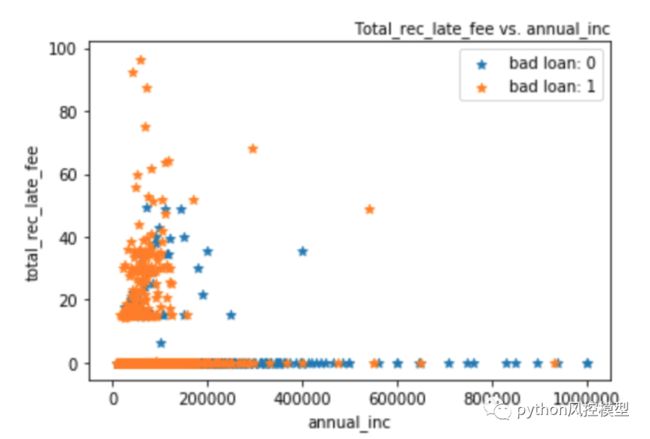
循环线利用率,或借款人使用的信贷量相对于所有可用的循环信贷。客户的年收入越低,借款人使用的信用额度相对于所有可用的循环信用额度越高。

年收入最低的客户是滞纳金较多的客户,尤其是最高和重的客户。
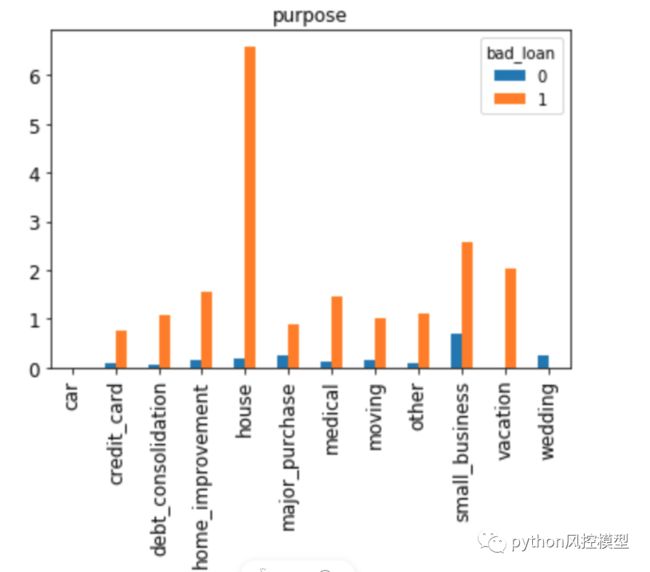
在房屋、小型企业或度假等贷款用途中,滞纳金的发生频率较高。另一方面,婚礼和汽车是滞纳金执行最低的信用目的。
od_ratio透支比率

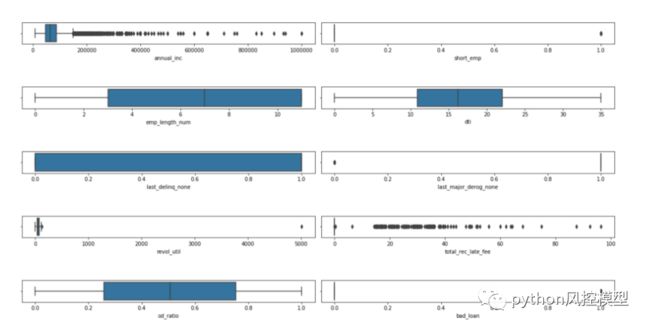
**箱线图:**可视化数值数据分散
模型的混淆矩阵

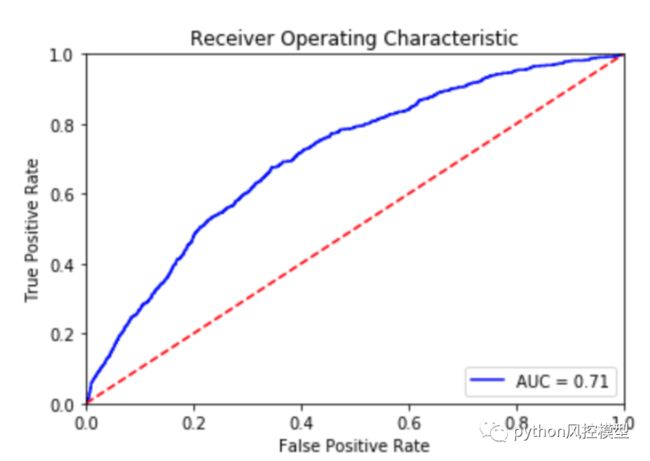
模型ROC曲线
多算法比较中,支持向量机svc的auc最高
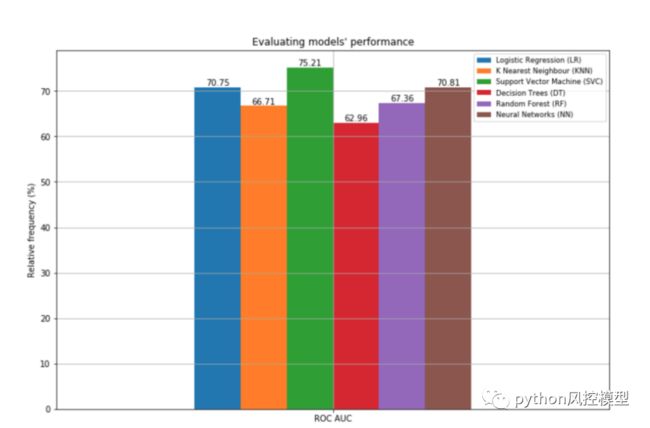
结论
最佳模型: 支持向量机 - 分类器 (SVC):75.21%。
经验法则非常简单:ROC AUC 指标的值越高越好。如果模型auc只有 0.5,表示模型功能和随机猜测差不多。如果模型表现完美,auc将达到 1.0。
作者推荐AUC参考阈值和模型性能划分

版权声明:本文为CSDN博主「python机器学习建模」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。