Pytorch实战总结篇之模型训练、评估与使用
1. 写在前面
这段时间一直在持续学习Pytorch, 也大约整理了20篇左右的笔记, 主要包括系统学习Pytorch的10篇, 这里面主要是从原理的层次看Pytorch的运行机制, 一方面是可以大致上对学习Pytorch有一个整体的框架, 另一方面是能理解很多知识的背后原理, 然后是Pytorch的入门与实战8篇, 这里面是使用Pytorch进行一些实战任务, 从图像到语音, 大致上可以知道Pytorch在各个领域是怎么发挥作用的, 但是经过前面的这些文章, 可能依然无法把Pytorch运用起来, 第一个系列是偏底层原理和知识框架, 而第二个系列作为一个桥梁纽带, 更多的是介绍图像和语音方面的知识, 然后用Pytorch进行了一些任务的完成,如果换了任务, 可能依然不知道如何使用Pytorch, 所以这个终结系列的几篇文章从纯使用的角度来总结Pytorch,毕竟Pytorch还是作为一种工具, 下面我们就来看看真正的使用方法。
通过前面的学习, 使用Pytorch实现神经网络建模一般包括数据准备、模型建立、模型训练、模型评估使用和保存, 所以接下来会整理四篇文章对这几方面进行使用总结。 今天是第三篇, 模型的训练方法和模型的评估使用保存,经过前两篇文章, 已经总结了数据准备和模型的建立常用方法, 今天主要是模型的训练、评估使用保存, 通过前三篇文章, 基本上就能把Pytorch给使用起来了。
这里会介绍三种常见的训练模型代码的编写风格, 脚本形式训练循环, 函数形式训练循环, 类形式训练循环,训练循环的代码风格因人而异, 我们在实际使用的时候, 可以进行参考这几种方式, 通过学习这个才发现, 原来Pytorch里面也能像keras里面那样的模型一样使用, .fit和.predict, 这个好方便。
下面用手写数字识别的数据集为例, 演示一下这三种训练风格, 这个依然参考的下面的链接,具体详情可以去看下面的链接部分, 这里总结一下重点方便日后查阅。
import torch
from torch import nn
from torchkeras import summary, Model
import torchvision
from torchvision import transforms
2. 数据准备部分
这个在第一篇文章中说过了, 图像的数据准备方法, 这里直接放代码了:
transform = transforms.Compose([transforms.ToTensor()])
ds_train = torchvision.datasets.MNIST(root="./data/minist/",train=True,download=True,transform=transform)
ds_valid = torchvision.datasets.MNIST(root="./data/minist/",train=False,download=True,transform=transform)
dl_train = torch.utils.data.DataLoader(ds_train, batch_size=128, shuffle=True, num_workers=4)
dl_valid = torch.utils.data.DataLoader(ds_valid, batch_size=128, shuffle=False, num_workers=4)
print(len(ds_train)) # 60000
print(len(ds_valid)) # 10000
3. 构建模型
这里构建模型, 我们就使用第二篇文章中最为简单的nn.Sequential方法。
net = nn.Sequential()
net.add_module("conv1",nn.Conv2d(in_channels=1,out_channels=32,kernel_size = 3))
net.add_module("pool1",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("conv2",nn.Conv2d(in_channels=32,out_channels=64,kernel_size = 5))
net.add_module("pool2",nn.MaxPool2d(kernel_size = 2,stride = 2))
net.add_module("dropout",nn.Dropout2d(p = 0.1))
net.add_module("adaptive_pool",nn.AdaptiveMaxPool2d((1,1)))
net.add_module("flatten",nn.Flatten())
net.add_module("linear1",nn.Linear(64,32))
net.add_module("relu",nn.ReLU())
net.add_module("linear2",nn.Linear(32,10))
summary(net, input_shape=(1, 32, 32))
4. 模型的训练设置
这里定义模型的评估指标, 损失函数, 优化方法等。
import datetime
import numpy as np
import pandas as pd
from sklearn.metrics import accuracy_score
def accuracy(y_pred,y_true):
y_pred_cls = torch.argmax(nn.Softmax(dim=1)(y_pred),dim=1).data
return accuracy_score(y_true,y_pred_cls)
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=net.parameters(),lr = 0.01)
metric_func = accuracy
metric_name = "accuracy"
下面是三种风格的训练代码。
5. 三种风格的训练代码
5.1 脚本式训练风格
这个是最为常见的一种。
epochs = 3
log_step_freq = 100
dfhistory = pd.DataFrame(columns = ["epoch","loss",metric_name,"val_loss","val_"+metric_name])
print("Start Training...")
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("=========="*8 + "%s"%nowtime)
for epoch in range(1,epochs+1):
# 1,训练循环-------------------------------------------------
net.train()
loss_sum = 0.0
metric_sum = 0.0
step = 1
for step, (features,labels) in enumerate(dl_train, 1):
# 梯度清零
optimizer.zero_grad()
# 正向传播求损失
predictions = net(features)
loss = loss_func(predictions,labels)
metric = metric_func(predictions,labels)
# 反向传播求梯度
loss.backward()
optimizer.step()
# 打印batch级别日志
loss_sum += loss.item()
metric_sum += metric.item()
if step%log_step_freq == 0:
print(("[step = %d] loss: %.3f, "+metric_name+": %.3f") %
(step, loss_sum/step, metric_sum/step))
# 2,验证循环-------------------------------------------------
net.eval()
val_loss_sum = 0.0
val_metric_sum = 0.0
val_step = 1
for val_step, (features,labels) in enumerate(dl_valid, 1):
with torch.no_grad():
predictions = net(features)
val_loss = loss_func(predictions,labels)
val_metric = metric_func(predictions,labels)
val_loss_sum += val_loss.item()
val_metric_sum += val_metric.item()
# 3,记录日志-------------------------------------------------
info = (epoch, loss_sum/step, metric_sum/step,
val_loss_sum/val_step, val_metric_sum/val_step)
dfhistory.loc[epoch-1] = info
# 打印epoch级别日志
print(("\nEPOCH = %d, loss = %.3f,"+ metric_name + \
" = %.3f, val_loss = %.3f, "+"val_"+ metric_name+" = %.3f")
%info)
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("\n"+"=========="*8 + "%s"%nowtime)
print('Finished Training...')
5.2 函数风格
该风格在脚本形式上进行了简单的函数封装。 这里就是把每一步的训练写成了函数。
def train_step(model,features,labels):
# 训练模式,dropout层发生作用
model.train()
# 梯度清零
model.optimizer.zero_grad()
# 正向传播求损失
predictions = model(features)
loss = model.loss_func(predictions,labels)
metric = model.metric_func(predictions,labels)
# 反向传播求梯度
loss.backward()
model.optimizer.step()
return loss.item(),metric.item()
@torch.no_grad()
def valid_step(model,features,labels):
# 预测模式,dropout层不发生作用
model.eval()
predictions = model(features)
loss = model.loss_func(predictions,labels)
metric = model.metric_func(predictions,labels)
return loss.item(), metric.item()
# 测试train_step效果
features,labels = next(iter(dl_train))
train_step(model,features,labels)
这时候, 训练的时候, 就可以简化:
def train_model(model,epochs,dl_train,dl_valid,log_step_freq):
metric_name = model.metric_name
dfhistory = pd.DataFrame(columns = ["epoch","loss",metric_name,"val_loss","val_"+metric_name])
print("Start Training...")
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("=========="*8 + "%s"%nowtime)
for epoch in range(1,epochs+1):
# 1,训练循环-------------------------------------------------
loss_sum = 0.0
metric_sum = 0.0
step = 1
for step, (features,labels) in enumerate(dl_train, 1):
loss,metric = train_step(model,features,labels)
# 打印batch级别日志
loss_sum += loss
metric_sum += metric
if step%log_step_freq == 0:
print(("[step = %d] loss: %.3f, "+metric_name+": %.3f") %
(step, loss_sum/step, metric_sum/step))
# 2,验证循环-------------------------------------------------
val_loss_sum = 0.0
val_metric_sum = 0.0
val_step = 1
for val_step, (features,labels) in enumerate(dl_valid, 1):
val_loss,val_metric = valid_step(model,features,labels)
val_loss_sum += val_loss
val_metric_sum += val_metric
# 3,记录日志-------------------------------------------------
info = (epoch, loss_sum/step, metric_sum/step,
val_loss_sum/val_step, val_metric_sum/val_step)
dfhistory.loc[epoch-1] = info
# 打印epoch级别日志
print(("\nEPOCH = %d, loss = %.3f,"+ metric_name + \
" = %.3f, val_loss = %.3f, "+"val_"+ metric_name+" = %.3f")
%info)
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("\n"+"=========="*8 + "%s"%nowtime)
print('Finished Training...')
return dfhistory
epochs = 3
dfhistory = train_model(model,epochs,dl_train,dl_valid,log_step_freq = 100)
5.3 类风格
此处使用torchkeras中定义的模型接口构建模型,并调用compile方法和fit方法训练模型。使用该形式训练模型非常简洁明了。推荐使用该形式。 这个就和keras里面的模型训练方式差不多了。
这里需要重新定义一个模型, 我们看看使用。
class CnnModel(nn.Module):
def __init__(self):
super().__init__()
self.layers = nn.ModuleList([
nn.Conv2d(in_channels=1,out_channels=32,kernel_size = 3),
nn.MaxPool2d(kernel_size = 2,stride = 2),
nn.Conv2d(in_channels=32,out_channels=64,kernel_size = 5),
nn.MaxPool2d(kernel_size = 2,stride = 2),
nn.Dropout2d(p = 0.1),
nn.AdaptiveMaxPool2d((1,1)),
nn.Flatten(),
nn.Linear(64,32),
nn.ReLU(),
nn.Linear(32,10)]
)
def forward(self,x):
for layer in self.layers:
x = layer(x)
return x
model = torchkeras.Model(CnnModel()) # 封装成了keras里面模型的格式
print(model)
model.summary(input_shape=(1, 32, 32))
下面进行编译和训练:
# keras风格
model.compile(loss_func = nn.CrossEntropyLoss(),
optimizer= torch.optim.Adam(model.parameters(),lr = 0.02),
metrics_dict={"accuracy":accuracy})
# 训练只需要一句话
dfhistory = model.fit(3,dl_train = dl_train, dl_val=dl_valid, log_step_freq=100)
6. 模型的评估
模型的评估一般是评估在训练集和验证集上的效果, 在模型训练过程中, 我们都是保留着一个dfhistory的, 这个是一个DataFrame的结构, 里面是训练过程中训练集和验证集上模型的正确率和损失的变化, 我们可以通过可视化这个来看一下模型的训练情况。
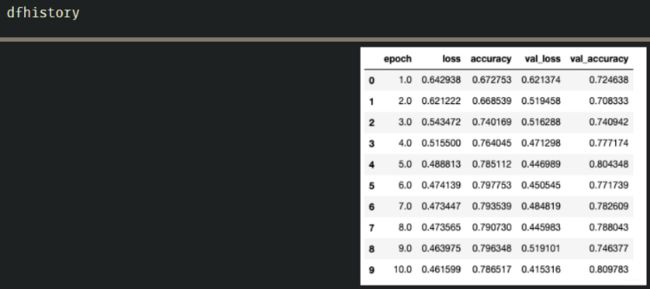
这个通过可视化:
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
import matplotlib.pyplot as plt
def plot_metric(dfhistory, metric):
train_metrics = dfhistory[metric]
val_metrics = dfhistory['val_'+metric]
epochs = range(1, len(train_metrics) + 1)
plt.plot(epochs, train_metrics, 'bo--')
plt.plot(epochs, val_metrics, 'ro-')
plt.title('Training and validation '+ metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_"+metric, 'val_'+metric])
plt.show()
# 观察损失和准确率的变化
plot_metric(dfhistory,"loss")
plot_metric(dfhistory,"accuracy")
7. 模型的使用
这个就得看具体任务, 具体模型了
# 预测概率
y_pred_probs = net(torch.tensor(x_test[0:10]).float()).data
# 预测类别
y_pred = torch.where(y_pred_probs>0.5,
torch.ones_like(y_pred_probs),torch.zeros_like(y_pred_probs))
def predict(model,dl):
model.eval()
with torch.no_grad():
result = torch.cat([model.forward(t[0]) for t in dl])
return(result.data)
#预测概率
y_pred_probs = predict(model,dl_valid)
#预测类别
y_pred = torch.where(y_pred_probs>0.5,
torch.ones_like(y_pred_probs),torch.zeros_like(y_pred_probs))
8. 模型的保存
Pytorch 有两种保存模型的方式,都是通过调用pickle序列化方法实现的。
- 第一种方法只保存模型参数。
- 第二种方法保存完整模型。
推荐使用第一种,第二种方法可能在切换设备和目录的时候出现各种问题。
-
保存模型参数
print(net.state_dict().keys()) # 保存模型参数 torch.save(net.state_dict(), "./data/net_parameter.pkl") # 使用 net_clone = create_net() net_clone.load_state_dict(torch.load("./data/net_parameter.pkl")) -
保存完整模型
torch.save(net, './data/net_model.pkl') net_loaded = torch.load('./data/net_model.pkl')
参考:
- https://github.com/lyhue1991/eat_pytorch_in_20_days