注意:
VAAPI 是inter gpu 提供的硬编解码接口
VDPAU 是 video decode present api for unix
nvdec / ncvid 都是nivida产出的硬解接口,区别在于解码方式,和数据传输方式不同
nvenc nivida 硬编接口编译 & 运行
linux:
gcc -g video_decode_gpu.c `pkg-config --libs libavformat libavcodec libswresample libswscale libavutil` -o video_decode_gpu
run cmd:
./video_decode_gpu data/left.mp4 ./bmpgpu解码原理
问题1? gpu 解码 是把内存中AVPacket 拷贝到gp显存中进行处理的吗?
看来是的,代码中通过 av_read_frame(input_ctx, &packet) 读取数据包,其数据操作流向应该是 video file -> memory
问题2? gpu 解码 的 数据流向?
videofile-> avpacket ->decoding frame's in gpu-> transfer rame in gpu into host memory
问题3? gpu 解码数据 cuvid 解码器,也是api,对应的数据操作流向?
videofile-> avpacket ->decoding frame's in gpu-> transfer rame in gpu into host memoryVDPAU 简介
Developed by NVIDIA for Unix/Linux systems. To enable this you typically need the libvdpau development package in your distribution, and a compatible graphics card.
Note that VDPAU cannot be used to decode frames in memory, the compressed frames are sent by libavcodec to the GPU device supported by VDPAU and then the decoded image can be accessed using the VDPAU API. This is not done automatically by FFmpeg, but must be done at the application level (check for example the ffmpeg_vdpau.c file used by ffmpeg.c). Also, note that with this API it is not possible to move the decoded frame back to RAM, for example in case you need to encode again the decoded frame (e.g. when doing transcoding on a server).
Several decoders are currently supported through VDPAU in libavcodec, in particular H.264, MPEG-1/2/4, and VC-1.
翻译:
由NVIDIA开发的Unix / Linux系统。 要启用此功能,您通常需要分发中的libvdpau开发包和兼容的图形卡。
注意,VDPAU不能用于解码内存中的帧,压缩帧由libavcodec发送到VDPAU支持的GPU设备,然后可以使用VDPAU API访问解码图像。
这不是由FFmpeg自动完成的,但必须在应用程序级别完成(例如检查ffmpeg.c使用的ffmpeg_vdpau.c文件)。
此外,请注意,使用此API时,无法将解码后的帧移回RAM,例如,如果您需要再次对解码帧进行编码(例如,在服务器上进行转码时)。
目前通过libavcodec中的VDPAU支持几个解码器,特别是H.264,MPEG-1/2/4和VC-1。VDPAU 学习:
VdpDecoder -> 解码 压缩包数据
VdpVideoSurface -> 解码完数据放置的空间
VdpVideoMixer -> 对解码完的数据做后置处理
VdpOutputSurface -> 处理完数据放置的位置cuvid 与 VDPAU 是平级的东西,不能拿来直接使用,使用成本太大
cuvid 学习
cuvid nvidia 提供的gpu 视频硬解码库,底层依赖cuda并行计算框架
将cpu 解码转化到gpu 解码上,减少cpu压力,提升解码速度CUVID 硬解码
note:
cuvid nvdec 两者都是解码api,不同点在于解码方式 & 数据传输
nvenc vaapi cdpau 都是硬件编解码apiCUVID解码rtsp视频流
note
OpenCV中VideoReader_GPU可以方便地利用GPU读取视频文件,加速解码过程,但OpenCV中VideoReader_GPU无法读取rtsp视频流数据。
这是因为CUVID中CuvideoSource不支持rtsp视频流数据,不能由rtsp地址创建VideoSource。
但是videoSource 支持 视频文件查看nvidia 驱动 & nvcc 版本
cat /proc/driver/nvidia/version
nvcc编译器的版本
nvcc -VNote: For Video Codec SDK 7.0 and later, NVCUVID has been renamed to NVDECODE API.
编译 & 运行
编译
linux:
gcc -g hw_decode_cuvid.c `pkg-config --libs libavformat libavcodec libswresample libswscale libavutil` -o hw_decode_cuvid运行
./hw_decode_cuvid cuda input_data/left.mp4 ./output_data/raw.out运行结果
raw.out 文件生成

cpu 软解码 cpu 占用率

gpu cuvid 硬解码 cpu 占用率

gpu 硬解码 gpu 使用情况
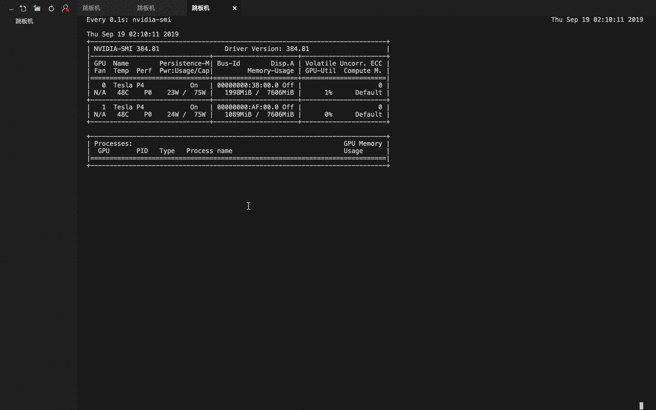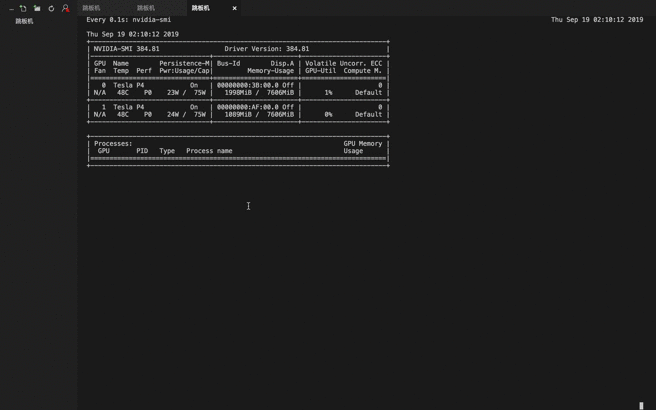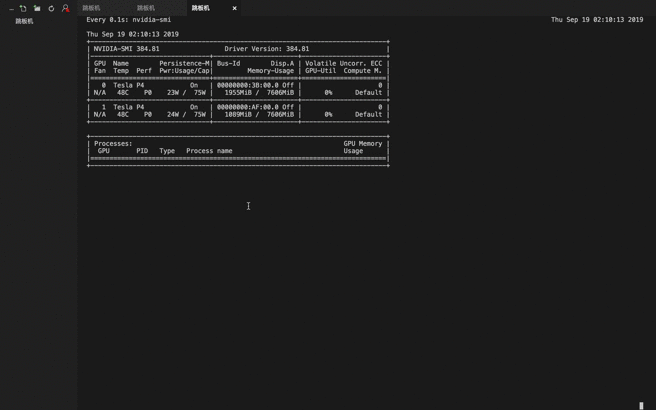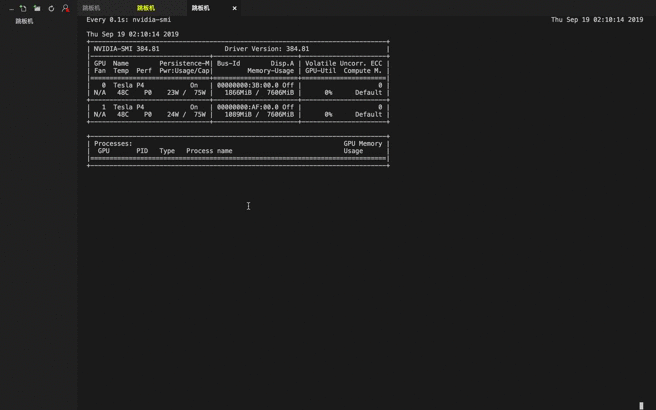
问题:
1、为什么 gpu 硬解码显卡使用率那么低?需要排查下问题。
2、将 gpu 中frame 直接做 AV_PIX_FMT_CUDA-> AV_PIX_FMT_BGR24 转化 不能直接用 sws_getContext ,如何才能实现
3、ffmpeg 将 gpu解码 数据的像素格式进行 yuv-rgb 格式转换 ,是否直接支持,是否需要自己写函数
4、将 gpu 中数据直接存储在磁盘上? 如果不可以的话 ,则进行 device data ->host memory data ->file
5、数据拷贝方式 transfer_data_from 源码gpu decoded frame pix format AV_PIX_FMT_CUDA 直接在显存中 转化为 AV_PIX_FMT_BGR24
可行路径,试了三种:
两种cpu层面转换像素格式 的方法(1种失败,1种成功);
直接使用ffmpeg api 在gpu层面进行像素格式转换(失败)CPU 主导像素转换
1. 使用 sws_scale 实现 AV_PIX_FMT_CUDA-> AV_PIX_FMT_BGR24 的直接转换(cpu 层面)
这是我第一次使用的方式,模仿 cpu 上软解码(获取视频帧,并存储为bmp格式,经验原则,这种方式最容易想到)运行结果:
失败,bad src img pointers
运行结果如下图所示:

问题原因:
如代码 hw_decode_cuvid_origin.c 中所示, 直接通过transfer_data 将gpu 中解码后的frame download到
系统内存,则系统内存中的frames piex->format 仍为 AV_PIX_FMT_CUDA ,而 AV_PIX_FMT_CUDA 是gpu 显存中存储的解码后的帧像素格式
所以通过 sws_scale 是不能直接change的
GPU 主导像素转换
gpu 不支持 sws_scale + AV_PIX_FMT_CUDA-> AV_PIX_FMT_BGR24 的直接像素转换方式,那么 能否直接在gpu中直接转化 AV_PIX_FMT_CUDA 为 AV_PIX_FMT_BGR24呢?
如果可以直接实现,性能会有很大提升,因为减少了device->host 的数据传输,且gpu多核心并行处理,肯定比cpu处理性能要强悍。
av_hwframe_transfer_data() 执行操作前 设置 内存中目标frame的像素格式为 AV_PIX_FMT_BGR24,gpu 黑盒操作实现在gpu上直接将像素格式转化为目标bgr24格式
运行结果:
失败,像素没对齐,只有亮度
运行结果如下图所示:
![预先设置内存中frame目标像素格式为 AV_PIX_FMT_BGR24]
问题原因:
如下图所示:

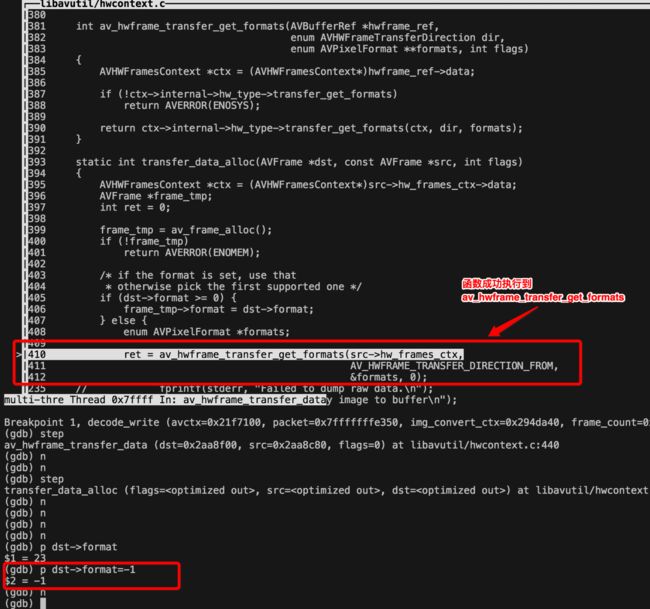
红框表示的意思为:src->frame->format 转换为 dst->frame->format 是受限制的,主要是受av_hwframe_transfer_get_formats() 函数返回的formats 列表限制所以gdb了下源码,发现src->frame->format 转换为 dst->frame->format 的受限范围很小,然后找出了 av_hwframe_transfer_get_formats 支持的formats,
调试过程如下所示:gdb -tui hw_decode_cuvid (-tui 支持查看源码)
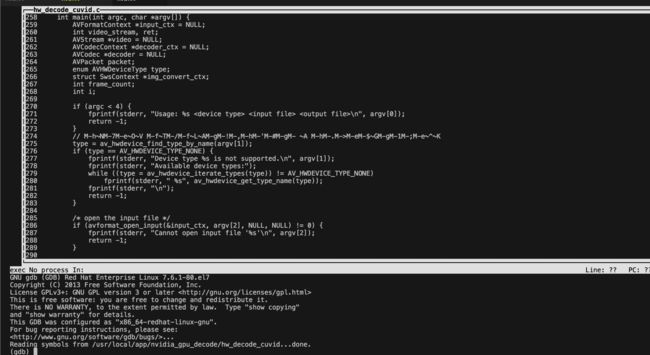
在调用 av_hwframe_transfer_data() 函数处打上断点,且设置程序运行所需参数
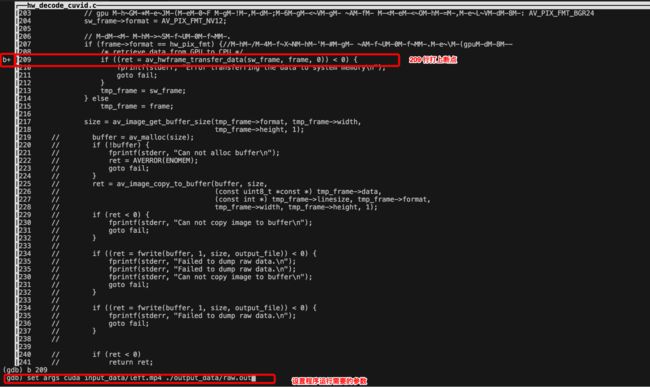
run 程序,step 进入函数调用栈

n 单步运行,函数调用至 transfer_data_alloc()
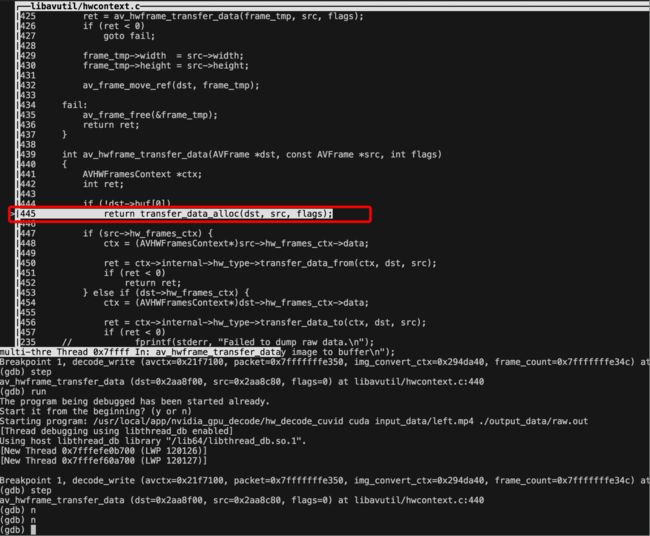
发现 av_hwframe_transfer_get_formats()函数
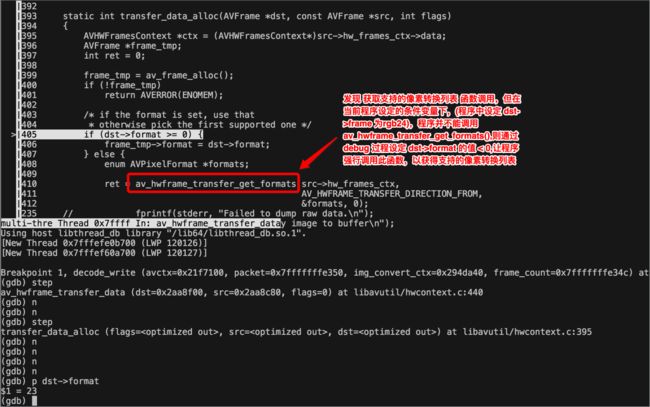
更改 dst->format 的值为<0的值,并打印支持的像素转换列表
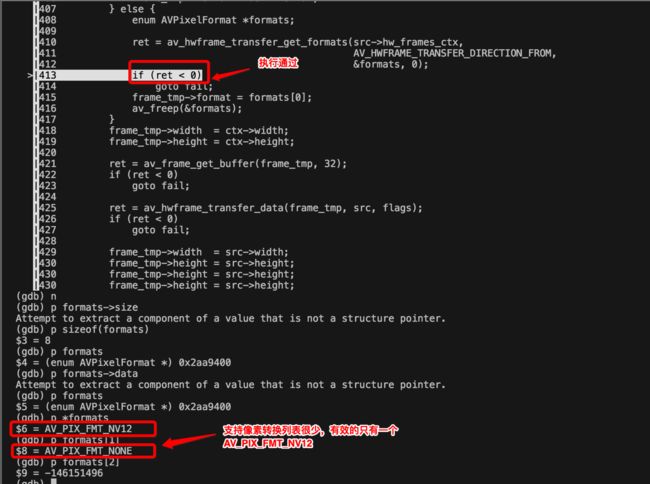
可以看到只支持 gpu 硬件像素编码格式->AV_PIX_FMT_NV12 的转换
CPU 主导像素转换
经过前两次的试验,可以明确当前最新版本的ffmpeg还不支持硬解完成之后直接将像素格式转换为目标rgb24数据,还是回归到 cpu + sws_scale 上,
经过第二步,可以知道AV_PIX_FMT_CUDA->AV_PIX_FMT_NV12这条路行的通,AV_PIX_FMT_NV12 其实是 YUV 格式的数据,yuv 数据到 rgb 的像素转换
是完全支持的,所以就自然编写了 AV_PIX_FMT_CUDA->AV_PIX_FMT_NV12->AV_PIX_FMT_BGR24 的代码,经测试没问题。
当然,不可否认:
实现 AV_PIX_FMT_CUDA-> AV_PIX_FMT_NV12->AV_PIX_FMT_BGR24 格式转换 (cpu 实现 pix format 转换,这种cpu层面上的像素格式转换方式比较弱)
运行结果:
成功,如下图所示: