A Deep One-class Model for Network Anomaly Detection
A Deep One-class Model for Network Anomaly Detection
摘要:
对于传统的网络异常检测,检测性能与所选择的特征和用于训练的数据集有关。传统的检测方法是人工挑选特征,同时收集用于训练的数据集多数是不平衡的,导致模型对于大多数的数据会做出错误判断。本文提出一种基于层叠式自动编码器的检测模型。首先用这个模型从原始采集到的数据中选择主要特征,随后利用一个单分类算法SVDD去训练一个分类器来判断网络流量是否为异常。
简介:
主要有两种网络保护机制:【1】防火墙。在受保护网路边缘安装防火墙可以阻止潜在外来入侵,但是阻止不了内部攻击。如果允许进入网络的数据包含恶意代码,无论是否安装防火墙,整个网络都会中毒。【2】入侵检测系统。他是防火墙的一个有效补充,是一种主动监测主机或网络行为,并在检测到可疑网络行为时向管理员发出警报的主动技术。其检测策略主要分为两种:(1)误用检测。首先收集异常模式,并对传入传出的数据包进行检测,检测精度高,但是无法检测新的攻击(即模式中不存在的异常),故很少单独使用(2)异常检测。网络异常检测主要侧重点是受保护网络的正常行为(不关注异常),与建立的正常模型偏离的行为被视为异常。该方法不能掩盖网络攻击产生的网络异常和流量异常。理论上,如果建立好的模型,任何异常都能被检测到,但是由于该方法的具有高误报率,不适合应用于真实的网络环境。
本文提出的新方法主要贡献有:
-
与传统方法(视为多分类)不一样,我们视为单分类问题,并且只从受保护网络收集正常合法的数据来定义网络边界。故不需要对数据进行标注和处理数据不平衡的问题。
-
针对传统人工提取数据特征问题,本文提出一种能够过滤网络无关紧要特征并提取保留重要特征的层叠式自动编码器方法。
下文提出一种基于深度自动编码器和单类SVM的混合检测模型。
相关工作:
完成网络异常检测的两种主要策略有:
监督式异常检测:数据集的实例被标记为正常或异常,预测模型是在这个标记的数据集上建立的,这种方式的优势是检测攻击的准确率高,但是存在两个问题(1)数据需要被标记(常是人工),这需要耗费大量的人力和时间,且依赖人的经验,获取准确的数据标记极具挑战。(2)一般情况下正常网络行为比异常行为多,机器学习模型训练的评判标准常会偏向于多数类(正常行为),少数类(异常行为)倾向于误导模型导致误判。
无监督异常检测:不需要标记的训练数据集,从一组相似数据中学习规则。通常采用聚类算法,如KNN、K-means等,存在假设:在无监督测试数据集中,正常的网络行为远高于异常(否则会导致高的错误率)。
以上两种方法丢存在缺陷。因为收集到的数据常有一些干扰,在训练检测模型之前,选择一个高分辨特征的子集很重要。
提出的模型:
提出的模型利用层叠式自动编码器的非线性映射能力提取主要特征,并将其作为OCSVM的输入来检测网络异常。
提出的模型主要架构如下图所示,其主要包括三层:(1)数据预处理层:将原始数据转为更容易处理的格式:(2)层叠式自动编码器:提取来自第一层数据的特征(训练时,不断更新编解码器(主要是encoder)的参数,让编码器对其输入在经过编-解码后能产生较小的误差。训练好后的编码器在使用阶段会得到输入数据的精髓<关键特征值>);(3)OCSVM:检测数据是否为异常。
分类任务的机制相对简单:【1】从受保护网络收集的任何网络包都将由数据预处理层进行处理,并将原始数据转换为指定的格式。【2】然后将预处理后的数据通过层叠式自动编码器层映射到一个简洁、信息丰富的特征向量中。【3】OCSVM层将验证给定网络是否正常。
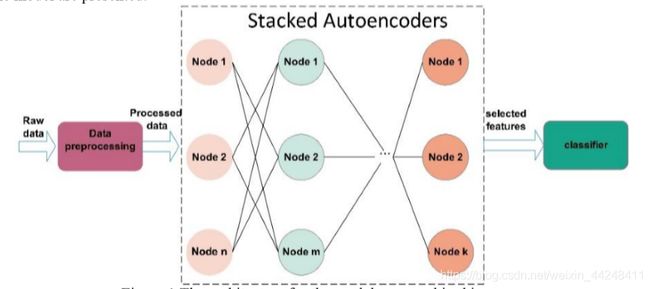
-
预处理层:因为收集到的数据容易受到噪声干扰,故这一步主要是提高原始数据质量。原始数据主要有两种:【1】数字【2】类别或字符串;因此在这一层主要有两种处理方式:(1)对于数字类型,使用最大-最小规格化(即使数据落在一个区间内)<好处:【1】提升模型的收敛速度【2】提升模型的精度【3】防止模型梯度爆炸>来拟定预定义边界中的数据。(2)对于类别数据,采用一个one-hot encoder 将数据的值映射为数值数据,如三种网络包协议:TCP、UDP、ICMP分别映射为数组<1,0,0>、<0,1,0>、<0,0,1>。
-
层叠式自动编码器:深度学习的力量在于它能够逐层学习原始数据的不同表示。每一层都可以在前一层的基础上**提取更抽象、更复杂的特征。**堆叠式自动编码器的机制是相同的。
-
层叠式自动编码由多层自动编码器组成,每个自动编码器包含输入层,隐藏层,输出层三层。自动编码器里的编码器将原始数据转为低维表示,解码器将编码器的输出重构,给定数据集X={X1,X3,X3…Xn,},Xi是一个d维特征向量,编码器将d维向量Xi映射为m维向量(m
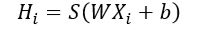
W是×权重矩阵,m是隐藏层的节点数(即映射为多少维),是偏移向量(m维),函数S是编码函数(生成的m维特征向量Hi)。解码过程如下:
-
![]()
W’是一个×的权重矩阵,Hi是m维特征向量,b’是偏移向量(d维),函数D是解码函数。
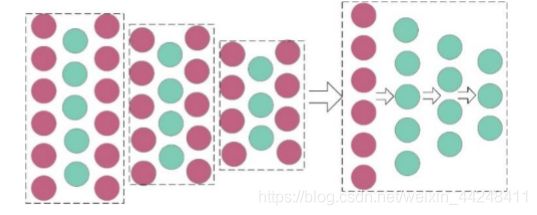
叠式自动编码器训练过程示意图(3层)
训练自动编码器的目标是找到最优参数(W、W’、b、b’)来最小化输入X和输出X’之间的误差,其训练的损失函数如下:
![]()
优化过程如下:
![]()
层叠式自动编码器在隐藏层包含多个自动编码器,并且层叠式自动编码器的训练应逐步进行。在我们的模型中,贪婪的分层训练被用来获得每一层的良好参数。其整个训练过程可分为三个阶段:
1. 使用原始数据训练第一个自动编码器,获得训练后的向量。
2. 将第一步的向量作为输入数据训练下一层。重复此步骤,直到所有的自动编码器都经过训练。
3. 利用反向传播算法最小化损失函数,更新权值矩阵和偏差向量来实现微调。
-
单分类层:网络异常检测难以获得攻击实例(即异常样本),训练分类器使用的数据集对于不同的类有不同的实例,这将导致所训练的模型做出的预测更偏向于更常见测情况。从不平衡的数据集中(正负样本差距较大)学习预测模型是单分类问题。
针对单分类主要有两种方法:【1】基于训练数据参数生成模型的密度评估。如高斯模型、高斯混合模型、密度评估。此方法假设数据服从正态分布或者高斯混合分布,利用极大似然函数对模型求取参数。优点:简单易于实现,缺点:对训练数据的噪声比较敏感。【2】边界方法。如定义超平面的OCSVM和超球体的SVDD,引入核函数的SVDD模型比OCSVM更加灵活。因此在第三层分类层采用SVDD模型进行验证。
对于给定的数据集X{x1、x2…xl},xi∈Rn,SVDD的目的是找到能够包含数据集X的超球体边间。
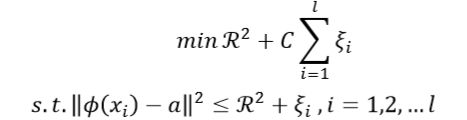
是球体中心,R是球体半径, φ 是一个能将低维输入数据xi映射到高维空间的函数(即核函数), i是松弛变量(允许超球体包含数据时存在一定的偏差,不会被个别极端的数据点给破坏**),C>0(用户自定义参数,在简单性和错误数间增加权衡,调节松弛变量的大小)。若设置错误率阈值,C的计算公式如下(l是数据集包含的数据量):
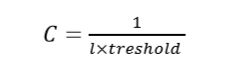
拉格朗日对偶问题:
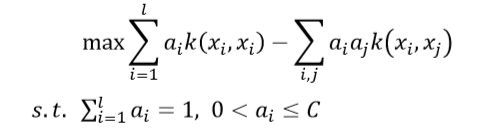
i是拉格朗乘数,K是核函数(将数据从低维空间映射到高维空间,提高数据的可分性)。=0表示样本在超球体内,=表示样本在超球体之外,0<<表示样本在超球面上。样本x到超球面中心的距离如下:
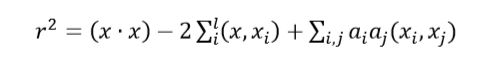
使用如下判别函数来判断x是否在超球体内
![]()
其中I()是索引函数。如果()=1,则表示测试点x位于超球面内或超球面上。如果()=0,则表示测试点x在超球面之外。(if语句而已)
实验
数据集:NSL-KDD数据集(包含125973个训练数据,22543个带标记的测试数据,包含41个特征<38个数字特征,3个类别特征>)
评估方法(准确性):TP+TN / TP+TN+FP+FN
特征选择和模型训练:预处理阶段采用最大最小规格化和独热编码来处理NSL-KDD里数据特征;通过层叠式自动编码器学习到的编码表示<重要特征>来训练分类器完成检测。为了让实验有一个有效的拓扑结构,使用了贪婪分层无监督学习法来训练层叠式自动编码器。为了达到最佳效果,对41-28-28-16-28-28-41结构的叠层自动编码器(两个自动编解码器)进行了训练。在对层叠式自动编码器层进行训练后,瓶颈层将特征空间从41维降到16维。训练了单类分类层来识别正常包和异常包。与使用无监督学习的堆叠式自动编码器层不同,单类分类层使用带标记的数据来训练预测器(监督学习)。
性能评估: 试验阶段与J48决策树、支持向量机、贝叶斯网络以及基于相关性、信息增益两种特征选择策略进行了比较。结果如下表所示。

结论
本文提出了一种结合深度自动编码器和单类SVM的混合检测模型,深度自动编码器作为自动特征选取和姜维算法来进行训练(即对原始数据产生非线性变化,并将这些数据转换成低维特征集),然后将训练后的特征作为单类支持向量机的输入,训练异常检测分类器。