我变身了。。。
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
秒变黄金圣斗士
前段时间,我重温了一遍童年动画《圣斗士星矢》!看完十分有感触,那个时候自己经常幻想着变身成为最高级别的圣斗士:黄金圣斗士!拥有超强的战斗力,保护女神雅典娜...
小时候只能靠脑补和做梦!
万万没想到,现在只靠一部手机就能实现了!!!
你也想换装变身?很简单!腾讯微视联动《圣斗士星矢(腾讯)》手游上线“圣斗士集结”系列玩法。
打开腾讯微视app,点击下方+号,选择“全身换装圣斗士”特效,上传或拍摄一张单人无遮挡的正面照,即可进行黄金圣斗士铠甲换装。
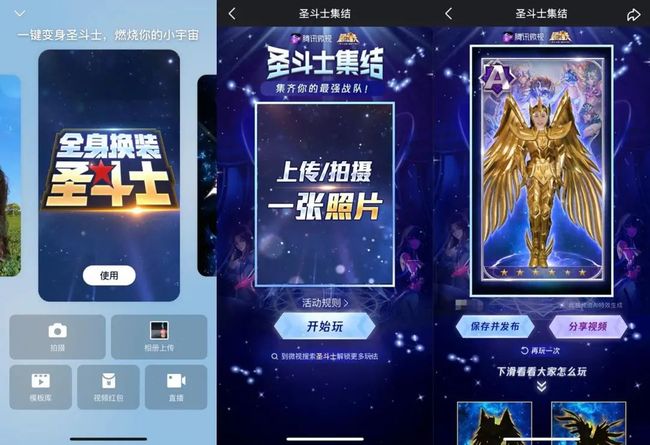
燃烧吧小宇宙,变身!
而且下载最新版的腾讯微视app,即可体验实时变身黄金圣斗士:
聊聊背后的AI黑科技
像运动捕捉(Motion Capture)技术,虽然能重建出非常精确的人体三维模型。但这种解决方案的成本极高,需要把大量的传感器安装在捕捉对象的身体上,并且需要高性能的昂贵设备对传感器数据进行处理,才能得到最终的结果。
然而这个相当真实的黄金圣斗士铠甲变身技术仅仅是依靠视觉输入信息!这样极大地降低了研发成本,还可以让更多的人“零成本”、快速地使用这项技术。
当然了,短短数秒内就完成圣斗士变身这个华丽特效的背后,实际涉及了多种AI技术,比如目标检测、2D/3D人体姿态估计、算法优化和部署等。下面将对部分算法技术进行介绍和分析:
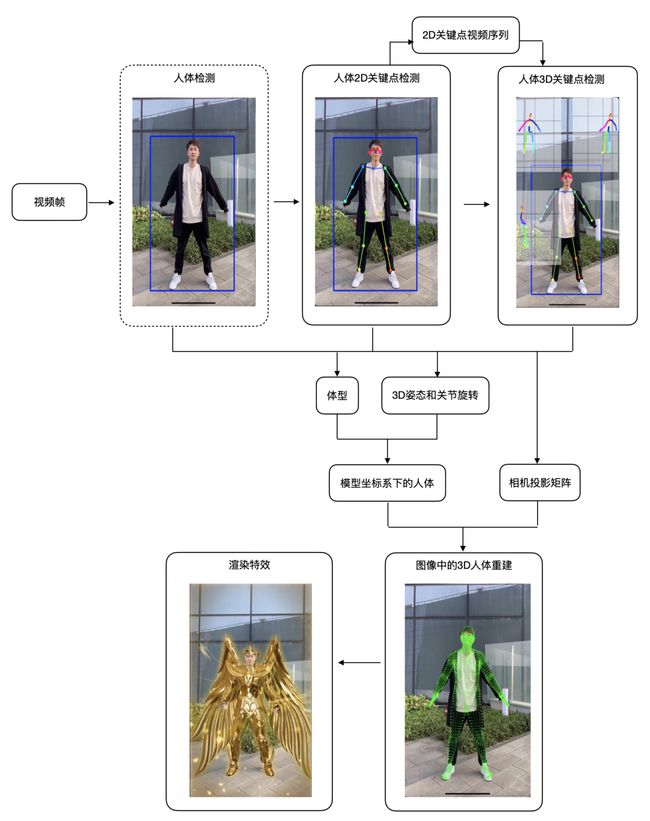
整体算法基本流程:
先将视频分成多帧图像,从每幅图像中检测出人体的区域(边界框);
然后计算出人体的2D关键点坐标信息(x, y),利用前后帧的时序信息估计出关键点的深度,即可得到3D关键点坐标(x, y, z);
再结合2D/3D以及图像信息估计出人的体型和3D姿态,获得人体在模型坐标系下的3D Mesh和相机的投影矩阵;
注:微视团队使用7千+个顶点和1.5+万的面片重建出图像坐标系下的人体3D Mesh,从图像中重建出的Mesh需要经过滤波处理去掉抖动,这样就得到了视频中的人体Mesh。
最后根据这些信息,利用渲染引擎给视频中的人“穿上”黄金圣斗士盔甲。
整体算法框架如下图所示:
这里重点介绍一下每个流程中使用到的关键技术。
人体(目标)检测技术
首先是从输入图像或者视频帧中检测出指定物体所在的位置。这个项目的目标物就是人体(Person)。
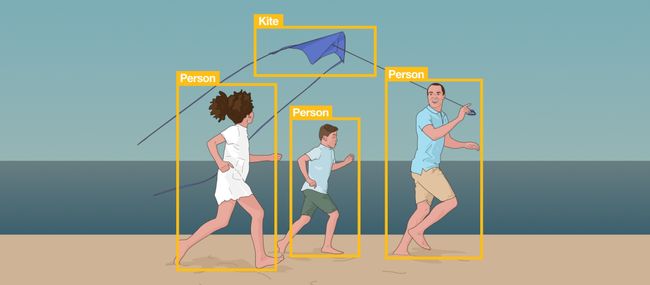
目标检测示意图
目前常用的目标检测方法主要分为以下几类:
Two-Stage 目标检测
-
代表性工作:R-CNN系列等
特性:需要先生成Region Proposals,再分类;精度相对高,速度较慢
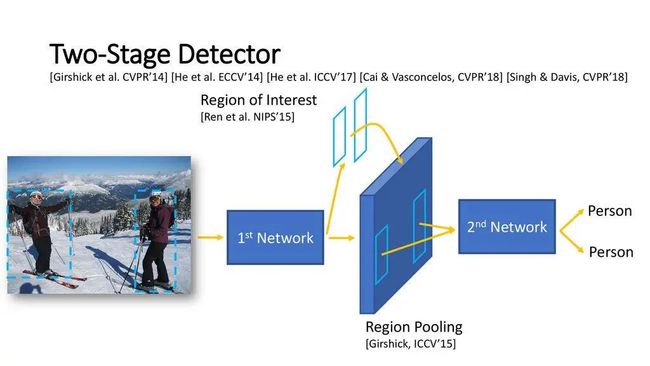
Two-Stage目标检测框图
One-Stage 目标检测
-
代表性工作:YOLO系列、RetinaNet等
特性:直接回归输出边界框和类别;精度相对也高,速度很快
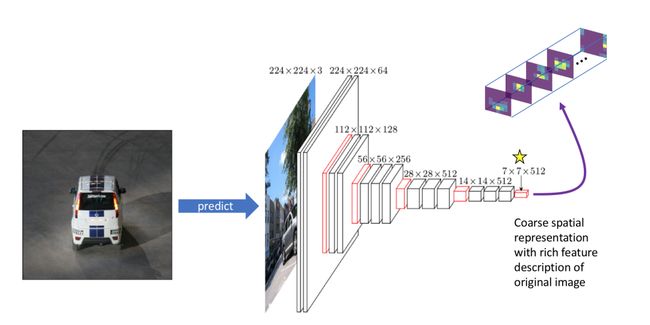
One-Stage目标检测框图
Anchor-free 目标检测
-
代表性工作:CornerNet、FCOS、CenterNet等
特性:不使用anchor提取候选框,精度相对也高,速度较快

FCOS 整体概念图
Transformer 目标检测
-
代表性工作:DETR、Deformable DETR等
特性:用了Transformer,更少的先验(没有NMS,没有anchor)
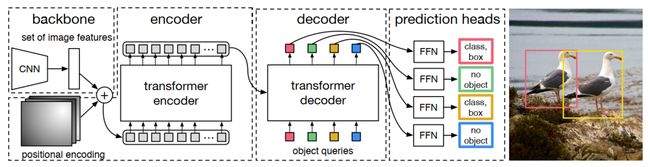
DETR 网络框图
2D/3D 人体姿态估计(关键点检测)技术
2D 人体姿态估计
从输入RGB图像或者视频帧中估计每个人体、每个关节的2D姿态 (x, y) 坐标。
常用的2D人体姿态估计方法主要有以下几类:
Top-Down(自上而下):先检测出图像中的所有人体,再对每个人体进行人体姿态估计。
-
代表性工作:SimpleBaseline、HRNet和CPN等
特性:精度较高,速度较慢,容易受人体数量、遮挡等问题影响
Bottom-Up(自下而上):先检测出图像中的所有parts,再对parts进行组装(assemble)。
-
代表性工作:OpenPose、PersonLab等
特性:精度相对较低,速度较快,容易受遮挡等问题影响
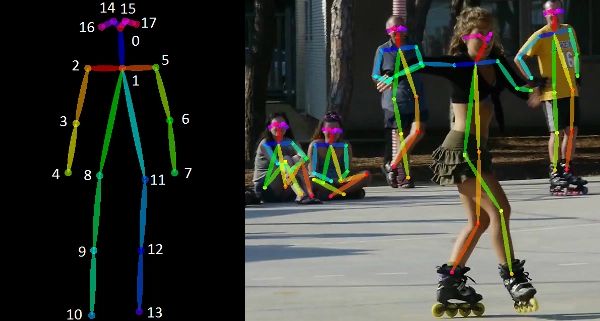
Top-Down(上)和Bottom-Up(下)方法的区别
3D 人体姿态估计
从输入RGB图像或者视频帧中估计每个人体、每个关节的3D姿态 (x, y, z) 坐标。
Model-Free
-
代表性工作:2D to 3D lifting等
特性:速度较快,网络相对简单,不适定性
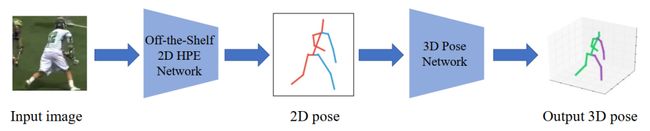
Model-Free检测框图
Model-Based
-
代表性工作:SMPL等
特性:不适定性

Model-Based检测框图
3D人体姿态估计示例图
3D人体Mesh重建技术
从RGB图像或视频帧中重建或恢复人体姿态的3D模型
Deep Learing
-
代表性方法:VIBE、Pose2Mesh
特性:数据获取成本大
Fitting
-
代表性方法:SMPL、SMPL-X
特性:精度较高、速度较慢

SMPL-X 示意图
3D Mesh 示例图
自研算法方案和优化
上面介绍的各个CV方向的代表性算法,一般无法直接部署在移动端,而且整体pipeline耗时较长。如果想在移动端(比如手机上)实时运行,必须完成整体到局部的优化。
为了实现高效的性能,微视团队主要从数据集制作、网络结构设计和优化、算法流程并行化、移动端模型高效推理以及算法细节打磨等几个方面进行了优化。
数据集制作
微视团队专门采集了数万个接近手机端用户拍摄内容的视频数据,并采样了几十万张视频帧图像。其中特别搭建一种低成本的硬件方案:3台AzureKinect、3台三脚架、数据同步线、USB延长线和Windows电脑一台。

然后,对所有图像进行2D人体关键点标注,并采用上面中提到的一系列算法进行处理,可得到了初步的3D Mesh数据。
再对这些数据进行清洗,从贴合度表现等多个方面对每一幅图像进行评估,去掉效果比较差的样本,最终得到了用于训练和评估的3D人体Mesh数据集。
网络Backbone结构的设计和优化
结合HRNet、MobileNet等轻量级网络的优势,在大规模数据上进行了不同结构设计的探索,并对目前不同计算能力的手机做针对性的设计,以保证对不同配置的手机在效果和速度上达到最佳的平衡。
算法流程并行化
对整体算法的流程进行优化,将人体检测、2D人体关键点、3D人体关键点、3D人体Mesh、相机姿态估计全部调整为并行实现,极大提高了整体算法的效率。
移动端模型高效推理
依托腾讯优图团队提供的TNN移动端深度推理框架,实现了移动端模型的高效推理。
为了保证整体算法的高效性能,对于特定的算子和矩阵运算,与优图TNN团队合作进行了针对性的底层优化。同时,也对模型的后处理进行了算法层面的改进,在保证不影响体验的情况下,获得更极致的运行效率。

经过上述一系列的优化后,算法的速度和效果得到了显著提升!但微视团队为了追求极致性能,于是针对不同的拍摄光照、不同的体型、衣着、拍摄距离、拍摄角度等场景中发现的Bad Case,团队又从训练方式、参数调整、Loss函数设计等方面进行了更加深度的研究,并解决了贴合度、检测稳定性等棘手问题。
最终,进一步压缩了模型计算开销,将单帧的总体处理时长从15ms优化到了当前的11ms。
特效渲染和视觉效果优化
特效渲染
得到人体3D Mesh还不够!微视团队专门设计了一套AttachToBody的特性渲染方案:
能够保证服装模型在三维世界和二维图像上位置和旋转正确,贴合人体表面;
能够提供PBR(基于物理的渲染)每个环节需要的正确信息,确保高质量的渲染效果。
同时,在原有引擎基础上开发了自定义材质系统,提供了更自由灵活的材质与光照解决方案。此外,部分机型上启用了IBL, SSAO等技术来提升整体的光影效果。
为了提升效果整体的覆盖率,在一些低端机型上采取了Material Capture材质捕捉技术方案,拟合出近似PBR的真实感效果。同时在一些高频且量大的矩阵计算中启用了NEON加速方案,整体降低了数学计算耗时。
视觉效果优化
视觉设计团队和算法团队协同合作,利用Light Studio等工具,实现对衣服SRT数据的精准调整,对环境光/衣服材质主要参数的可视调整等。最终达到较高标准的效果质量。
预期效果:

引擎实现:
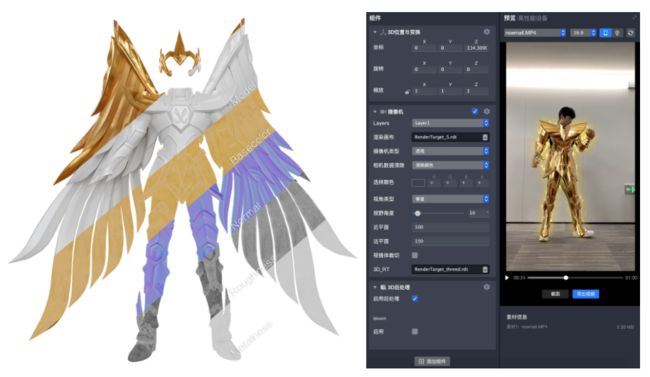
最终实际换装效果:
团队介绍
视频理解中心拍摄算法组
致力于视频业务场景下内容生产、制作和发布相关的技术创新研发,以技术赋能创作者。汇聚了一批行业内顶尖的算法专家和产品经验丰富的研究员和工程师,拥有丰富的业务场景,持续探索前沿AI、CV和CG算法在内容生产和消费领域的应用和落地。
团队持续招聘中,请联系 [email protected]
应用研究中心
平台与内容事业群(PCG)应用研究中心(Applied Research Center,ARC)作为PCG的侦察兵和特种兵,肩负着探索和挑战智能媒体相关前沿技术的使命,旨在成为世界一流应用研究中心和行业标杆,聚焦于音视频内容的生成、增强、检索和理解等方向。
团队持续招聘中,请联系 [email protected]
光流产品中心
围绕短视频拍摄与编辑业务场景,在图形特效,音视频编辑,美颜美妆,人脸/AR等相关玩法上有丰富的技术积累,并落地在微视,手机QQ,微信等产品中。团队未来将持续在2D/3D渲染,创作者工具,创意特效玩法,图形新能力等方向进行技术投入,致力于打造行业一流的短视频发布器一体化解决方案。
团队持续招聘中,请联系 [email protected]
MXD创意平台设计中心
拥有拍摄与视频编辑相关内业顶尖创意设计师,在创意拍摄玩法、视频特效、3D美术、美颜美妆、视频后编辑等相关有丰富的经验,服务于服务于腾讯在线视频BU。团队未来将继续研究拍摄趋势与视觉创新,发掘新潮的创意特效,致力于给用户带来更优质的创意玩法。
团队持续招聘中,请联系 [email protected]
未来展望
相信"黄金圣斗士全身换装"只是前菜,依托打造的数据集、算法优化、端侧加速和自研的前沿技术,微视团队后面将解锁更多好玩的特效和应用!给你带来更酷炫的体验!
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看