Spark 3.0 - 2.机器学习核心 DataFrame 应用 API 与操作详解
目录
一.引言
二.创建 DataFrame
1.CreateDataFrame
2.RDD toDF By Spark implicits
3.By Read Format File
三.常用处理 API
1.select 选择
2.selectExpr 表达式
3.collect / collectAsList 收集
4.count 统计
5.limit 限制
6.distinct 去重
7.filter 过滤
8.map 一对一
9.flatMap 一对多
10.drop 删除列
11.sort / orderBy 排序
四.常用采样 API
1.sample 采样
2.randomSplit 划分
五.数据互转
1.DF -> RDD
2.DF -> DS
3.DS -> DF
4.DS -> RDD
5.RDD -> DF
6.RDD -> DS
六.总结
一.引言
DataFrame 实质上是存在于不同节点计算机中的一张关系型数据表,RDD 可以看做是 DataFrame 的前身,DataFrame 是 RDD 的扩展。RDD 中可以存储任何类型的数据,但是直接使用 RDD 在字段需求明显时存在算子难以复用的缺点,这时候如果需要使用 RDD 我们需要定义相对复杂的处理逻辑,而通过 DataFrame 则可以通过列式存储数据的优势,快速将算子应用在多个列上,提高开发效率,例如我们可以一行代码求 A 列的 SUM,B 列的 MAX,C 列的 MIN,而使用 RDD 则需要 GroupBy 或者相对复杂的 ProcessFunction。
二.创建 DataFrame
DataFrame 可以看做是 RDD[Row] + Schema,通过 Schema 指定每一列的属性,从而使得框架能够了解数据的结构与类型,Spark 实际使用中 Schema 需要通过 StrucType 类并指定每个字段的 StructFields ,域中明确了列名、数据类型以及一个 Boolean 参数代表该字段是否可以为空。
1.CreateDataFrame
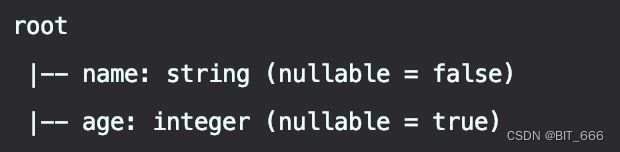
首先通过二元数组生成 RDD[Row],随后通过 StructType + StrucField 定义每一列数据的类型,这里第一列为 Name,String 类型,不可以为 null,第二列为 Age,Int 类型,可以为 null。
import org.apache.spark.internal.Logging
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
val spark = SparkSession
.builder()
.master("local")
.appName("TestDataFrame")
.getOrCreate()
val sc = spark.sparkContext
sc.setLogLevel("error")
// 1.1 Create DataFrame
val schema =
StructType(
StructField("name", StringType, false) ::
StructField("age", IntegerType, true) :: Nil
)
val random = scala.util.Random
val peoples = sc.parallelize((0 to 100).map(_ => {
val name = random.nextString(5)
val age = random.nextInt(50)
(name, age)
}))
val dataFrame = spark.createDataFrame(peoples.map(p => Row(p._1, p._2)), schema)
dataFrame.printSchema()
dataFrame.createOrReplaceTempView("people")
spark.sql("select name from people").collect().foreach(println(_))可以通过 printSchema 输出 DataFrame 的 schema,也可以通过 createOrReplaceTempView 注册临时表,并最终通过 sql 执行相关语句,这在一定程度上与 Flink SQL 很类似:
Tips:
这里初始化 Schema 的 StructType 时用到了 Scala List 的简易写法,其中 :: 代表连接列表元素,例如 A :: B :: C :: Nil 可以看做是 List[A, B, C],除此之外,还可以通过 ::: 三个冒号连接两个列表,代表二者的 concat 合并,例如 A :: B :: C :: Nil ::: DDD :: Nil,其实就是 List[A, B, C, D]。感兴趣的同学可以自己本地测试下述 Demo。
val site = "A" :: "B" :: "C" :: Nil ::: "DDD" :: Nil
println(site.length)
site.foreach(println(_))2.RDD toDF By Spark implicits
常见的方法除了生成 RDD 再指定 Schema 外,也可以引入 spark.implicits._ 隐式转换,通过 RDD.toDF() 方法转换生成 DataFrame,此时 Spark 可以自动推断 DF 的 Schema。
import spark.implicits._
val peopleDF = peoples.toDF("name", "age")
peopleDF.printSchema()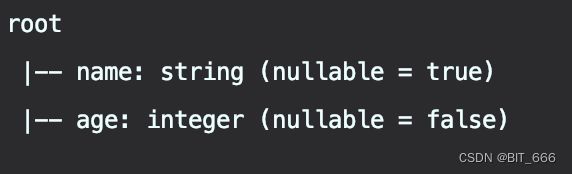
可以看到自动 infer 推断得到的 Schema nullable 与我们上面自定义的 Schema 是反的,上面是 Name 不为空, Age 可以为空,自动推断的结果是 Name: String 可以为空,而 Age: Int 不能为空。
3.By Read Format File
上面两种方法都用到了 RDD 并做转换,还有一种方式可以直接生成 DataFrame,即读取指定 format 的文件,例如 CSV、Json、Parquet 等等,下面示例 Json 的读取方法:
val peopleFromJson = spark.read.schema(schema).json("people.json")
peopleFromJson.collect().foreach(println(_))Json 文件中数据如下:
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
三.常用处理 API
1.select 选择
peopleDF.select("name").take(10)
select 用于选择 dataframe 中某些列:

2.selectExpr 表达式
peopleDF.selectExpr("name as NAME").printSchema()
基于 dataframe 原有列进行特殊处理,可以指定不同 SQL 表达式,修改列名后 DataFrame 对应的 schema 也相应改变:

3.collect / collectAsList 收集
peopleDF.collect().take(5).foreach(println(_))
peopleDF.collectAsList().forEach(x => println(x))二者均可以将 DataFrame 的数据拉取到本级内存或任务 Master 上,唯一区别在于返回值类型,前者为 Scala Array[T],后者为 Java List
4.count 统计
println(peopleDF.count())
count 用于获取 DataFrame 的行数,除此之外,count 也视为 Spark 的 Action 算子,可以触发 Spark 执行逻辑。
5.limit 限制
peopleDF.limit(5).show()
用于限制表中数据,这里可以理解为 TopN。
6.distinct 去重
println(peopleDF.distinct().count())
可以实现数据集中的重复项。
7.filter 过滤
println(peopleDF.filter("age > 18").count())
按照条件对数据集进行过滤。
8.map 一对一
val rdd = sc.parallelize(Seq("hello,spark", "hello,hadoop"))
rdd.toDF("id").map(x => "str:" + x).show()用于数据集处理的一一映射。
9.flatMap 一对多
val rdd = sc.parallelize(Seq("hello,spark", "hello,hadoop"))
rdd.toDF("id").flatMap(x => x.toString().split(",")).show()
对数据集整体操作,并最终展平,可以看做是 map + flatten 的组合体。
10.drop 删除列
peopleDF.drop("name").printSchema()删除某一列。
11.sort / orderBy 排序
dataFrame.sort(dataFrame("age").asc_nulls_first).show()
dataFrame.orderBy(dataFrame("age").asc_nulls_first).show()根据数据集中某个字段排序,其中 asc 与 desc 可以选择升序与降序,除此之外还新添加了 asc_nulls_first、desc_nulls_first、asc_nulls_last、desc_nulls_last 分别指定排序类型与排序结果中缺失值在前还是在后展示。
四.常用采样 API
除了基础处理函数外,DataFram 还提供采样 API,这对于机器学习场景中数据集的划分十分有效。
1.sample 采样
dataFrame.sample(false, 0.8, 10).show()
三个参数分比为:
withReplacement : 是否放回,false 代表不放回,true 为放回
ratio : 代表采样比例,注意最终数量不一定完全符合比例
seed : 随机种子,如果 seed 不变,则采样结果不变
上述代码代表以 seed=10,不放回采样原始数据的 80% 左右数据
2.randomSplit 划分
val split = dataFrame.randomSplit(Array(0.25, 0.75), 10) // 按比例划分
println(split(0).count())
println(split(1).count())通过 Array 指定划分比例,数组中有多少权重就会生成多少个 DataFrame,如果权重和不为1,spark 会自动将其标准化,这在生成训练集、测试集、验证集时非常常用,除此之外,划分分组也需要指定随机种子 seed。
上述代码代表以 seed = 10,以 1:3 的比例划分数据集。
五.数据互转
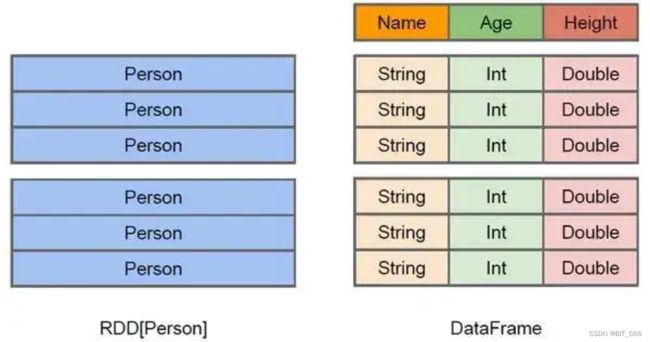
前面我们已经提到 DataFrame = RDD[Row] + schema,除此之外,还有 DataFrame = DataSet[Row],可以看到 RDD 是特殊的 DataFrame,DataFrame 又是特殊的 DataSet,通过 spark.implicits._ 可以实现三者的轻松转换。
1.DF -> RDD
val rdd1 = dataFrame.rdd // DF -> RDD
2.DF -> DS
val ds = dataFrame.as[Person] // DF -> DS
这里 Person 为 case class:
case class Person(name: String, age: Int)
注意不要将 case class 放下 main 函数内,否则代码编译会报错无法编码。
3.DS -> DF
val df = ds.toDF() // DS -> DF
4.DS -> RDD
val rdd2 = ds.rdd // DS -> RDD
5.RDD -> DF
val df2 = rdd.toDF("name") // RDD -> DF
6.RDD -> DS
val ds2 = rdd.map(x => Person(x, 1)).toDS() // RDD -> DS
Tips:
从上面的转换可以看出,携带信息多的数据类型向携带数据少的类型转换无需提供额外信息,例如 DS 或者 DF 转 RDD,只需要 .rdd 方法即可,而信息少的数据向信息多的数据转换时则需补充额外信息,例如 RDD 或者 DF 转换至 DS,都需要补充 DS[T] 的类信息 T,上述实例中 T 为 Person。
六.总结
DataFrame 是 Spark 机器学习的基础也是核心,后续章节的大部分 DataFrame 操作都将基于上述操作实现或拓展。