GBDT算法原理讲解以及常用的训练框架汇总:XGBoost LightGBM CatBoost NGBoost
目录
- 1 基础知识点
-
- 1.1 Ensemble Learning
- 1.2 Bagging and Boosting
- 1.3 Adaptive Boosting
- 1.3 Gradient Boosting
- 2 GBDT算法
-
- 2.1 原理
- 2.2 训练
- 2.3 预测
- 3 训练框架
-
- 3.1 XGBoost
- 3.2 LightGBM
- 3.3 CatBoost
- 3.4 NGBoost
- 4 树模型与深度模型结合
- 6 参考资料
1 基础知识点
1.1 Ensemble Learning
集成学习 (Ensemble Learning) 是机器学习 (Machine Learning) 里面核心的概念。它的主要思想归纳起来就是:通过训练多个弱学习器来达到一个强学习器的效果,组合后的表现比任何一个弱学习器的效果都好。在机器学习里error可以大概分两类:一类是偏差错误 (bias error):指的是预测值与真实值的差异,另外一类是方差错误 (variance error):指的是预测值作为随机变量的离散程度,而集成学习正好可以降低这些问题。通过组合多个分类器的结果可以降低模型预测的偏差,特别是对于一些不稳定的学习器,所以集成学习出来的学习器有更高的稳定性。而在集成学习中,常见的方法是Baging和Boosting,接下来我们先对这两个方法进行简单描述。
1.2 Bagging and Boosting
使用Bagging或者Boosting技术,我们必须选择一个base学习器。例如,我们可以选择分类tree,那么Bagging和Boosting会组合成一系列树学习器变成一个集成的学习器,接下来,Bagging和Boosting怎么训练得到N个学习器呢?
-
第一:训练数据选择
每次从原始训练数据集中生成N份新的训练数据集,然后分别训练这N个学习器。在生成每份新的训练数据集的时候,Bagging是随机选择样本,也就是说每个样本出现在新的训练集的概率是一样的,而Boosting会根据样本的权重去选择,所以有些样本会在新的训练集里更高概率被选中。 -
第二:训练过程
其中Bagging和Boosting的最主要不同点在于训练过程,其中Bagging在训练阶段是并行的,每个训练器都是独立的,而Boosting是基于序列方式建立每个训练器,新的训练器建立依赖于上一个训练器,所以不是独立的,对比图如下:

在Boosting算法中,每个分类器的训练数据选择,依赖于上个分类器的预测结果,所以在每个训练步骤中,样本的权重是会重新调整的,其中预测错误的数据会增大权重,在概率上会更有可能被选中进入下个分类器进行训练,重点关注这些hard sample的识别。
- 第三:预测过程
训练完N个学习器后,预测结果上面,Bagging和Boosting存在差异,Bagging策略,最终的结果是N个学习器结果的平均值,而Boosting的预测结果是加权之和,用公式表示如下:
Bagging = 1 N ∑ i = 1 N s i \text{Bagging} = \frac{1}{N} \sum_{i=1}^N s_i Bagging=N1i=1∑Nsi
Boosting = ∑ i = 1 N w i s i \text{Boosting} = \sum_{i=1}^N w_is_i Boosting=i=1∑Nwisi
其中权重 w i w_i wi会根据每个分类器预测的结果表现进行分配,表现越好的学习器对应的权重越大。但并不是说Boosting一定比Bagging好,需要根据具体的数据集,学习器等多个因素考虑,若单个学习器表现效果很差,那么Bagging就很难得到一个强大的学习器,但是Boosting优化策略正好可以将多个学习器的效果加强。相反,若每个学习器都过拟合了,那么Bagging是最好的选择,而Boosting对于避免过拟合没有什么帮助。
1.3 Adaptive Boosting
Adaptive Boosting (AdaBoost) 是一种Boosting方法,Boosting核心思想就是从上一个模型错误中进行学习。而AdaBoost学习方法主要是通过对分错的样本加大权重,让下一个模型更关注分错的样本识别效果。训练的基本步骤如下:
- 训练一个树模型
- 计算这颗树模型分错的错误率 e e e
- 根据错误率计算这颗决策树的wieght: learning_rate * log((1-e) /e),所以错误率e越大,weight权重越小
- 更新每个样本的权重:模型分对的样本,权重不变;分错的样本,新的权重为:old_weight * np.exp(weight of this tree),更新后,样本的权重变大,在接下来的步骤中会加强对这类分错的样本进行识别
- 重复上面步骤,直到训练的树已经达到最大值
- 进行最终的预测:通过加权投票机制预测每个候选集样本
1.3 Gradient Boosting
梯度提升 (Gradient Boosting) 也是一种Boosting方法,在上面我们提到,boosting模型的核心点是从先前的错误中进行学习,而Gradient Boosting每次迭代通过直接拟合上一步的残差 (目标损失函数对输出值的偏导数) ,使得当前t步的预测结果等于目标损失函数对上一步t-1预测值的负梯度方向,从而可以通过每次迭代 ( f t ( x i ) = f t − 1 ( x i ) − ∂ L ( y i , f t − 1 ( x i ) ) ∂ f t − 1 ( x i ) f_t(x_i) = f_{t-1}(x_i)-\frac{\partial L(y_i,f_{t-1}(x_i))}{\partial f_{t-1}(x_i)} ft(xi)=ft−1(xi)−∂ft−1(xi)∂L(yi,ft−1(xi)))不断降低目标损失loss,算法流程如下:
1. 初 始 化 : f 0 ( x ) = argmin γ ∑ i = 1 N L ( y i , γ ) 1.初始化: f_0(x) = \text{argmin}_\gamma \sum_{i=1}^N L(y_i, \gamma) 1.初始化:f0(x)=argminγ∑i=1NL(yi,γ)
2. for t = 1 to T : 2. \text{for} \text{ } t=1 \text{} \text{to} \text{ }T: 2.for t=1to T:
( a ) 计 算 负 梯 度 : y ^ i = − ∂ L ( y i , f t − 1 ( x i ) ) ∂ f t − 1 ( x i ) , i = 1 , 2 , . . . N \text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }(a) 计算负梯度: \hat{y}_i =- \frac{\partial L(y_i,f_{t-1}(x_i))}{\partial f_{t-1}(x_i)}, i=1,2,...N (a)计算负梯度:y^i=−∂ft−1(xi)∂L(yi,ft−1(xi)),i=1,2,...N
( b ) 通 过 最 小 化 平 方 误 差 , 用 基 学 习 器 h t ( x ) 拟 合 y ^ i , \text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }(b)通过最小化平方误差,用基学习器h_t(x)拟合\hat{y}_i, (b)通过最小化平方误差,用基学习器ht(x)拟合y^i,
w t = argmin w ∑ i = 1 N L ( y ^ i − h t ( x i ; w ) ] 2 \text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ } w_t = \text{argmin}_w \sum_{i=1}^N L(\hat{y}_i - h_t(x_i; w)]^2 wt=argminw∑i=1NL(y^i−ht(xi;w)]2
( c ) 使 用 L i n e s e a r c h 确 定 步 长 ρ m , 以 使 L 最 小 \text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }(c) 使用Linesearch确定步长\rho_m,以使L最小 (c)使用Linesearch确定步长ρm,以使L最小,
ρ t = argmin ρ ∑ i = 1 N L ( y i , f t − 1 ( x i ) + ρ h t ( x i ; w t ) ) \text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ } \rho_t = \text{argmin}_{\rho} \sum_{i=1}^N L(y_i, f_{t-1}(x_i) + \rho h_t(x_i;w_t)) ρt=argminρ∑i=1NL(yi,ft−1(xi)+ρht(xi;wt))
( d ) f t ( x ) = f t − 1 ( x ) + ρ t h t ( x ; w t ) \text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }(d) f_t(x) = f_{t-1}(x)+\rho_th_t(x;w_t) (d)ft(x)=ft−1(x)+ρtht(x;wt)
3. 输 出 f M ( x ) 3.输出 f_M(x) 3.输出fM(x)
2 GBDT算法
2.1 原理
GBDT (Gradient Boosting Decision Tree) 是梯度提升树,接下来我们详细推导算法的细节过程。
1)GBDT预测结果值表达
假设我们有K个树,第k颗树的预测值我们用函数 f k ( x ) f_k(x) fk(x)表示,则对于一个样本 x i x_i xi,最终预测的结果值为:
y i ^ = ∑ k = 1 K f k ( x i ) \hat{y_i}=\sum_{k=1}^Kf_k(x_i) yi^=k=1∑Kfk(xi)
2)定义目标损失函数
损失函数用来度量模型预测的值与真实标签值之间的差异,同时一般会增加正则化项来惩罚模型的权重参数,避免模型过于复杂,但是基于树模型算法,由于没有权重参数需要优化,因此需要其它的方式来惩罚模型的复杂性。一般对于树模型,通常正则化项会从树的深度,树的叶子节点数或者叶子节点权重值的L2范数等作为因子。通常,如果一颗树的叶子节点越多,树越深越容易过拟合,或者叶子节点权重分值越高,这些都容易导致过拟合。综合这些问题,那么对于树模型,我们可以定义的目标损失函数如下:
O b j = ∑ i = 1 n l ( y i , y i ^ ) + ∑ k = 1 K Ω ( f k ) Obj = \sum_{i=1}^n l(y_i, \hat{y_i}) + \sum_{k=1}^K\Omega(f_k) Obj=i=1∑nl(yi,yi^)+k=1∑KΩ(fk)
其中 l ( y i , y ^ i ) l(y_i, \hat{y}_i) l(yi,y^i)度量的是模型预测的与真实标签的差异值, Ω ( f k ) \Omega(f_k) Ω(fk)是正则化项,对模型的复杂度进行一个度量,防止模型过拟合。我们的目标就是最小化上述目标损失函数。
3)目标损失函数变形
有了目标函数,那么模型怎么学习?由于我们要训练的是基于树结构的函数 f t ( x ) f_t(x) ft(x),而不是数值型向量,不能用梯度下降方法求解。所以需要另外一种叫additive training (boosting) 方法来找到最优解。
假设初始值为0,对于每增加一棵树,预测的结果值迭代形式如下:
y i ^ ( 0 ) = 0 \hat{y_i}^{(0)} = 0 yi^(0)=0
y i ^ ( 1 ) = f 1 ( x i ) = y i ^ ( 0 ) + f 1 ( x i ) \hat{y_i}^{(1)} = f_1(x_i) = \hat{y_i}^{(0)} + f_1(x_i) yi^(1)=f1(xi)=yi^(0)+f1(xi)
y i ^ ( 2 ) = f 1 ( x i ) + f 2 ( x i ) = y i ^ ( 1 ) + f 2 ( x i ) \hat{y_i}^{(2)} = f_1(x_i) + f_2(x_i) = \hat{y_i}^{(1)} + f_2(x_i) yi^(2)=f1(xi)+f2(xi)=yi^(1)+f2(xi)
…
y i ^ ( t ) = ∑ k = 1 t f k ( x i ) = y i ^ ( t − 1 ) + f t ( x i ) \hat{y_i}^{(t)} =\sum_{k=1}^tf_k(x_i) = \hat{y_i}^{(t-1)} + f_t(x_i) yi^(t)=∑k=1tfk(xi)=yi^(t−1)+ft(xi)
从上述公式可以看出,在t步,最终的预测结果是累积前面t-1步的所有结果与当前的树的结果之和(这里暂时先不考虑学习率因子控制每棵树的权值分值的缩放)。我们对目标函数进行展开如下:
O b j ( t ) = ∑ i = 1 n l ( y i , y i ^ ( t ) ) + ∑ i = 1 t Ω ( f i ) Obj^{(t)}=\sum_{i=1}^nl(y_i,\hat{y_i}^{(t)}) + \sum_{i=1}^t \Omega(f_i) Obj(t)=∑i=1nl(yi,yi^(t))+∑i=1tΩ(fi)
= ∑ i = 1 n l ( y i , y i ^ ( t − 1 ) + f t ( x i ) ) + Ω ( f t ) + c o n s t \text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }=\sum_{i=1}^nl(y_i, \hat{y_i}^{(t-1)} + f_t(x_i)) + \Omega(f_t) +const =∑i=1nl(yi,yi^(t−1)+ft(xi))+Ω(ft)+const
假设我们的目标损失函数为均方误差,则转换如下:
O b j ( t ) = ∑ i = 1 n ( y i − ( y i ^ ( t − 1 ) + f t ( x i ) ) ) 2 + Ω ( f t ) + c o n s t Obj^{(t)} = \sum_{i=1}^n (y_i - (\hat{y_i}^{(t-1)} + f_t(x_i)))^2 + \Omega(f_t) + const Obj(t)=∑i=1n(yi−(yi^(t−1)+ft(xi)))2+Ω(ft)+const
= ∑ i = 1 n [ 2 ( y i ^ ( t − 1 ) − y i ) f t ( x i ) + f t ( x i ) 2 ] + Ω ( f t ) + c o n s t \text{ }\text{ }\text{ }\text{ }\text{ }= \sum_{i=1}^n[2(\hat{y_i}^{(t-1)} - y_i)f_t(x_i) + f_t(x_i)^2] + \Omega(f_t) + const =∑i=1n[2(yi^(t−1)−yi)ft(xi)+ft(xi)2]+Ω(ft)+const
由于函数 f t ( x i ) f_t(x_i) ft(xi)与 y i ^ ( t − 1 ) \hat{y_i}^{(t-1)} yi^(t−1)没有任何联系,上述目标函数第二步变化中,公式省去了单独的 y i ^ ( t − 1 ) \hat{y_i}^{(t-1)} yi^(t−1)项。接下来介绍的是基于泰勒公式原理对GBDT优化求解的方案。
4)泰勒公式
泰勒公式是为了研究复杂函数性质时经常使用的近似方法之一,也是函数微分学的一项重要应用内容。如果函数满足一定的条件,泰勒公式可以用函数在某一点的各阶导数值做系数构建一个多项式来近似表达这个函数。公式展开形式如下:
f ( x + Δ x ) ≈ f ( x ) + f ′ ( x ) Δ x + 1 2 f ′ ′ ( x ) Δ x 2 f(x+\Delta x) \approx f(x) + f^{'}(x)\Delta x + \frac{1}{2}f^{''}(x)\Delta x^2 f(x+Δx)≈f(x)+f′(x)Δx+21f′′(x)Δx2
5)目标函数用泰勒展开式表示
那么接下来,我们对目标函数进行泰勒展开,求解过程如下:
O b j ( t ) = ∑ i = 1 n l ( y i , y i ^ ( t − 1 ) + f t ( x i ) ) + Ω ( f t ) + c o n s t Obj^{(t)} = \sum_{i=1}^nl(y_i,\hat{y_i}^{(t-1)} + f_t(x_i)) + \Omega(f_t) + const Obj(t)=i=1∑nl(yi,yi^(t−1)+ft(xi))+Ω(ft)+const
我们令:
g i = ∂ y i ^ ( t − 1 ) l ( y i , y ^ ( t − 1 ) ) g_i = \partial_{\hat{y_i}^{(t-1)}}l(y_i, \hat{y}^{(t-1)}) gi=∂yi^(t−1)l(yi,y^(t−1))
h i = ∂ y i ^ ( t − 1 ) 2 l ( y i , y i ^ ( t − 1 ) ) h_i = \partial_{\hat{y_i}^{(t-1)}}^2l(y_i, \hat{y_i}^{(t-1)}) hi=∂yi^(t−1)2l(yi,yi^(t−1))
其中 g i g_i gi和 h i h_i hi分别代表的是目标函数 l ( y i , y i ^ ( t − 1 ) ) l(y_i, \hat{y_i}^{(t-1)}) l(yi,yi^(t−1))对 y ^ ( t − 1 ) \hat{y}^{(t-1)} y^(t−1)的一阶和二阶导数。所以我们的目标函数泰勒展开公式为:
O b j ( t ) ≈ ∑ i = 1 n [ l ( y i , y i ^ ( t − 1 ) ) + g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] + Ω ( f t ) + c o n s t Obj^{(t)} \approx \sum_{i=1}^n[l(y_i, \hat{y_i}^{(t-1)}) + g_if_t(x_i) + \frac{1}{2}h_if^2_t(x_i)] + \Omega(f_t) + const Obj(t)≈i=1∑n[l(yi,yi^(t−1))+gift(xi)+21hift2(xi)]+Ω(ft)+const
若考虑目标损失函数是均方差,则 g i g_i gi和 h i h_i hi计算结果为:
g i = ∂ y i ^ ( t − 1 ) ( y i ^ ( t − 1 ) − y i ) 2 = 2 ( y i ^ ( t − 1 ) − y i ) g_i = \partial_{\hat{y_i}^{(t-1)}}(\hat{y_i}^{(t-1)}-y_i)^2=2(\hat{y_i}^{(t-1)}-y_i) gi=∂yi^(t−1)(yi^(t−1)−yi)2=2(yi^(t−1)−yi)
h i = ∂ y i ^ ( t − 1 ) 2 ( y i ^ ( t − 1 ) − y i ) 2 = 2 h_i = \partial_{\hat{y_i}^{(t-1)}}^2(\hat{y_i}^{(t-1)}-y_i)^2=2 hi=∂yi^(t−1)2(yi^(t−1)−yi)2=2
所以我们对目标函数化解为:
O b j ( t ) ≈ ∑ i = 1 n [ l ( y i , y i ^ ( t − 1 ) ) + g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] + Ω ( f t ) + c o n s t Obj^{(t)} \approx \sum_{i=1}^n[l(y_i, \hat{y_i}^{(t-1)}) + g_if_t(x_i) + \frac{1}{2}h_if^2_t(x_i)] + \Omega(f_t) + const Obj(t)≈i=1∑n[l(yi,yi^(t−1))+gift(xi)+21hift2(xi)]+Ω(ft)+const
= ∑ i = 1 n [ 2 ( y i ^ ( t − 1 ) − y i ) f t ( x i ) + f t ( x i ) 2 ] + Ω ( f t ) + c o n s t = \sum_{i=1}^n[2(\hat{y_i}^{(t-1)}-y_i)f_t(x_i) + f_t(x_i)^2]+ \Omega(f_t) + const =i=1∑n[2(yi^(t−1)−yi)ft(xi)+ft(xi)2]+Ω(ft)+const
由于常量对于目标函数优化没有影响,所以去掉常量部分,进一步化解为:
= ∑ i = 1 n [ g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] + Ω ( f t ) = \sum_{i=1}^n[g_if_t(x_i) + \frac{1}{2}h_if^2_t(x_i)] + \Omega(f_t) =i=1∑n[gift(xi)+21hift2(xi)]+Ω(ft)
其中 g i g_i gi和 h i h_i hi分别代表的是目标函数 l ( y i , y i ^ ( t − 1 ) ) l(y_i, \hat{y_i}^{(t-1)}) l(yi,yi^(t−1))对 y ^ ( t − 1 ) \hat{y}^{(t-1)} y^(t−1)的一阶和二阶导数。
6)正则化项 Ω ( f t ) \Omega(f_t) Ω(ft)
那么目标函数的正则化项 Ω ( f t ) \Omega(f_t) Ω(ft)是如何表达呢?我们首先要明确的是,正则化项的目的是防止模型过拟合,所以需要防止模型过于复杂,基于树模型结构,我们可以定义正则化公式如下:
Ω ( f f ) = γ T + 1 2 λ ∑ j = 1 T w j 2 \Omega(f_f) = \gamma T + \frac{1}{2}\lambda \sum_{j=1}^Tw_j^2 Ω(ff)=γT+21λj=1∑Twj2
其中 T T T表示的是叶子节点数, w j w_j wj表示的是第 j j j个叶子节点的分值,从正则化公式表达来看,我们可以看出,正则化项防止一棵树叶子节点过多且叶子节点值不能过大。如下图所示:

则 Ω \Omega Ω计算结果为: γ 3 + 1 2 λ ( 4 + 0.01 + 1 ) \gamma^3 + \frac{1}{2}\lambda(4+0.01+1) γ3+21λ(4+0.01+1),在前面的目标损失函数中,我们知道 f t ( x ) f_t(x) ft(x)是模型结果的预测分值,那么对于树模型结构我们令:
f t ( x ) = w q ( x ) f_t(x) = w_{q(x)} ft(x)=wq(x)
其中 w ∈ R T w \in \text{R}^T w∈RT是T维度向量,元素里的每个值表示的是每个叶子节点分值。 q ( x ) q(x) q(x)是映射函数,对于样本x,映射到树结构的具体哪个叶子节点。将正则化项和树模型结构表示带入上述目标函数为:
O b j ( t ) ≈ ∑ i = 1 n [ g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] + Ω ( f t ) Obj^{(t)} \approx \sum_{i=1}^n[g_if_t(x_i) + \frac{1}{2}h_if^2_t(x_i)] + \Omega(f_t) Obj(t)≈i=1∑n[gift(xi)+21hift2(xi)]+Ω(ft)
= ∑ i = 1 n [ g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] + γ T + 1 2 λ ∑ j = 1 T w j 2 =\sum_{i=1}^n[g_if_t(x_i) + \frac{1}{2}h_if^2_t(x_i)] + \gamma T + \frac{1}{2}\lambda \sum_{j=1}^Tw_j^2 =i=1∑n[gift(xi)+21hift2(xi)]+γT+21λj=1∑Twj2
= ∑ j = 1 T [ ( ∑ i ∈ I j g i ) w j + 1 2 ( ∑ i ∈ I j h i + λ ) w j 2 ] + γ T = \sum_{j=1}^T[(\sum_{i \in I_j}g_i)w_j+\frac{1}{2}(\sum_{i \in I_j}h_i + \lambda)w_j^2] + \gamma T =j=1∑T[(i∈Ij∑gi)wj+21(i∈Ij∑hi+λ)wj2]+γT
我们定义:
G j = ∑ i ∈ I j g i G_j = \sum_{i \in I_j} g_i Gj=i∈Ij∑gi
H j = ∑ i ∈ I j h i H_j = \sum_{i \in I_j} h_i Hj=i∈Ij∑hi
则我们对上述目标函数进一步化解得到:
O b j ( t ) = ∑ j = 1 T [ ( ∑ i ∈ I j g i ) w j + 1 2 ( ∑ i ∈ I j h i + λ ) w j 2 ] + γ T Obj^{(t)}= \sum_{j=1}^T[(\sum_{i \in I_j}g_i)w_j+\frac{1}{2}(\sum_{i \in I_j}h_i + \lambda)w_j^2] + \gamma T Obj(t)=j=1∑T[(i∈Ij∑gi)wj+21(i∈Ij∑hi+λ)wj2]+γT
= ∑ j = 1 T [ G j w j + 1 2 ( H j + λ ) w j 2 ] + γ T =\sum_{j=1}^T[G_jw_j+\frac{1}{2}(H_j+\lambda)w_j^2]+\gamma T =j=1∑T[Gjwj+21(Hj+λ)wj2]+γT
其中 w j w_j wj是我们要优化的值,也就是树结构中的叶子节点值,最小化上述目标损失函数,我们对 w j w_j wj求导并且令结果等于0:
∑ j = 1 T [ G j + ( H j + λ ) w j ] = 0 \sum_{j=1}^T[G_j+(H_j+\lambda)w_j]=0 j=1∑T[Gj+(Hj+λ)wj]=0
则可以得到如下值:
w j ∗ = − G j H j + λ w_j^* = -\frac{G_j}{H_j+\lambda} wj∗=−Hj+λGj
将 w j ∗ w_j^* wj∗值带入到目标损失函数,可以得到目标损失函数为:
O b j ( t ) = − 1 2 ∑ j = 1 T G j 2 H j + λ + γ T Obj^{(t)} = -\frac{1}{2}\sum_{j=1}^T \frac{G_j^2}{H_j+\lambda} + \gamma T Obj(t)=−21j=1∑THj+λGj2+γT
得到了最终的目标损失函数表达,我们要求解的是 g i g_i gi和 h i h_i hi,其中 G j G_j Gj和 H j H_j Hj分别表示的是在叶子节点 j j j的所有样本的一阶导数 g g g分数之和以及二阶导数 h h h的分数之和。所以对于任何一种结构树,样本所到达的叶子节点,我们都可以计算出目标损失函数值,如下图所示:
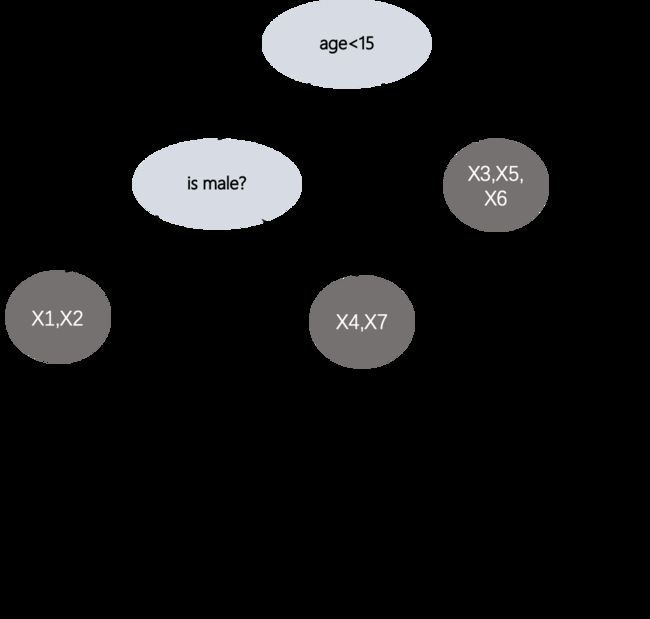
7)如何求解一颗树的最优分割结构
为了使得Obj最小,我们需要计算所有组合分割的树,然后根据上述公式,计算每一棵树的目标损失值,最后选择损失值最小的树结构。这样是否可行?肯定不可行,穷举所有树的结构,复杂度太高。所以,我们在树的每一层是否需要对节点切分成左节点和右节点,取决与分割后目标损失值是否比不切割前少,以及按照什么特征点切分,切分阈值,选择收益最大(新选择的切割点后目标损失loss值最低),切分收益gain计算如下(切割前的loss - 切割后的loss):
G a i n = 1 2 [ G L 2 H L + λ + G R 2 H R − λ − ( G L + G R ) 2 H L + H R + λ ] − γ Gain = \frac{1}{2}[\frac{G_L^2}{H_L + \lambda} + \frac{G_R^2}{H_R - \lambda} - \frac{(G_L+G_R)^2}{H_L+H_R+\lambda}]-\gamma Gain=21[HL+λGL2+HR−λGR2−HL+HR+λ(GL+GR)2]−γ
所以该叶子节点是否要切分,通过上述公式,若gain收益大于0,则就可以继续切分,至于怎么切割,可以对所有样本的 g g g和 h h h进行排序,然后从左到右扫描选择最优的切割点。
2.2 训练
熟悉GBDT的原理后,接下来我们来看下GBDT模型是如何训练的,以及训练完后,我们得到的到底是什么样的模型结构
训练步骤
假设我们用的是均方差损失函数,gbdt模型训练步骤总结如下:
- 第一步(初始值确定):每个样本的初始值模型预测分值为所有样本的平均值: f 0 ( x i ) = 1 n ∑ i = 1 n y i f_0(x_i)=\frac{1}{n}\sum_{i=1}^n y_i f0(xi)=n1∑i=1nyi
- 第二步 (建树第1棵):对每个样本,根据之前的预测结果 y i ^ 0 = f 0 ( x i ) \hat{y_i}^0=f_0(x_i) yi^0=f0(xi)值以及对应的标签值 y i y_i yi,得到目标函数对模型上一步的预测值的一阶导数 g i = 2 ( y i ^ 0 − y i ) g_i=2(\hat{y_i}^0-y_i) gi=2(yi^0−yi)以及二阶导数 h i = 2 h_i=2 hi=2,然后遍历所有特征类型,以及每个特征对应的特征值范围,进行切分后,计算切分前后的Gain增长情况,选择增长最大的切分点,然后继续向下切分节点,直到切分前后差异低于设定的阈值,或者模型的深度,叶子节点数等超过设置的阈值。最后,叶子节点w值计算根据上述公式: w = − G j H j + λ w= -\frac{G_j}{H_j+\lambda} w=−Hj+λGj,其中 G j , H j G_j,H_j Gj,Hj是落入到这个叶子节点的所有样本的一阶导数之和,以及二阶导数之和,这样就可以计算一个样本,根据规则分割,落入到哪个叶子节点的函数 f 1 ( x i ) f_1(x_i) f1(xi)。
- 第三步 (建树第2棵):对所有样本,经过前面的所有树,根据切分条件,落入到每棵树的叶子节点的分值累积之和为当前样本预测的分值: y i ^ 1 = f 0 ( x i ) + f 1 ( x i ) \hat{y_i}^1=f_0(x_i)+f_1(x_i) yi^1=f0(xi)+f1(xi), 按照第一棵建树规则过程,对于第二棵树的构建,然后计算每个叶子节点的分值 f 2 ( x i ) f_2(x_i) f2(xi)
- 第四步 (建树第3棵):所有样本经过前面构建好的树,根据条件到达叶子节点,则此时的样本的预测结果值为: y i ^ 2 = f 0 ( x i ) + f 1 ( x i ) + f 2 ( x i ) \hat{y_i}^2 = f_0(x_i) + f_1(x_i) + f_2(x_i) yi^2=f0(xi)+f1(xi)+f2(xi),根据最新结果,然后计算每个样本的 g i , h i g_i,h_i gi,hi,选择增益最大的gain作为切分点。
- …
- 直到建树数量满足设置的阈值
模型结构
训练完后,就得到了N棵树,每一棵树的结构本质上是一连串的分段规则组成,根据输入样本的特征满足情况走树的不同分支,最后落入到树的某个叶子节点,其中落入到叶子节点的权重值就是这个样本在当前这课树的预测分值。
2.3 预测
当训练好了模型以后,预测的过程就简单了,假设有T棵树,则最终的模型预测结果为这个样本落入到每棵树的叶子节点分值之和,用公式表达如下:
y i ^ = ∑ j = 0 T f j ( x i ) \hat{y_i} = \sum_{j=0}^Tf_j(x_i) yi^=j=0∑Tfj(xi)
3 训练框架
接下来介绍优化Gradient Boosting算法的几种分布式训练框架,这些框架支持分布式训练,树的调优,缺失值处理,正则化等避免过拟合问题。
3.1 XGBoost
XGBoost: A Scalable Tree Boosting System 是由2014年5月,由DMLC开发出来的,目前是比较受欢迎,高效分布式训练Gradient Boosted Trees算法框架,包含的详细资料可以参考官方文档: 官网文档。
3.2 LightGBM
LightGBM: A Highly Efficient Gradient Boosting Decision Tree 是由微软团队于2017年1月针对XGBoost框架存在的一些问题,设计出的更加高效的学习框架,主要基于梯度单边采样GOSS((Gradient Based One Side Sampling)以及互斥特征合并EFB(Exclusive Feature Bundling)来加快模型的学习效率,详细资料可以参考官方文档 官网文档。下面提供的是一个简单的在基于lightgbm做rank排序代码:
import lightgbm as lgb
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
import seaborn as sns
import matplotlib.pyplot as plt
import seaborn as sns
import shap
import graphviz
#读取数据,显示前面20行
df = pd.read_csv('train.csv')
df.head(20)
#显示数据列名称
df.columns
#抽取x,y对应的字段
X = df.drop(['label','query','term'], axis=1)
y = df.label
group=np.loadtxt('./group.txt')
#训练数据
train_data = lgb.Dataset(X, label=y, group=group,free_raw_data=False)
#参数定义
params = {
'task' : 'train',
'boosting_type': 'gbdt',
'objective': 'lambdarank',
'num_iterations': 200,
'learning_rate':0.1,
'num_leaves': 31,
'tree_learner': 'serial',
'max_depth': 6,
'metric': 'ndcg',
'metric_freq': 10,
'train_metric':True,
'ndcg_at':[2],
'max_bin':255,
'max_position': 20,
'verbose':0
}
#指明类别特征
categorical_feature=[0,1]
#训练
gbm=lgb.train(params,
train_data,
valid_sets=train_data,
categorical_feature=categorical_feature)
#模型保存
gbm.save_model('model_large.md')
#预测
bst = lgb.Booster(model_file='model_large.md')
df_test = pd.read_csv('test.csv')
y_pred = bst.predict(test)
#feature重要度
fea_imp = pd.DataFrame({'imp': bst.feature_importance(importance_type='split'), 'col': X.columns})
fea_imp = fea_imp.sort_values(['imp', 'col'], ascending=[True, False]).iloc[-30:]
fea_imp.plot(kind='barh', x='col', y='imp', figsize=(10, 7), legend=None)
plt.title('Feature Importance')
plt.ylabel('Features')
plt.xlabel('Importance');
# 基于shap特征分析
explainer = shap.TreeExplainer(bst)
shap_values = explainer.shap_values(X)
shap.summary_plot(shap_values, X, plot_type="bar")
shap.summary_plot(shap_values, X)
shap.dependence_plot('entropy', shap_values, X, interaction_index=None, show=True)
3.3 CatBoost
CatBoost: unbiased boosting with categorical features 是由2017年4月,俄罗斯搜索巨头Yandex开发出的优化xgboost的一个框架,该框架最大的优势就是能够处理categorical features,相比LightGBM,不需要对分类特征进行label encoding,方便用户的快速操作。详细的官方网址:官网网址,下面是三者的详细对比图:
训练loss对比:
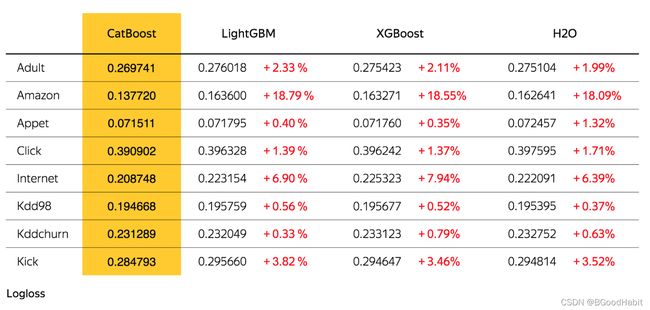
模型性能对比:左边是CPU机器,右边是GPU机器

可以看出Catboost相比XGBoost和LightGBM在指标收敛效果有一定提升的条件下,在模型性能上有较大的提升。如下是基于Catboost进行训练的简单代码式例:
import numpy as np
import pandas as pd
import os
from sklearn.metrics import mean_squared_error
from sklearn import feature_selection
from catboost import CatBoostClassifier
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
import seaborn as sns
import matplotlib.pyplot as plt
#读取数据
df = pd.read_csv('data.csv')
df.head()
#显示特征名
df.columns
#显示某个特征名的数据情况
pd.set_option('display.float_format', '{:.2f}'.format)
df.f_ctf.describe()
#特征分布显示
plt.figure(figsize = (10, 4))
plt.scatter(range(df.shape[0]), np.sort(df['f_ctf'].values))
plt.xlabel('index')
plt.ylabel('f_ctf')
plt.title("f_ctf Distribution")
plt.show();
#训练样本划分
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.20, random_state=42)
#指明categorical特征
categorical_features_indices=[1,2,3]
#模型训练
model = CatBoostClassifier(iterations=700,
learning_rate=0.01,
depth=15,
eval_metric='AUC',
random_seed = 42,
bagging_temperature = 0.2,
od_type='Iter',
metric_period = 75,
loss_function='Logloss',
od_wait=100)
model.fit(X_train, y_train,
eval_set=(X_valid, y_valid),
cat_features=categorical_features_indices,
use_best_model=True,
plot=True)
#特征重要度显示
fea_imp = pd.DataFrame({'imp': model.feature_importances_, 'col': X.columns})
fea_imp = fea_imp.sort_values(['imp', 'col'], ascending=[True,False]).iloc[-30:]
fea_imp.plot(kind='barh', x='col', y='imp', figsize=(10, 7), legend=None)
plt.title('CatBoost - Feature Importance')
plt.ylabel('Features')
plt.xlabel('Importance');
3.4 NGBoost
NGBoost: Natural Gradient Boosting for Probabilistic Prediction 是一个比较新的训练Gradient Boosting算法框架。于2019年10月由斯坦福吴恩达团队公开发表。github代码记录在:NGBoost Github,核心点在于它使用自然梯度提升,一种用于概率预测的模块化提升算法。该算法由基学习器、参数概率分布和评分规则组成。
4 树模型与深度模型结合
树模型有较强的解释性和稳定性,但是缺陷就是无语义特征,泛化能力不够强,所以在实际场景中,可以将树模型与深度学习模型结合,比如简单的求个平均可能都有一定提升,这是一个简单试验对比效果,bert比gbdt模型在情感分类任务中有一定提升,但将bert和gbdt结果融合到一起简单求一个平均值,效果最佳,具体可以参考有人做的一个简单对比试验:bert vs catboost
6 参考资料
1 GBDT Youtube Video