win10+python环境yolov5s预训练模型转onnx然后用openvino生成推理加速模型并测试推理
作者:RayChiu_Labloy
版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处
目录
准备pytorch版本的yolo环境
安装OpenVINO
下载yolov5s模型然后转ONNX
用yolo提供的现成的脚本(根目录下)的export.py
yolo.py和export.py的修改
export.py修改onnx的版本号对应你自己的onnx版本
yolo.py修改forward方法
并且在common.py中的 line.42-line.45 和 line.80-line.83 有两个。
中间遇到的问题
转的时候报 No module named 'onnx'
用onnx模型测试
ONNX模型和原pt模型对比
速度上:
大小上
使用工具onnx-simplifier简化ONNX模型
onnx-simplifier安装
简化
结果:
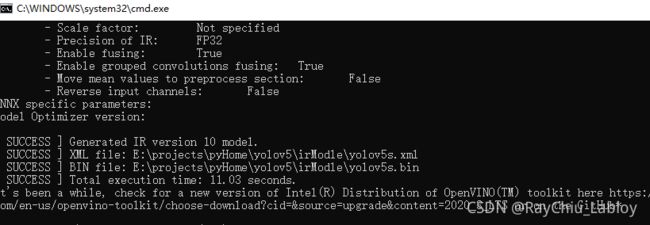
生成IR文件
首先找到要导出的节点:
进入指定目录执行转换脚本mo.py
遇到的问题
python推理xml模型
yolo_openvino_demo.py代码:
准备pytorch版本的yolo环境
时光机:win10搭建pytorch环境跑通pytorch版本的yolov5_RayChiu757374816的博客-CSDN博客
安装OpenVINO
传送门:win10 安装OpenVINO并在tensorflow环境下测试官方demo_RayChiu757374816的博客-CSDN博客
下载yolov5s模型然后转ONNX
用yolo提供的现成的脚本(根目录下)的export.py
Terminal窗口输入命令 python export.py --include=onnx 回车即可导出 ONNX文件,注意加上 “--include=onnx”参数,否则导出多余的东西,其他参数还需要设置你需要转换的模型路径如图:
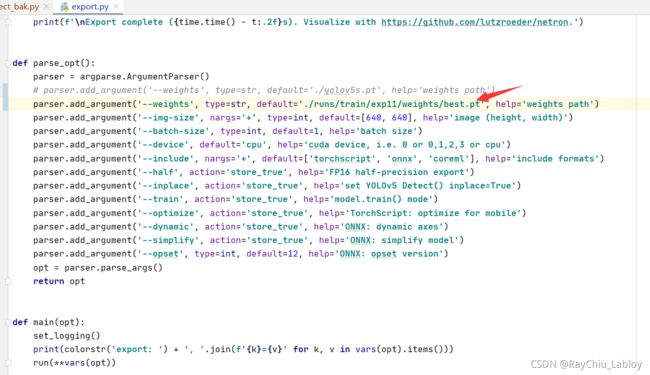
onnx生成路径和--weights路径一直。
yolo.py和export.py的修改
export.py修改onnx的版本号对应你自己的onnx版本
否则会在OpneVINO转IR文件的时候报错,见本文最下边的问题描述
yolo.py修改forward方法
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
c = (y[..., 0:2] * 2. - 0.5 + self.grid[i].to(x[i].device)) * self.stride[i] # xy
d = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
e = y[..., 4:]
f = torch.cat((c, d, e), 4)
z.append(f.view(bs, -1, self.no))
return x if self.training else torch.cat(z, 1)并且在common.py中的 line.42-line.45 和 line.80-line.83 有两个。
# if yolov4
#self.act = Mish() if act else nn.Identity()
# if yolov5
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())# if yolov4
#self.act = Mish()
# if yolov5
self.act = nn.LeakyReLU(0.1, inplace=True)中间遇到的问题
转的时候报 No module named 'onnx'
安装命令
conda install -c conda-forge onnx自动安装依赖:
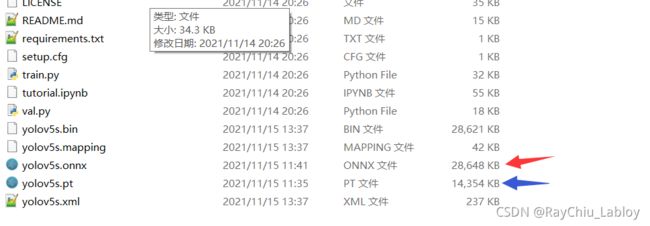
成功生成onnx文件:
用onnx模型测试
安装onnxruntime
pip install onnxruntime测试命令
python detect.py --source ./data/images/bus.jpg --weights=./yolov5s.onnx结果没问题
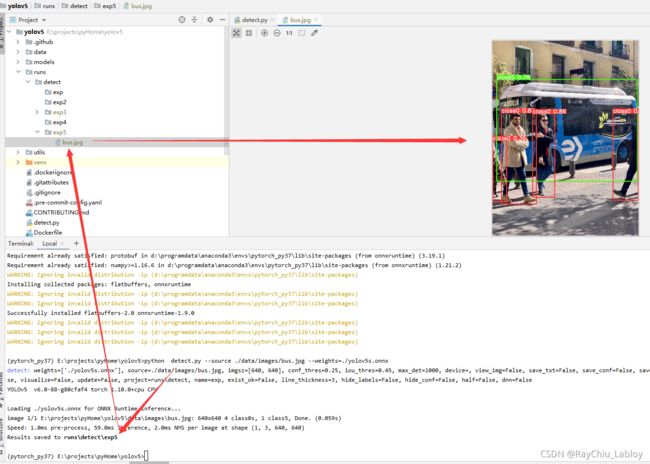
ONNX模型和原pt模型对比
速度上:
原模型和onnx测试官方示例耗时:

onnx模型比元模型快了将近一倍
大小上
我们没有做过多的处理,onnx模型稍微大一些:
使用工具onnx-simplifier简化ONNX模型
onnx-simplifier安装
pip install -i http://pypi.douban.com/simple/ --trusted-host=pypi.douban.com/simple onnx-simplifier简化
python -m onnxsim ./yolov5s.onnx ./yolov5s_sim.onnx结果:
大小没怎么变,速度稍微快了一些

生成IR文件
首先找到要导出的节点:
首先用Netron打开找到yolov5s_sim.onnx的三个transport节点往上找到对应的三个Conv节点,查看节点name。
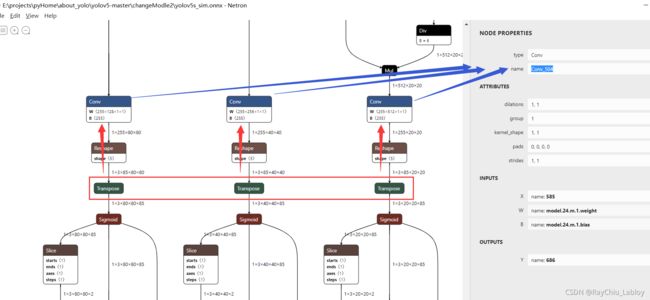
下边的命令里带上 --output Conv_455,Conv_504,Conv_553 这样就指定输出了。
进入指定目录执行转换脚本mo.py
所谓的ir文件就是OpenVINO把模型(例如ONNX格式的)通过mo.py转化生成的文件,会生成两个文件,一个.bin是参数文件,一个是xml文件是描述网络结构的。
打开命令行,进入OpenVINO的mo.py所在目录:
cd C:\Program Files (x86)\IntelSWTools\openvino_2020.4.287\deployment_tools\model_optimizer执行转换命令(记得切换一下pytorch_py37那个conda环境,因为安装了需要的onnx依赖):
python mo.py --input_model E:\projects\pyHome\about_yolo\yolov5-master\changeModle2\yolov5s_sim.onnx -s 255 --reverse_input_channels --output_dir E:\projects\pyHome\about_yolo\yolov5-master\changeModle2 --output Conv_455,Conv_504,Conv_553遇到的问题
问题1:提示我没有安装networkx defusedxml,那么安装
pip install networkx defusedxml然而还是报缺东西,提示我执行install_prerequisites_onnx.bat这个脚本,好吧到我的OpenVINO安装目录执行吧
cd C:\Program Files (x86)\IntelSWTools\openvino_2020.4.287\deployment_tools\model_optimizer\install_prerequisites
install_prerequisites_onnx.bat问题2:后来执行转换命令报 ONNX Resize operation from opset 12 is not supported
看起来是导出的onnx文件配置和自己安装的onnx版本不一致:
默认的是12:
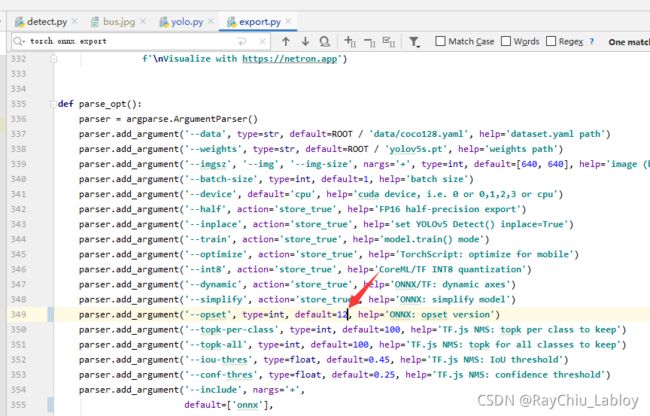
而我安装的是10(conda list查看):
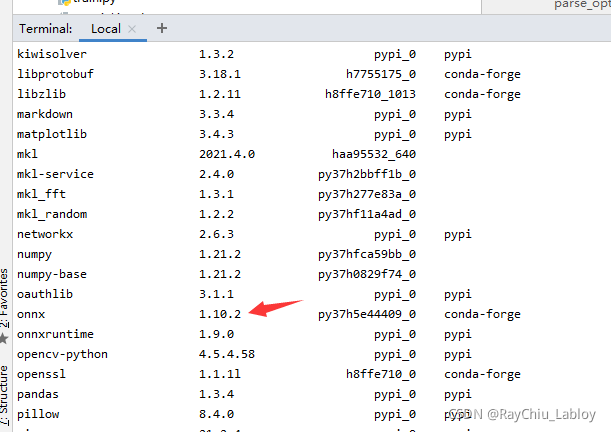
export.py改一下对应自己安装的版本重新导出onnx文件,然后再次转换成功:
问题3:PermissionError: [Errno 13] Permission denied:
这个问题是权限不够,用管理员身份打开cmd命令行窗口再次执行命令就可以了。
python推理xml模型
Python环境中并没有OpenVINO™工具套件,所以我这里需要用pip安装一下OpenVINO™工具套件:
pip install openvino脚本yolo_openvino_demo.py在下边,命令如下:
python yolo_openvino_demo.py -m ./changeModle2/yolov5s_sim.xml -i ./data/images/bus.jpg -at yolov5效果:
yolo_openvino_demo.py代码:
#!/usr/bin/env python
"""
Copyright (C) 2018-2019 Intel Corporation
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
"""
from __future__ import print_function, division
import logging
import os
import sys
from argparse import ArgumentParser, SUPPRESS
from math import exp as exp
from time import time
import numpy as np
import ngraph
import cv2
from openvino.inference_engine import IENetwork, IECore
logging.basicConfig(format="[ %(levelname)s ] %(message)s", level=logging.INFO, stream=sys.stdout)
log = logging.getLogger()
def build_argparser():
parser = ArgumentParser(add_help=False)
args = parser.add_argument_group('Options')
args.add_argument('-h', '--help', action='help', default=SUPPRESS, help='Show this help message and exit.')
args.add_argument("-m", "--model", help="Required. Path to an .xml file with a trained model.",
required=True, type=str)
args.add_argument("-at", "--architecture_type", help='Required. Specify model\' architecture type.',
type=str, required=True, choices=('yolov3', 'yolov4', 'yolov5', 'yolov4-p5', 'yolov4-p6', 'yolov4-p7'))
args.add_argument("-i", "--input", help="Required. Path to an image/video file. (Specify 'cam' to work with "
"camera)", required=True, type=str)
args.add_argument("-l", "--cpu_extension",
help="Optional. Required for CPU custom layers. Absolute path to a shared library with "
"the kernels implementations.", type=str, default=None)
args.add_argument("-d", "--device",
help="Optional. Specify the target device to infer on; CPU, GPU, FPGA, HDDL or MYRIAD is"
" acceptable. The sample will look for a suitable plugin for device specified. "
"Default value is CPU", default="CPU", type=str)
args.add_argument("--labels", help="Optional. Labels mapping file", default=None, type=str)
args.add_argument("-t", "--prob_threshold", help="Optional. Probability threshold for detections filtering",
default=0.5, type=float)
args.add_argument("-iout", "--iou_threshold", help="Optional. Intersection over union threshold for overlapping "
"detections filtering", default=0.4, type=float)
args.add_argument("-ni", "--number_iter", help="Optional. Number of inference iterations", default=1, type=int)
args.add_argument("-pc", "--perf_counts", help="Optional. Report performance counters", default=False,
action="store_true")
args.add_argument("-r", "--raw_output_message", help="Optional. Output inference results raw values showing",
default=False, action="store_true")
args.add_argument("--no_show", help="Optional. Don't show output", action='store_true')
return parser
class YoloParams:
# ------------------------------------------- Extracting layer parameters ------------------------------------------
# Magic numbers are copied from yolo samples
def __init__(self, param, side, yolo_type):
self.coords = 4 if 'coords' not in param else int(param['coords'])
self.classes = 80 if 'classes' not in param else int(param['classes'])
self.side = side
if yolo_type == 'yolov4':
self.num = 3
self.anchors = [12.0,16.0, 19.0,36.0, 40.0,28.0, 36.0,75.0, 76.0,55.0, 72.0,146.0, 142.0,110.0, 192.0,243.0,
459.0,401.0]
elif yolo_type == 'yolov4-p5':
self.num = 4
self.anchors = [13.0,17.0, 31.0,25.0, 24.0,51.0, 61.0,45.0, 48.0,102.0, 119.0,96.0, 97.0,189.0, 217.0,184.0,
171.0,384.0, 324.0,451.0, 616.0,618.0, 800.0,800.0]
elif yolo_type == 'yolov4-p6':
self.num = 4
self.anchors = [13.0,17.0, 31.0,25.0, 24.0,51.0, 61.0,45.0, 61.0,45.0, 48.0,102.0, 119.0,96.0, 97.0,189.0,
97.0,189.0, 217.0,184.0, 171.0,384.0, 324.0,451.0, 324.0,451.0, 545.0,357.0, 616.0,618.0, 1024.0,1024.0]
elif yolo_type == 'yolov4-p7':
self.num = 5
self.anchors = [13.0,17.0, 22.0,25.0, 27.0,66.0, 55.0,41.0, 57.0,88.0, 112.0,69.0, 69.0,177.0, 136.0,138.0,
136.0,138.0, 287.0,114.0, 134.0,275.0, 268.0,248.0, 268.0,248.0, 232.0,504.0, 445.0,416.0, 640.0,640.0,
812.0,393.0, 477.0,808.0, 1070.0,908.0, 1408.0,1408.0]
else:
self.num = 3
self.anchors = [10.0, 13.0, 16.0, 30.0, 33.0, 23.0, 30.0, 61.0, 62.0, 45.0, 59.0, 119.0, 116.0, 90.0, 156.0,
198.0, 373.0, 326.0]
def log_params(self):
params_to_print = {'classes': self.classes, 'num': self.num, 'coords': self.coords, 'anchors': self.anchors}
[log.info(" {:8}: {}".format(param_name, param)) for param_name, param in params_to_print.items()]
def letterbox(img, size=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True):
# Resize image to a 32-pixel-multiple rectangle https://github.com/ultralytics/yolov3/issues/232
shape = img.shape[:2] # current shape [height, width]
w, h = size
# Scale ratio (new / old)
r = min(h / shape[0], w / shape[1])
if not scaleup: # only scale down, do not scale up (for better test mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = w - new_unpad[0], h - new_unpad[1] # wh padding
if auto: # minimum rectangle
dw, dh = np.mod(dw, 64), np.mod(dh, 64) # wh padding
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (w, h)
ratio = w / shape[1], h / shape[0] # width, height ratios
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
top2, bottom2, left2, right2 = 0, 0, 0, 0
if img.shape[0] != h:
top2 = (h - img.shape[0])//2
bottom2 = top2
img = cv2.copyMakeBorder(img, top2, bottom2, left2, right2, cv2.BORDER_CONSTANT, value=color) # add border
elif img.shape[1] != w:
left2 = (w - img.shape[1])//2
right2 = left2
img = cv2.copyMakeBorder(img, top2, bottom2, left2, right2, cv2.BORDER_CONSTANT, value=color) # add border
return img
def scale_bbox(x, y, height, width, class_id, confidence, im_h, im_w, resized_im_h=640, resized_im_w=640):
gain = min(resized_im_w / im_w, resized_im_h / im_h) # gain = old / new
pad = (resized_im_w - im_w * gain) / 2, (resized_im_h - im_h * gain) / 2 # wh padding
x = int((x - pad[0])/gain)
y = int((y - pad[1])/gain)
w = int(width/gain)
h = int(height/gain)
xmin = max(0, int(x - w / 2))
ymin = max(0, int(y - h / 2))
xmax = min(im_w, int(xmin + w))
ymax = min(im_h, int(ymin + h))
# Method item() used here to convert NumPy types to native types for compatibility with functions, which don't
# support Numpy types (e.g., cv2.rectangle doesn't support int64 in color parameter)
return dict(xmin=xmin, xmax=xmax, ymin=ymin, ymax=ymax, class_id=class_id.item(), confidence=confidence.item())
def entry_index(side, coord, classes, location, entry):
side_power_2 = side ** 2
n = location // side_power_2
loc = location % side_power_2
return int(side_power_2 * (n * (coord + classes + 1) + entry) + loc)
def parse_yolo_region(blob, resized_image_shape, original_im_shape, params, threshold, yolo_type):
# ------------------------------------------ Validating output parameters ------------------------------------------
out_blob_n, out_blob_c, out_blob_h, out_blob_w = blob.shape
predictions = 1.0/(1.0+np.exp(-blob))
assert out_blob_w == out_blob_h, "Invalid size of output blob. It sould be in NCHW layout and height should " \
"be equal to width. Current height = {}, current width = {}" \
"".format(out_blob_h, out_blob_w)
# ------------------------------------------ Extracting layer parameters -------------------------------------------
orig_im_h, orig_im_w = original_im_shape
resized_image_h, resized_image_w = resized_image_shape
objects = list()
side_square = params.side[1] * params.side[0]
# ------------------------------------------- Parsing YOLO Region output -------------------------------------------
bbox_size = int(out_blob_c/params.num) #4+1+num_classes
#print('bbox_size = ' + str(bbox_size))
#print('bbox_size = ' + str(bbox_size))
for row, col, n in np.ndindex(params.side[0], params.side[1], params.num):
bbox = predictions[0, n*bbox_size:(n+1)*bbox_size, row, col]
x, y, width, height, object_probability = bbox[:5]
class_probabilities = bbox[5:]
if object_probability < threshold:
continue
#print('resized_image_w = ' + str(resized_image_w))
#print('out_blob_w = ' + str(out_blob_w))
x = (2*x - 0.5 + col)*(resized_image_w/out_blob_w)
y = (2*y - 0.5 + row)*(resized_image_h/out_blob_h)
if int(resized_image_w/out_blob_w) == 8 & int(resized_image_h/out_blob_h) == 8: #80x80,
idx = 0
elif int(resized_image_w/out_blob_w) == 16 & int(resized_image_h/out_blob_h) == 16: #40x40
idx = 1
elif int(resized_image_w/out_blob_w) == 32 & int(resized_image_h/out_blob_h) == 32: # 20x20
idx = 2
elif int(resized_image_w/out_blob_w) == 64 & int(resized_image_h/out_blob_h) == 64: # 20x20
idx = 3
elif int(resized_image_w/out_blob_w) == 128 & int(resized_image_h/out_blob_h) == 128: # 20x20
idx = 4
if yolo_type == 'yolov4-p5' or yolo_type == 'yolov4-p6' or yolo_type == 'yolov4-p7':
width = (2*width)**2* params.anchors[idx * 8 + 2 * n]
height = (2*height)**2 * params.anchors[idx * 8 + 2 * n + 1]
else:
width = (2*width)**2* params.anchors[idx * 6 + 2 * n]
height = (2*height)**2 * params.anchors[idx * 6 + 2 * n + 1]
class_id = np.argmax(class_probabilities * object_probability)
confidence = class_probabilities[class_id] * object_probability
objects.append(scale_bbox(x=x, y=y, height=height, width=width, class_id=class_id, confidence=confidence,
im_h=orig_im_h, im_w=orig_im_w, resized_im_h=resized_image_h, resized_im_w=resized_image_w))
return objects
def intersection_over_union(box_1, box_2):
width_of_overlap_area = min(box_1['xmax'], box_2['xmax']) - max(box_1['xmin'], box_2['xmin'])
height_of_overlap_area = min(box_1['ymax'], box_2['ymax']) - max(box_1['ymin'], box_2['ymin'])
if width_of_overlap_area < 0 or height_of_overlap_area < 0:
area_of_overlap = 0
else:
area_of_overlap = width_of_overlap_area * height_of_overlap_area
box_1_area = (box_1['ymax'] - box_1['ymin']) * (box_1['xmax'] - box_1['xmin'])
box_2_area = (box_2['ymax'] - box_2['ymin']) * (box_2['xmax'] - box_2['xmin'])
area_of_union = box_1_area + box_2_area - area_of_overlap
if area_of_union == 0:
return 0
return area_of_overlap / area_of_union
def main():
args = build_argparser().parse_args()
model_xml = args.model
model_bin = os.path.splitext(model_xml)[0] + ".bin"
# ------------- 1. Plugin initialization for specified device and load extensions library if specified -------------
log.info("Creating Inference Engine...")
ie = IECore()
if args.cpu_extension and 'CPU' in args.device:
ie.add_extension(args.cpu_extension, "CPU")
# -------------------- 2. Reading the IR generated by the Model Optimizer (.xml and .bin files) --------------------
log.info("Loading network files:\n\t{}\n\t{}".format(model_xml, model_bin))
net = IENetwork(model=model_xml, weights=model_bin)
# ---------------------------------- 3. Load CPU extension for support specific layer ------------------------------
#if "CPU" in args.device:
# supported_layers = ie.query_network(net, "CPU")
# not_supported_layers = [l for l in net.layers.keys() if l not in supported_layers]
# if len(not_supported_layers) != 0:
# log.error("Following layers are not supported by the plugin for specified device {}:\n {}".
# format(args.device, ', '.join(not_supported_layers)))
# log.error("Please try to specify cpu extensions library path in sample's command line parameters using -l "
# "or --cpu_extension command line argument")
# sys.exit(1)
#
#assert len(net.inputs.keys()) == 1, "Sample supports only YOLO V3 based single input topologies"
# ---------------------------------------------- 4. Preparing inputs -----------------------------------------------
log.info("Preparing inputs")
input_blob = next(iter(net.inputs))
# Defaulf batch_size is 1
net.batch_size = 1
# Read and pre-process input images
n, c, h, w = net.inputs[input_blob].shape
ng_func = ngraph.function_from_cnn(net)
yolo_layer_params = {}
for node in ng_func.get_ordered_ops():
layer_name = node.get_friendly_name()
if layer_name not in net.outputs:
continue
shape = list(node.inputs()[0].get_source_output().get_node().shape)
yolo_params = YoloParams(node._get_attributes(), shape[2:4], args.architecture_type)
yolo_layer_params[layer_name] = (shape, yolo_params)
if args.labels:
with open(args.labels, 'r') as f:
labels_map = [x.strip() for x in f]
else:
labels_map = None
input_stream = 0 if args.input == "cam" else args.input
is_async_mode = True
cap = cv2.VideoCapture(input_stream)
number_input_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
number_input_frames = 1 if number_input_frames != -1 and number_input_frames < 0 else number_input_frames
wait_key_code = 1
# Number of frames in picture is 1 and this will be read in cycle. Sync mode is default value for this case
if number_input_frames != 1:
ret, frame = cap.read()
else:
is_async_mode = False
wait_key_code = 0
# ----------------------------------------- 5. Loading model to the plugin -----------------------------------------
log.info("Loading model to the plugin")
exec_net = ie.load_network(network=net, num_requests=2, device_name=args.device)
cur_request_id = 0
next_request_id = 1
render_time = 0
parsing_time = 0
# ----------------------------------------------- 6. Doing inference -----------------------------------------------
log.info("Starting inference...")
print("To close the application, press 'CTRL+C' here or switch to the output window and press ESC key")
print("To switch between sync/async modes, press TAB key in the output window")
while cap.isOpened():
# Here is the first asynchronous point: in the Async mode, we capture frame to populate the NEXT infer request
# in the regular mode, we capture frame to the CURRENT infer request
if is_async_mode:
ret, next_frame = cap.read()
else:
ret, frame = cap.read()
if not ret:
break
if is_async_mode:
request_id = next_request_id
in_frame = letterbox(frame, (w, h))
else:
request_id = cur_request_id
in_frame = letterbox(frame, (w, h))
# resize input_frame to network size
in_frame = in_frame.transpose((2, 0, 1)) # Change data layout from HWC to CHW
in_frame = in_frame.reshape((n, c, h, w))
# Start inference
start_time = time()
exec_net.start_async(request_id=request_id, inputs={input_blob: in_frame})
# Collecting object detection results
objects = list()
if exec_net.requests[cur_request_id].wait(-1) == 0:
det_time = time() - start_time
output = exec_net.requests[cur_request_id].outputs
start_time = time()
for layer_name, out_blob in output.items():
#out_blob = out_blob.reshape(net.layers[layer_name].out_data[0].shape)
layer_params = yolo_layer_params[layer_name]#YoloParams(net.layers[layer_name].params, out_blob.shape[2])
out_blob.shape = layer_params[0]
#log.info("Layer {} parameters: ".format(layer_name))
#layer_params.log_params()
objects += parse_yolo_region(out_blob, in_frame.shape[2:],
#in_frame.shape[2:], layer_params,
frame.shape[:-1], layer_params[1],
args.prob_threshold, args.architecture_type)
parsing_time = time() - start_time
# Filtering overlapping boxes with respect to the --iou_threshold CLI parameter
objects = sorted(objects, key=lambda obj : obj['confidence'], reverse=True)
for i in range(len(objects)):
if objects[i]['confidence'] == 0:
continue
for j in range(i + 1, len(objects)):
if objects[i]['class_id'] != objects[j]['class_id']: # Only compare bounding box with same class id
continue
if intersection_over_union(objects[i], objects[j]) > args.iou_threshold:
objects[j]['confidence'] = 0
# Drawing objects with respect to the --prob_threshold CLI parameter
objects = [obj for obj in objects if obj['confidence'] >= args.prob_threshold]
if len(objects) and args.raw_output_message:
log.info("\nDetected boxes for batch {}:".format(1))
log.info(" Class ID | Confidence | XMIN | YMIN | XMAX | YMAX | COLOR ")
origin_im_size = frame.shape[:-1]
for obj in objects:
# Validation bbox of detected object
if obj['xmax'] > origin_im_size[1] or obj['ymax'] > origin_im_size[0] or obj['xmin'] < 0 or obj['ymin'] < 0:
continue
color = (int(min(obj['class_id'] * 12.5, 255)),
min(obj['class_id'] * 7, 255), min(obj['class_id'] * 5, 255))
det_label = labels_map[obj['class_id']] if labels_map and len(labels_map) >= obj['class_id'] else \
str(obj['class_id'])
if args.raw_output_message:
log.info(
"{:^9} | {:10f} | {:4} | {:4} | {:4} | {:4} | {} ".format(det_label, obj['confidence'], obj['xmin'],
obj['ymin'], obj['xmax'], obj['ymax'],
color))
cv2.rectangle(frame, (obj['xmin'], obj['ymin']), (obj['xmax'], obj['ymax']), color, 2)
cv2.putText(frame,
"#" + det_label + ' ' + str(round(obj['confidence'] * 100, 1)) + ' %',
(obj['xmin'], obj['ymin'] - 7), cv2.FONT_HERSHEY_COMPLEX, 0.6, color, 1)
# Draw performance stats over frame
inf_time_message = "Inference time: N\A for async mode" if is_async_mode else \
"Inference time: {:.3f} ms".format(det_time * 1e3)
render_time_message = "OpenCV rendering time: {:.3f} ms".format(render_time * 1e3)
async_mode_message = "Async mode is on. Processing request {}".format(cur_request_id) if is_async_mode else \
"Async mode is off. Processing request {}".format(cur_request_id)
parsing_message = "YOLO parsing time is {:.3f} ms".format(parsing_time * 1e3)
cv2.putText(frame, inf_time_message, (15, 15), cv2.FONT_HERSHEY_COMPLEX, 0.5, (200, 10, 10), 1)
cv2.putText(frame, render_time_message, (15, 45), cv2.FONT_HERSHEY_COMPLEX, 0.5, (10, 10, 200), 1)
cv2.putText(frame, async_mode_message, (10, int(origin_im_size[0] - 20)), cv2.FONT_HERSHEY_COMPLEX, 0.5,
(10, 10, 200), 1)
cv2.putText(frame, parsing_message, (15, 30), cv2.FONT_HERSHEY_COMPLEX, 0.5, (10, 10, 200), 1)
start_time = time()
if not args.no_show:
cv2.imshow("DetectionResults", frame)
render_time = time() - start_time
if is_async_mode:
cur_request_id, next_request_id = next_request_id, cur_request_id
frame = next_frame
if not args.no_show:
key = cv2.waitKey(wait_key_code)
# ESC key
if key == 27:
break
# Tab key
if key == 9:
exec_net.requests[cur_request_id].wait()
is_async_mode = not is_async_mode
log.info("Switched to {} mode".format("async" if is_async_mode else "sync"))
cv2.destroyAllWindows()
if __name__ == '__main__':
sys.exit(main() or 0)
参考:【深入YoloV5(开源)】基于YoloV5的模型优化技术与使用OpenVINO推理实现_cv君的博客-CSDN博客
OpenVINO部署Yolov5_洪流之源-CSDN博客_openvino yolov5
u版YOLOv5目标检测openvino实现_缘分天空的专栏-CSDN博客
当YOLOv5遇见OpenVINO!_阿木寺的博客-CSDN博客
GitHub - Chen-MingChang/pytorch_YOLO_OpenVINO_demo
【如果对您有帮助,交个朋友给个一键三连吧,您的肯定是我博客高质量维护的动力!!!】