sklearn.model_selection.train_test_split(random_state=42) 与 np.random.seed(42)的联系和原理详解
np.random.seed()
np.random.seed() 利用随机数种子,指定了一个随机数生成的起始位置,使得每次生成的随机数相同。
问题:
- np.random.seed()是否一直有效
- np.random.seed(Argument)的参数作用?
Code 1
import numpy as np
if __name__ == '__main__':
i = 0
while (i < 6):
if (i < 3):
np.random.seed(0)
print(np.random.randn(1, 5))
else:
print(np.random.randn(1, 5))
pass
i += 1
print("-------------------")
i = 0
while (i < 2):
print(np.random.randn(1, 5))
i += 1
print(np.random.randn(2, 5))
print("---------重置----------")
np.random.seed(0)
i = 0
while (i < 8):
print(np.random.randn(1, 5))
可以看出,np.random.seed()对后面的随机数一直有效。
两次利用随机数种子后,即便是跳出循环后,生成随机数的结果依然是相同的。第一次跳出while循环后,进入第二个while循环,得到的两个随机数组确实和加了随机数种子不一样。但是,后面的加了随机数种子的,八次循环中的结果和前面的结果是一样的。说明,随机数种子对后面的结果一直有影响。同时,加了随机数种子以后,后面的随机数组都是按一定的顺序生成的。
Code 2 : 随机数种子参数的作用
import numpy as np
if __name__ == '__main__':
i = 0
np.random.seed(0)
while (i < 3):
print(np.random.randn(1, 5))
i += 1
i = 0
print("---------------------")
np.random.seed(1)
i = 0
while (i < 3):
print(np.random.randn(1, 5))
i += 1
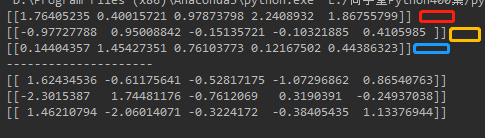
当随机数种子参数为0和1时,生成的随机数结果相同。说明该参数指定了一个随机数生成的起始位置。每个参数对应一个位置。并且在该参数确定后,其后面的随机数的生成顺序也就确定了。
所以,随机数种子的参数怎么选择?这个参数只是确定一下随机数的起始位置,可随意分配。
train_test_split
在讲解sklearn.model_selction.train_test_split之前,我们可以自己制作一个类似的函数:
import numpy as np
# 自己建的类似函数
def split_train_test(data, test_ratio, random_state=0):
np.random.seed(random_state)
shuffled_indices = np.random.permutation(len(data))
test_set_size = int(len(data) * test_ratio)
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices], data.iloc[test_indices]
train_set, test_set = split_train_test(housing, 0.2, 42)
print(len(train_set), "train +", len(test_set), "test")
在调用 np.random.permutation() 之前,设置随机数生成器的种子(比如 np.random.seed(42) ), 以产生总是相同的洗牌指数(shuffled indices)。
Scikit-Learn 提供了一些函数,可以用多种方式将数据集分割成多个子集。最简单的函数
是 train_test_split ,它的作用和之前的函数 split_train_test 很像,并带有其它一些功能。首先,它有一个 random_state 参数,可以设定前面讲过的随机生成器种子;第二,你可以将种子传递给多个行数相同的数据集,可以在相同的索引上分割数据集(这个功能非常有用,比如你的标签值是放在另一个 DataFrame里的):
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
参考:
- np.random.seed() 的使用详解
- 《Hands-on Machine Learning with Scikit-Learn and TensorFlow》