何凯明新作MAE 学习笔记
【MAE与之前AI和CV领域最新工作的关系】
学习MAE视频【李沐】
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., & Girshick, R. (2021). Masked autoencoders are scalable vision learners. arXiv preprint arXiv:2111.06377.
【Transformer】
- Transforme纯注意力(attention)机制的编码器和解码器。
【BERT】
- BERT使用完形填空的自监督的训练机制,使用了Transformer的编码器。
- 将Transformer拓展到更一般的NLP任务
【ViT】
- ViT是Transformer在CV上的应用。
- 证明了数据量足够大的时候,Transformer精度要高于RNN/CNN。
【MAE】
- MAE是BERT在CV上的应用。
【MAE】Title
Masked Autoencoders 带掩码的自编码器 是可扩展的视觉学习器 scalable vision learners
【MAE】Abstract
MAE:Masked AutoEncoders
- MAE虽然自称是一个自编码器(auto-encoder),但是也包含了编码器和解码器。MAE的编码器只关注可见的patches,节省计算时间。
- 通过随机盖住图像中大量的块(75%),迫使模型学习更好的表征,重构缺失的像素
- MAE 使用小数据集 ImageNet-1K 100w 图片,self-supervise达到的效果很好
- MAE主要用来做迁移学习,证明在别的任务上表现很好。
【MAE】图1 MAE Architecture
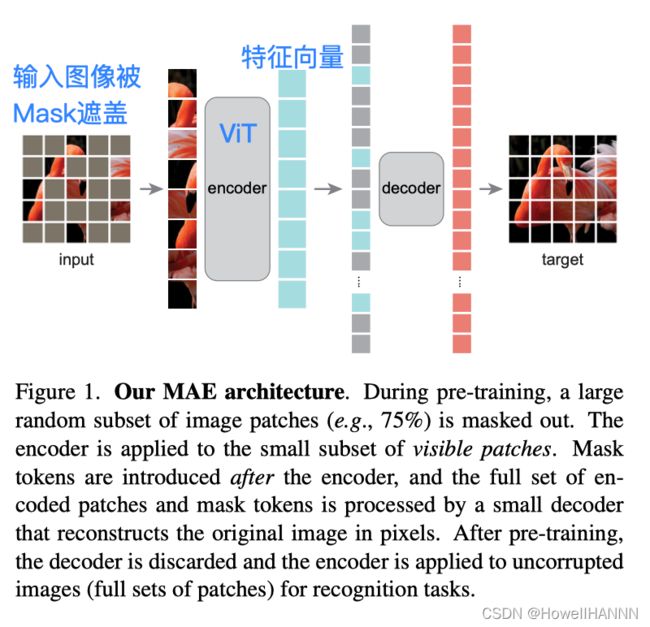
5. encoder的计算量要大于decoder:计算量主要来自于encoder,对图片像素进行编码。
6. 预训练才同时需要encoder和decoder。
7. 用 MAE 做一个 CV 的任务,只需要用编码器。一张图片进来,不需要做mask,直接切成 patches 格子块,然后得到所有 patches 的特征表示,当成是这张图片的特征表达,用来做 CV 的任务。
【MAE】 在数据集上的测试效果
- 图2 ImageNet验证集的效果
P.S. MAE不一定对所有的数据效果都很好,这里放的可能是比较好的结果。
- 图3 COCO验证集的效果

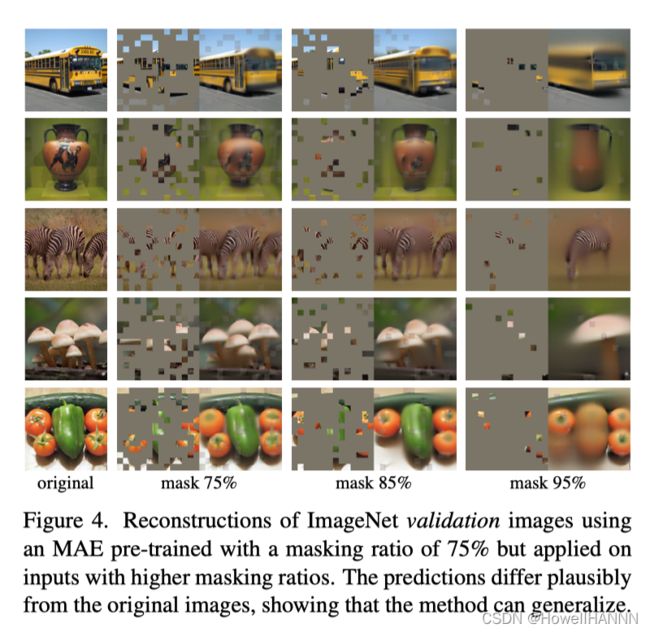
- 图4 遮盖不同比例的区域时还原效果的对比
【MAE】 Discussion and Conclusion
- 【MAE媲美有标号学习的效果】NLP领域,self-supervised已经有很多的应用,但在CV 里有标号的预训练数据是主流。 MAE在 ImageNet数据集上,通过自编码器学习到可以媲美有标号的结果。
- 【图像和语言的差别】
- a word in a sentence:一个词是语义单元,包含较多语义信息。
- a patch in an image:一定的语义信息,但不是一个语义的 segment。一个 patch 并不含有一个特定的物体,可能是多个物体的一小块 or 一个物体重叠的一块。
- 即使图片和语言的 masked 的单元包含语义信息不同,MAE or Transformer 可以学到一个隐藏的比较好的语义表达。
- 【基于MAE的拓展性工作可能会出现的问题】
- MAE基于图像本身信息学习,如果图像信息中包含bias,会产生负面影响。
- MAE是生成模型,生成原始的像素,有误导人们的可能。
【MAE】 Introduction
what makes masked autoencoding different between vision and language?
- CV主要适用CNN,卷积窗口不容易将mask放进去。卷积窗口扫过来、扫过去时,无法区分边界,无法保持 mask 的特殊性,无法拎出来 mask;最后从掩码信息很难还原出来
- 语言和图像的信息密度不同。
- NLP 的一个词是一个语义的实体,一个词在字典里有很长的解释;一句话去掉几个词,任务很难(BERT 的mask 比例不能过高)
- CV 随机去掉很高比例的块,极大降低图片的冗余性 这一块的周边块都被去掉了,这一块和很远的块的关系不那么冗余 nontrivial 任务,使模型去看 一张图片的全局信息,而不仅关注局部
- auto-encoder的decoder:CV 还原图片的原始像素(低层次的表示);NLP 还原句子里的词(语义层次更高)。图片分类、目标检测的 decoder:一个全连接层;语义分割(像素级别的输出):一个全连接层不够,很有可能使用一个转置的卷积神经网络、来做一个比较大解码器。
【MAE 的想法】
- 随机遮住大量的块,然后去重构这些被遮住的像素信息;
- 使用一个非对称的编码器和解码器的机制。编码器只看可见的patches,可以减少计算成本。
【MAE 的优点】
- MAE预训练,只使用 ImageNet-1K 100w 无标号数据,ViT-Large/-Huge 达到 ViT 需要 100倍于
- ImageNet-1K 的数据 的效果。 迁移学习效果也很好,预训练的模型在目标检测、实例分割、语义分割的效果都很好。
【MAE】 Related Work
- 带掩码的语言模型:BERT, GPT
- auto-encoder在 CV 的应用
- MAE 也是一种形式的带去噪的auto-encoder
- masked patch 在这一个图片块里面加了很多噪声和传统的 DAE(Denoising autoencoder) 是很不一样的
- MAE 基于 ViT、transformer 架构
- 带mask的auto-encoder在 CV 的应用
- iGPT,GPT 在 image 的应用
- ViT 最后一段,怎么用 BERT 方式训练模型
- BEiT,BERT 在 image 上的应用
- 给每一个 patch 离散的标号,更像 BERT
- MAE 直接重构 原始的像素信息
- self-supervised learning
- 最近很火的 contrastive learning,使用数据增强
- MAE 不需要数据增强
【MAE】 Approach
【三个问题】
本节回答三个问题:
- 解码器是怎么回事?
- 还原像素信息是怎么实现的?
- 随机采样是怎么实现的?
【Masking】
- 【mask如何工作?】和 ViT 的一样图片 patches 化, i.e., 一张图片 九宫格分割,3 * 3,每一格 代表一个
patch,作为一个词 token - 【random sampling】随机均匀采样块保留, 剩余块用 mask 掩码盖住。
【MAE encoder】
- ViT, 没有任何改动
- 只处理可见的patches(unmasked)
- encoder处理可见patches的details:
- 和 ViT 一样:
每一个 patch 块拿出来,做一个线性投影,加入位置信息 -->作为一个 token进入encoder。 - 和 ViT 不一样:
masked 块不进入 MAE 编码器,减少计算量。
- 和 ViT 一样:
【MAE decoder】
- 【unmasked patches】通过encoder->潜表示。
- 【masked patches】->表示为一个通过学习得到的共享向量。
- 【decoder】是另一个Transformer,要加入位置信息(否则,不知道是哪个mask)。
- 【decoder】主要对预训练使用,其他计算机任务只需要使用encoder。
- 【计算开销】是encoder的1/10不到。
【Reconstruction target】
decoder的最后一层: a linear projection
- 一个 patch 是 16 * 16 像素的话,线性层会投影到长为 256 的维度
- 再 reshape(16, 16), 还原原始像素信息
- 【Loss function】MSE
- 【Normalization】对要预测的像素只做一次normalization,i.e.使每一个块里面的像素均值变0,方差变1,数值上更稳定
【Simple implementation】
- 对每一个输入 patch 生成 a token:一个一个 patch 的线性投影 + 位置信息
- 随机采样:randomly shuffle 随机打断序列,把最后一块拿掉。
- 从头部均匀的、没有重置的样本采样
- 25% 意味着 随机 shuffle, 只保留前 25%
- 解码时:append 跟以前长度一样的这些掩码的一些词源 masked tokens (一个可以学习到的向量 + 位置信息),重新 unshuffle 还原到原来的顺序
- MSE 算误差时,跟原始图的 patches 对应
【MAE】 Experiments
【对比实验】
【实验方法】
在 ImageNet-1K 100万张图片 数据集上
- 先做自监督的预训练(不用标号,只拿图片)
- 然后再在同样的数据集上做有标号的监督训练
【两种微调】
- end to end 的微调,允许改整个模型 所有的可学习的参数;
- linear probing 允许改最后一层的线性输出层
【实验结果】

- scratch, original: 76.5, ViT 所有的内容在 ImageNet-1K上训练, 结果不稳定 200
epoches - scratch, our impl.: 82.5 加入 strong regularization A.2 ViT 文章说 ViT
需要很大的数据才行 小一点的数据 + 合适的正则化 ✔ - baseline MAE: 84.9 先使用 MAE 做预训练,再在 ImageNet 上微调 50 epoches
数据集没变化,预训练和微调都是 ImageNet MAE 纯从图片上学到不错的信息
【消融实验】
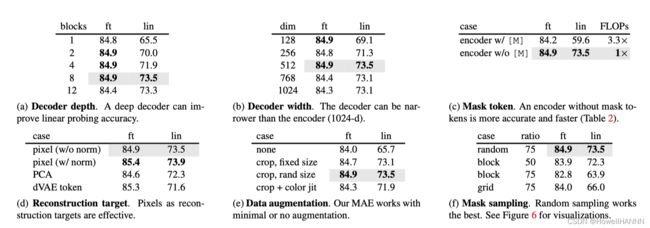
(a) 解码器的深度,即多少个 Transformer 块
ft(fine-tune所有可学习的权重都一起调):效果和深度关系不大 84.x,效果更好(但耗费更贵)
lin(linear-probe只调最后一个线性层):深度深一点好
(b) 解码器的宽度,每一个 token 表示成一个多长的向量
512 最佳
(c) 编码器要不要加入masked patches:
w/o(不加masked)精度更高、计算量更少
结论:非对称的架构 精度更好、性能更好
(d) 重构的目标:minimize MSE(pixel)
w/o + normalization(均值为0 方差为 1):效果和w/差不多,但计算量更小,更简单
w/ + normalization(均值为0 方差为 1) :效果最好
PCA (做一次降维)
dVAE(BEiT 的做法,通过 ViT 把每一个块映射到一个离散的 token,像 BERT 一样的去做预测)
(e) 怎么样做数据增强
什么都不做
固定大小的裁剪(crop)
随机大小的裁剪(crop):效果最好
裁剪 + 颜色变化
结论:MAE 对数据增强不敏感
(f) 怎么采样 被盖住的块
随机采样 (采样率75 %):最简单最好
块采样 (采样率50 %)
块采样 (采样率75 %)
网格采样(采样率75 %)
【不同超参数对MAE精度的影响】
【Masking率】
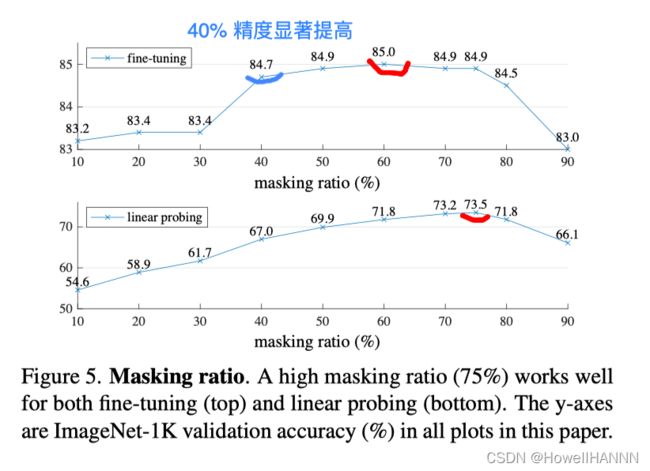
【训练时间】
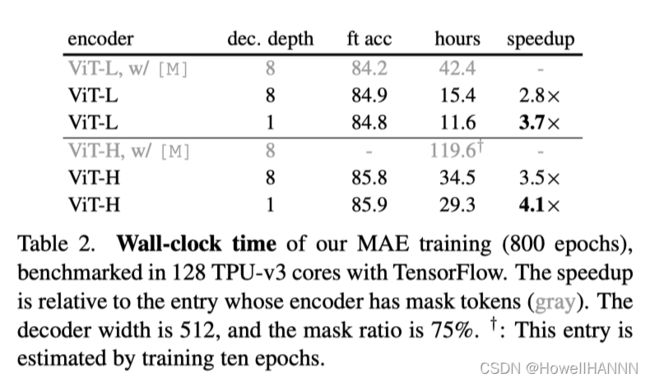
128核TPU-v3+TensorFlow
ViT-Large + 解码器只使用一层 Transformer 的patch:84.8% 精度不错,耗时最少 (11.8h)
ViT-Huge + 解码器只使用一层 Transformer 的patch:85.9% 精度不错,耗时最少 (29.3d)
【不同Mask采样策略的对比】

左:随机采样(采样率75%) 效果最好
中:方块采样(采样率50%)
右:网格采样(采样率75%)
【预训练的epochs对微调精度的影响】
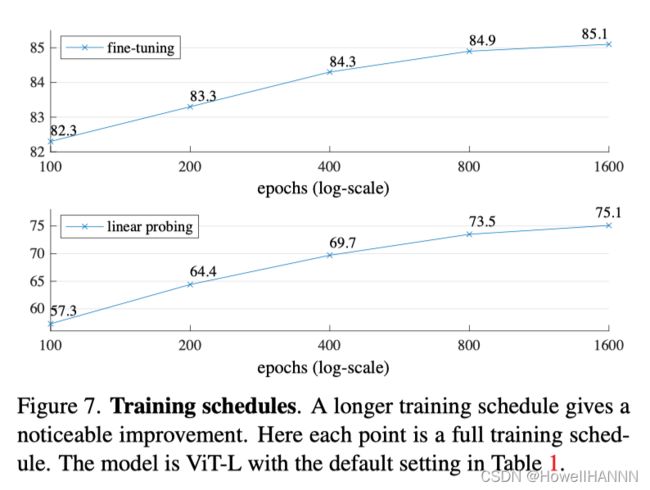
ImageNet-1K 上训练个 1000 个数据轮,精度仍有提升,过拟合没很严重
一般在 ImageNet 上训练, 200轮就足够了,1000轮已经很多了。
【MAE与其他工作的对比】
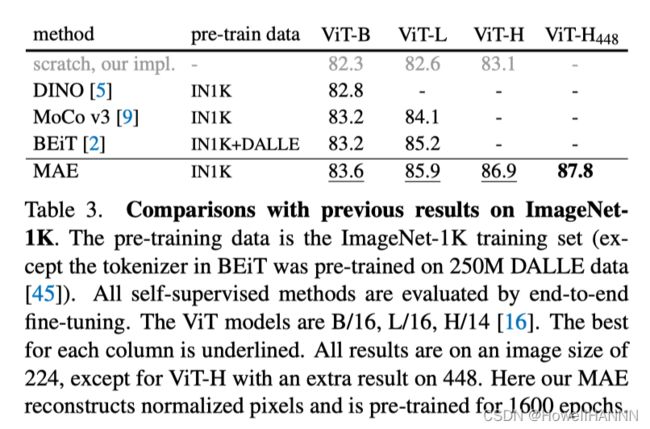
在ImageNet-1K上,与以前工作对比,MAE效果最好

MAR预训练vs.有监督预训练:JFT效果最好,MAE次之。(可能因为JFT数据集包括的类数远远大于 ImageNet)
【MAE微调层数对精度的影响】
fine-tune层数少,快,精度差
fine-tune层数多,慢,精度好
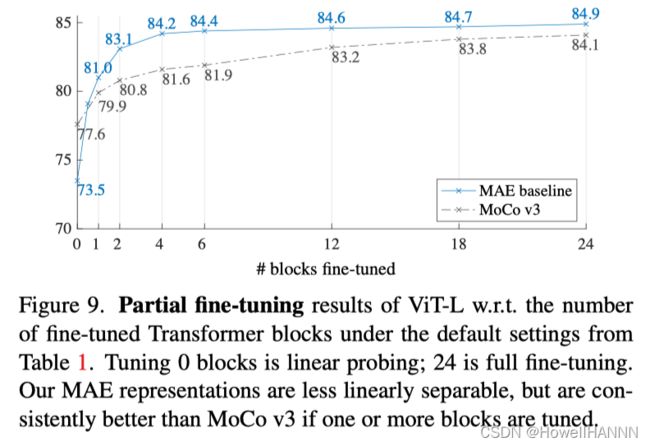
调 4 - 5 层比较好
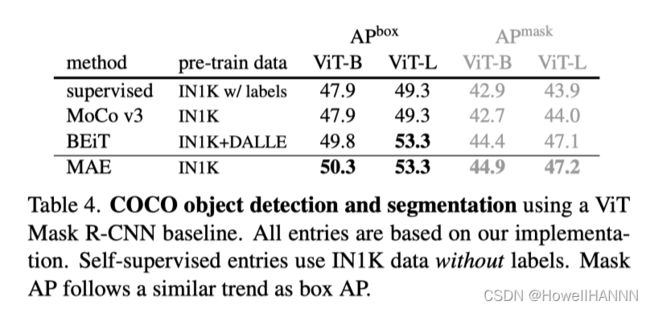
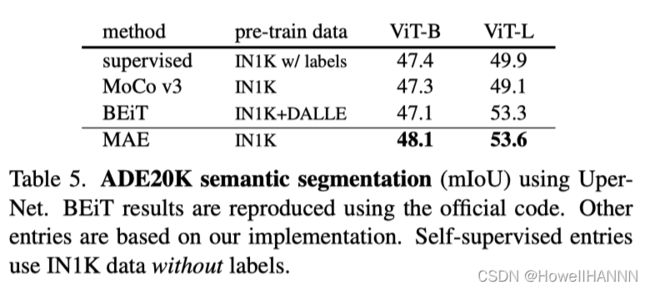
【MAE】在迁移学习的应用
- 目标检测
- 语义分割
【MAE】结论
【MAE思想很简单】利用 ViT 来做跟 BERT 一样的自监督学习
【MAE 相对ViT 的提升点】
- 需要mask更多的块,降低剩余块之间的冗余度,任务变得复杂一些
- 使用一个 Tranformer 架构的解码器,直接还原原始的像素信息,使得整个流程更加简单一点
- 加上在 ViT 工作之后的各种技术,训练更鲁棒