【学习记录】Pytorch CNN model
Pytorch学习记录
- 【想法】
- 【资料卡】
- 【pycharm】
- 【神经网络模型】
-
- 全连接层
- 全局平均池化层
- 【模型训练相关】
-
- 优化器SGD
- nn.sequential
- nn.Conv2dl
- 【模型融合】
-
- nn.ReLU(inplace=True)
- nn.MaxPool2d(kernel_size=2, stride=2),
- np.linspace()
- 【导入模型】
-
- model.train()/eval()
- with torch.no_grad()
- load_state_dict
- debug
- 【优化模型】
-
- 优化模型参数
- 指定训练层
- 【数据特征提取】
-
- 功能快捷键
- 生成一个适合你的列表
- 创建一个表格
-
- 设定内容居中、居左、居右
- SmartyPants
- 创建一个自定义列表
- 新的甘特图功能,丰富你的文章
- FLowchart流程图
【想法】
- 没有模型,可以参数初始化
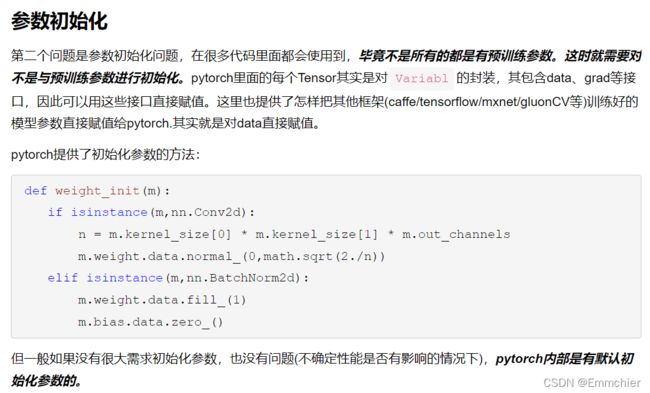
- 模型+模型 model
【资料卡】
- DeepLearningNote
【pycharm】
- 注释 ctrl+/ (如果突然用不了这个快捷键 抽风?一会儿好像又好了
- 全局搜索 Ctrl + Shift + F
【神经网络模型】
深度学习之PyTorch实战(2)——神经网络模型搭建和参数优化
!文章入门强烈推荐,写的非常详细。


- torch.nn.Linear类用于定义模型的线性层,即完成前面提到的不同的层之间的线性变换。
- torch.nn.ReLU类属于非线性激活分类。
- 【损失函数的具体用法】。。。
- 模型训练。引入了优化算法,所以通过直接调用optimzer.zero_grad来完成对模型参数梯度的归零;并且在以上代码中增加了optimzer.step,它的主要功能是使用计算得到的梯度值对各个节点的参数进行梯度更新。
- torch.optim:模型参数的优化
- torch.autograd:自动梯度

- model forward: 也就是说 ,当把定义的网络模型 model 当做函数调用的时候就自动调用定义的网络模型 forward方法。 可以看到,当执行 model(x) 的时候,底层自动调用 forward 方法计算结果。
- pytorch中 x = x.view(x.size(0), -1) 的理解: view() 函数的功能跟 reshape类似,用来转换size大小。x = x.view(batchsize, -1) 中的 batchsize 指转换后有几行,而 -1 指在不告诉函数有多少列的情况下,根据原tensor数据和batchsize自动分配列数。
- 全连接层 卷积层
全连接层
- 全连接层需要把输入拉成一个列项向量
- 卷积层就相当于一个卷积核,对于传送过来的feature map进行局部窗口滑动,无论你输入的feature map多大(不能小于卷积核的大小),都不会对卷积造成影响:

- 全连接层 时间复杂度_CNN各层与全连接层产生的参数计算方式
- 全连接层缺陷
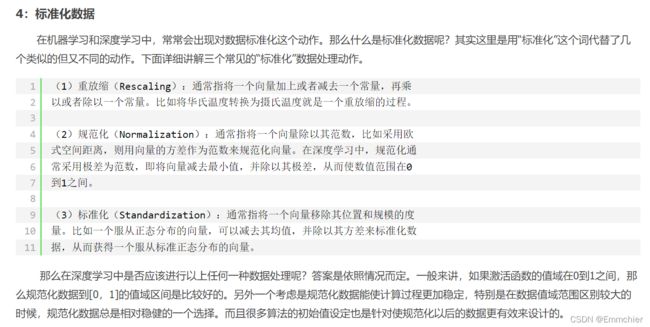
全局平均池化层
https://zhuanlan.zhihu.com/p/46235425
- 在卷积神经网络的初期,卷积层通过池化层(一般是 最大池化)后总是要一个或n个全连接层,最后在softmax分类。其特征就是全连接层的参数超多,使模型本身变得非常臃肿。
- global average poolilng。既然全连接网络可以使feature map的维度减少,进而输入到softmax,但是又会造成过拟合,是不是可以用pooling来代替全连接。
答案是肯定的,Network in Network工作使用GAP来取代了最后的全连接层,直接实现了降维,更重要的是极大地减少了网络的参数(CNN网络中占比最大的参数其实后面的全连接层)。
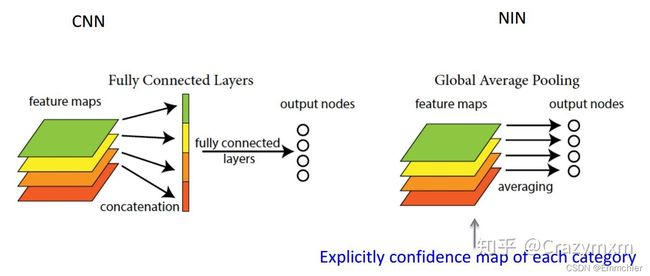
GAP的真正意义是:对整个网路在结构上做正则化防止过拟合。其直接剔除了全连接层中黑箱的特征,直接赋予了每个channel实际的内别意义。实践证明其效果还是比较可观的,同时GAP可以实现任意图像大小的输入。但是值得我们注意的是,使用gap可能会造成收敛速度减慢。 - 论文:Network In Network
- 关于使用GAP或者全局池化的好处,卷积神经网络在图像分类中,把卷积层作为特征提取,全链接层+softmax作为归回分类,这样方式会导致在全连接层输入神经元太多容易导致过拟合,所以Hinton等人提出了Dropout概念,提高网络泛化能力防止了过拟合发生。但是GAP是另外方式避免全连接层的处理,直接通过全局池化+softmax进行分类,它的优点是更加符合卷积层最后的处理,另外一个优点是GAP不会产生额外的参数,相比全连接层的处理方式,降低整个计算量,此外全局池化还部分保留来输入图像的空间结构信息,所以全局池化在有些时候会是一个特别有用的选择。
- avg_pool2d 代码原理
【模型训练相关】
优化器SGD
随机梯度下降(stochastic gradient descent)
optimizer = optim.SGD(net.parameters(), lr=0.01, weight_decay=1e-6, momentum=0.9, nesterov=True)
nn.sequential
Pytorch 容器之 nn.Sequential
nn.Sequential 是一个有序的容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,同时以神经网络模块为元素的有序字典也可以作为传入参数。
在初始化函数 init 中,首先是 if 条件判断,如果传入的参数为 1 个,并且类型为 OrderedDict,通过字典索引的方式将子模块添加到 self._module 中,否则,通过 for 循环遍历参数,将所有的子模块添加到 self._module 中。
nn.Conv2dl
pytorch之torch.nn.Conv2d()函数详解
【PyTorch学习笔记】17:2D卷积,nn.Conv2d和F.conv2d
nn.Conv2d:对由多个输入平面组成的输入信号进行二维卷积


【模型融合】
nn.ReLU(inplace=True)
将输入小于0的值幅值为0,输入大于0的值不变。
inplace=true 选择是否将得到的值计算得到的值覆盖之前的值。节省内存。
nn.MaxPool2d(kernel_size=2, stride=2),
在由多个输入通道组成的输入信号上应用2D max池。
【学习笔记】torch.nn.MaxPool2d参数解释

np.linspace()
np.linspace主要用来创建等差数列。
numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None, axis=0)
开始值,结束值,样本数。
【导入模型】
model.train()/eval()
model.train()和model.eval()的区别主要在于Batch Normalization和Dropout两层。
区别
训练集在train下运行,验证集和测试集都在eval下运行
with torch.no_grad()
pytorch中with torch.no_grad():
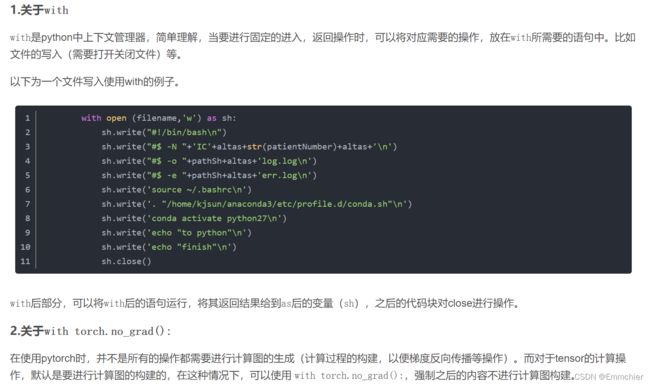
![]()
好像可以减少内存开销?
load_state_dict
torch.load_state_dict()函数就是用于将预训练的参数权重加载到新的模型之中

debug
1.TypeError: ‘CNN2d_classifier_xiao’ object is not subscriptable
——索引对象不支持索引
2.
3. Can’t get attribute ‘cnn2d_xiao_merge’ onmain’

【优化模型】
优化模型参数
优化

指定训练层
pytorch载入预训练模型后,实现训练指定层
【数据特征提取】
功能快捷键
撤销:Ctrl/Command + Z
重做:Ctrl/Command + Y
加粗:Ctrl/Command + B
斜体:Ctrl/Command + I
标题:Ctrl/Command + Shift + H
无序列表:Ctrl/Command + Shift + U
有序列表:Ctrl/Command + Shift + O
检查列表:Ctrl/Command + Shift + C
插入代码:Ctrl/Command + Shift + K
插入链接:Ctrl/Command + Shift + L
插入图片:Ctrl/Command + Shift + G
查找:Ctrl/Command + F
替换:Ctrl/Command + G
生成一个适合你的列表
- 项目
- 项目
- 项目
- 项目
- 项目1
- 项目2
- 项目3
- 计划任务
- 完成任务
创建一个表格
一个简单的表格是这么创建的:
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
设定内容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文本居中 | 第二列文本居右 | 第三列文本居左 |
SmartyPants
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' |
‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" |
“Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash |
– is en-dash, — is em-dash |
创建一个自定义列表
-
Markdown
- Text-to-HTML conversion tool Authors
- John
- Luke
新的甘特图功能,丰富你的文章
- 关于 甘特图 语法,参考 这儿,
FLowchart流程图
我们依旧会支持flowchart的流程图:
-
关于 Flowchart流程图 语法,参考 这儿.