Pytorch 学习2(CNN)
CNN 神经网络
CNN (Convolution Neural Network) 卷积神经网络主要卷积层,激活层,池化层,Dropout, batch Normal 等层按照一定的顺序组成。
卷积和卷积层
卷积操作被广泛应用与图像处理领域,不同卷积核可以提取不同的特征,例如边沿、线性、角等特征。在深层卷积神经网络中,通过卷积操作可以提取出图像低级到复杂的特征。
单输入通道的情况,灰度图像
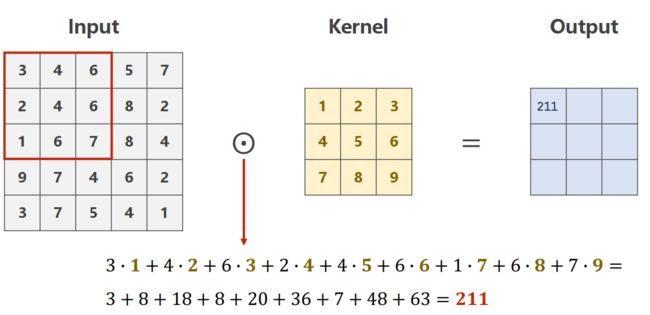
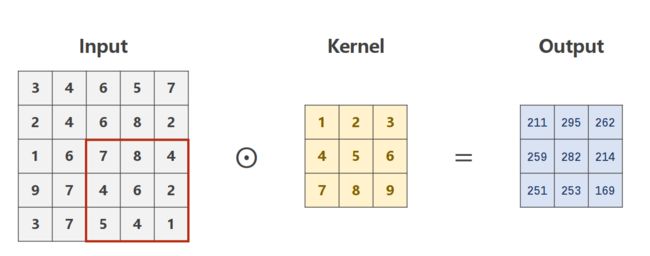
多通道输入
三通道彩色图像
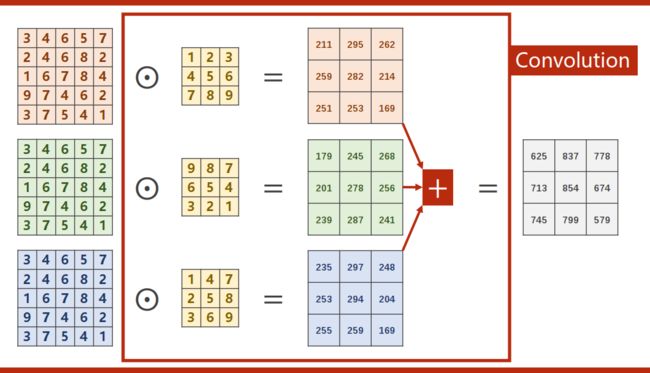
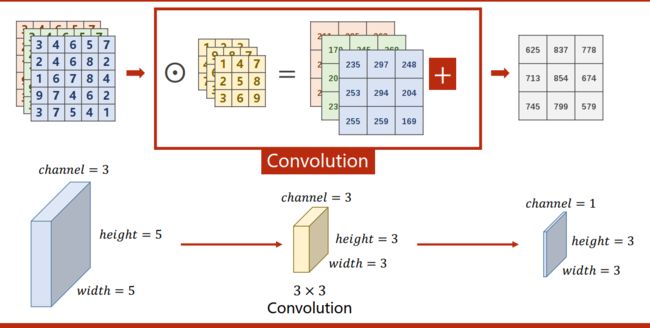 推广至n维
推广至n维
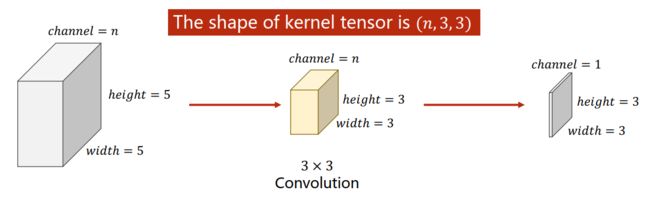
卷积层的本质
输入(n,iw,ih),卷积层(m,n,kw,kh),输出(m,ow,oh)

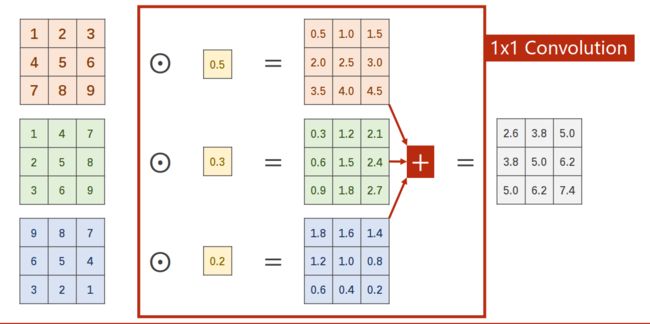
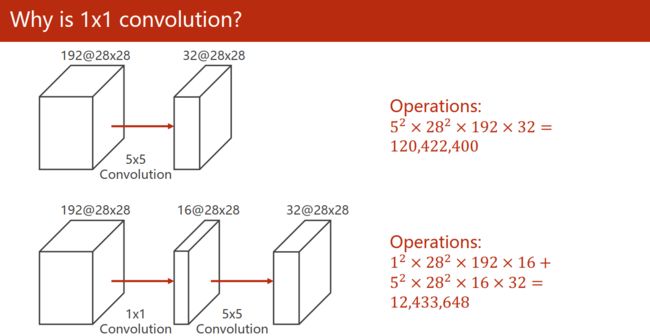
1 x 1卷积

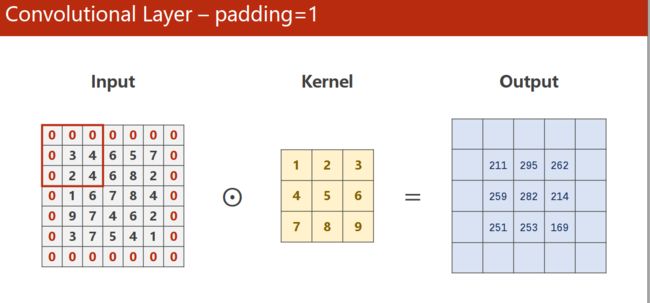
池化层-padding
padding = 1 的情况
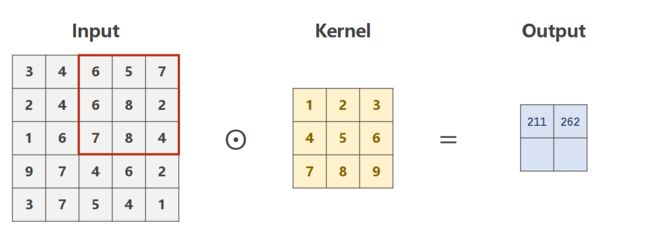
步长-stride
步长为2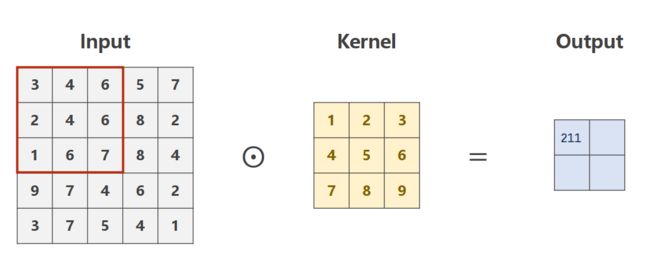
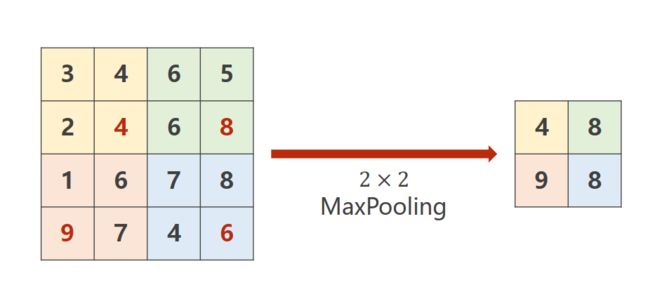
池化层--pooling
举例,最大池化层
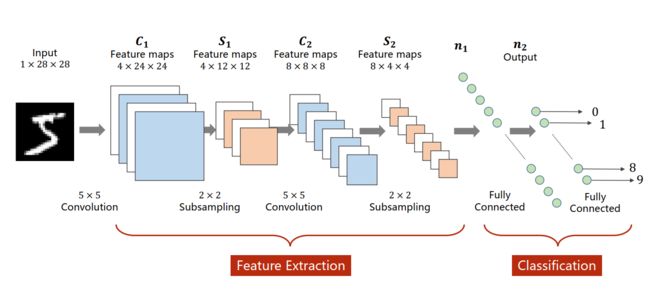
卷积神经网络的整体结构
定义一个神经网络实例
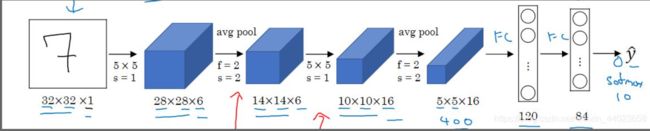
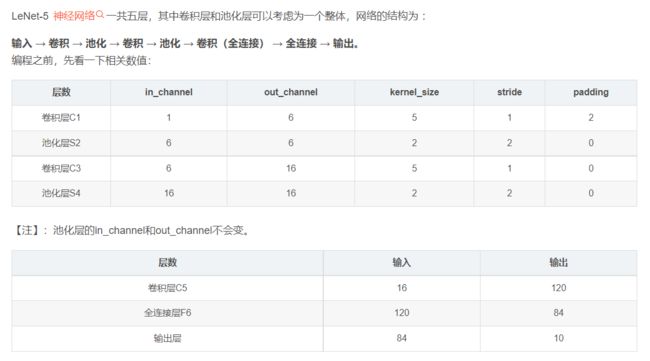
LeNet-5
针对0-9 的10个数字,进行分类任务
import torch
from torch import nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
import os
from torch import optim
'''
数据集准备
'''
batch_size = 64 # 分批训练数据、每批数据量
DOWNLOAD_MNIST = False # 是否网上下载数据
#数据准备
# Mnist digits dataset
if not(os.path.exists('./mnist/')) or not os.listdir('./mnist/'):#判断mnist数据集是否已下载
# not mnist dir or mnist is empyt dir
DOWNLOAD_MNIST = True
train_dataset = datasets.MNIST(
root = './mnist',
train= True, #download train data
transform = transforms.ToTensor(),
download=DOWNLOAD_MNIST
)
test_dataset = datasets.MNIST(
root='./mnist',
train=False, #download test data False就表示下载测试集的数据
transform=transforms.ToTensor(),
download=DOWNLOAD_MNIST
)
#该接口主要用来将自定义的数据读取接口的输出或者PyTorch已有的数据读取接口的输入
# 按照batch size封装成Tensor,后续只需要再包装成Variable即可作为模型的输入
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) #shuffle 是否打乱加载数据
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
'''
建立神经网络模型
'''
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
#搭建卷积层C1 和 池化层 S2
self.conv1 = nn.Sequential(
nn.Conv2d(1,6,kernel_size=5,stride=1,padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2,padding=0)
)
#搭建卷积层C3 和 池化层 S4
self.conv2 = nn.Sequential(
nn.Conv2d(6,16,kernel_size=5,stride=1,padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2,padding=0)
)
#搭建全连接层C5 全连接层F6 输出层
self.fc = nn.Sequential(
nn.Linear(16*5*5,120),
nn.ReLU(),
nn.Linear(120,84),
nn.ReLU(),
nn.Linear(84,10)
)
#设置网络前向传播,按顺序
def forward(self,x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) #全连接层均使用的nn.Linear()线性结构,输入输出维度均为一维,故需要把数据拉为一维
x = self.fc(x)
return x
net = LeNet()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") #若检测到GPU环境则使用GPU,否则使用CPU
net = LeNet().to(device) #实例化网络,有GPU则将网络放入GPU加速
'''
误差和优化
'''
loss_fuc = nn.CrossEntropyLoss() #多分类问题,选择交叉熵损失函数
optimizer = optim.SGD(net.parameters(),lr = 0.001,momentum = 0.9) #选择SGD,学习率取0.001
'''
训练过程
'''
# 开始训练
EPOCH = 8 # 迭代次数
for epoch in range(EPOCH):
sum_loss = 0
# 数据读取
for i, data in enumerate(train_loader):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device) # 有GPU则将数据置入GPU加速
# 梯度清零
optimizer.zero_grad()
# 传递损失 + 更新参数
output = net(inputs)
loss = loss_fuc(output, labels)
loss.backward()
optimizer.step()
# 每训练100个batch打印一次平均loss
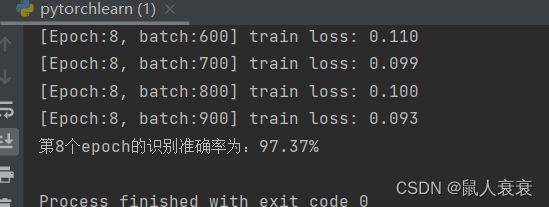
sum_loss += loss.item()
if i % 100 == 99:
print('[Epoch:%d, batch:%d] train loss: %.03f' % (epoch + 1, i + 1, sum_loss / 100))
sum_loss = 0.0
correct = 0
total = 0
for data in test_loader:
test_inputs, labels = data
test_inputs, labels = test_inputs.to(device), labels.to(device)
outputs_test = net(test_inputs)
_, predicted = torch.max(outputs_test.data, 1) # 输出得分最高的类
total += labels.size(0) # 统计50个batch 图片的总个数
correct += (predicted == labels).sum() # 统计50个batch 正确分类的个数
print('第{}个epoch的识别准确率为:{}%'.format(epoch + 1, 100 * correct.item() / total))
# 模型保存
torch.save(net.state_dict(), 'E:\\研究生\\数字图像处理\\python\\pytorch2\\ckpt.mdl')
# 模型加载
# net.load_state_dict(torch.load('ckpt.mdl'))