CUDA编程学习0——环境搭建&环境详解
目录
环境配置
软件安装
1.支持最高的cuda版本查询,下载cuda开发软件;
3.配置环境(~/.bashrc添加环境变量)
4.后续维护查询
补:关于windows下的cuda环境配置
一、Visual Studio 2022 + CUDA 11.6 (Windows10)
二、Visual Studio Code + CUDA 11.6 (远程连接Ubuntu)
摘要:由于课题要对图像处理程序进行加速,于是我想着将CPU处理程序改用GPU来进行实现;也是初入门路,这里记录下学习的过程;
环境配置
系统:Centos7,
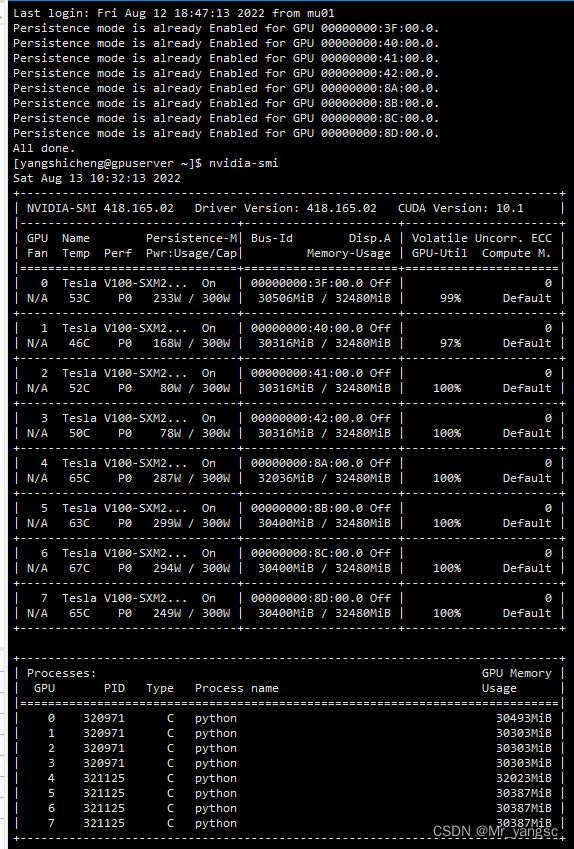
驱动&显卡:CUDA10.0(不是命令中显示的最高支持型号),显卡Tesla,(查看显卡和最高驱动支持版本“nvidia-smi”)
编译器版本:gcc版本是5.1.0
软件安装
1.支持最高的cuda版本查询,下载cuda开发软件;
如上图所示,我们支持的最大的cuda版本是10.1,则我去英伟达cuda官网去找的驱动安装包要小于等于这个;
下载对应的版本,不是最新的版本;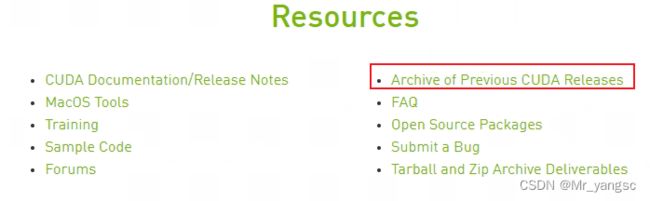
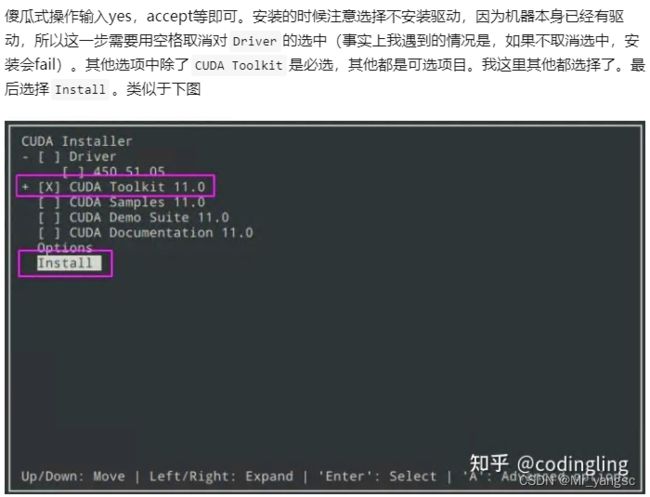
根据硬件配置选择合适的版本;(其中runfile执行较为简单,我这里选择它) 2.下载好了之后,直接执行“sh XXXXX.run",则开始自动安装,基本是傻瓜式安装;
2.下载好了之后,直接执行“sh XXXXX.run",则开始自动安装,基本是傻瓜式安装;
Linux系统CUDA安装及踩坑记录 - 知乎 (zhihu.com)
3.配置环境(~/.bashrc添加环境变量)
检查cuda是否安装成功:nvcc -V
如果没有这个命令的话,需要配置。(同时也要去看安装的路径下是否有nvcc)
vim /.bashrc在文件末尾添加(这里的
/usr/local/cuda-11.3替换成你的cuda安装路径,一般都在/usr/local路径下)export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-11.3/lib64 export PATH=$PATH:/usr/local/cuda-11.3/bin # export CUDA_HOME=$CUDA_HOME:/usr/local/cuda-11.3 export CUDA_HOME=/usr/local/cuda-11.3然后
source ~/.bashrc(source命令是使该配置文件立刻生效,而无需重启系统)上述环境变量中,我看很多教程都是按照第三行配置的CUDA_HOME,但是后续我在使用deepspeed的时候会报错找不到
/usr/local/cuda-11.3:/usr/local/cuda-11.3/bin/nvcc,按照第四行配置CUDA_HOME就不会有这个问题。再执行
nvcc -V就会显示出你刚刚安装的CUDA版本
4.后续维护查询
查看当前安装的cuda版本:Linux上查看已安装的CUDA和cuDNN版本号-云社区-华为云 (huaweicloud.com)

Linux上查询cuda、cudnn等相关的系列东西
1. 查看CUDA版本
cuda默认安装在/usr/local目录,可以使用ls -l /usr/local | grep cuda查看该目录下有哪些cuda版本
假设有如下输出:
lrwxrwxrwx 1 root root 8 Apr 26 2019 cuda -> cuda-9.0 drwxr-xr-x 11 root root 4096 Apr 26 2019 cuda-10.0 drwxr-xr-x 11 root root 4096 Apr 26 2019 cuda-8.0 drwxr-xr-x 11 root root 4096 Apr 26 2019 cuda-9.0则表示当前机器上安装了8.0、9.0、10.0三个cuda版本,/usr/local/cuda是一个软链接,链接到了/usr/local/cuda-9.0目录,表示当前使用的是cuda-9.0版本。
如果要查看详细的cuda版本号,可以用如下两种方法:
- nvcc --version,如果提示找不到该命令,则执行/usr/local/cuda/bin/nvcc --version,如果报找不到该路径或文件,则表示nvcc没有安装,可以sudo apt install nvidia-cuda-toolkit安装
- cat /usr/local/cuda/version.txt
如果当前机器上安装了多个cuda版本,可以使用修改软链接的方式来修改系统使用的cuda版本,命令如下:
sudo ln -snf /usr/local/cuda-8.0 /usr/local/cuda2. 查看cuDNN版本号
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 23. CUDA是否可用于当前AI开发框架?
确定了CUDA版本号,那么该版本是否可以用于当前安装的AI开发框架呢?如pytorch、tf?
- 如果使用pytorch,可以使用如下语句查询是否可用:(可直接linux命令行输入执行)
import torch print(torch.__version__) # 查看torch当前版本号 print(torch.version.cuda) # 编译当前版本的torch使用的cuda版本号 print(torch.cuda.is_available()) # 查看当前cuda是否可用于当前版本的Torch,如果输出True,则表示可用 如果尚未安装torch,可以查看pytorch各版本与CUDA各版本的对应关系: https://pytorch.org/get-started/previous-versions/
- 如果使用tf,
则没有pytorch这么方便的方式来查看CUDA是否可用(实际操作和torch是一样的应该也可以,该文的时效性代待考证)只能在 import tensorflow as tf 的时候才能发现CUDA是否可用,如果不可用,会有如下类似的报错: ImportError: libcublas.so.9.0: cannot open shared object file: No such file or directory 这就表示当前tf需要CUDA 9.0,但是没有找到,决定tf应该使用哪个版本的CUDA,是tf安装目录下的一个_pywrap_tensorflow_internal.lib库文件定义的,里面是如何实现的,就得去看源码了。 但是我们可以用更简单的方法来查看tf与CUDA的对应关系,可用过官网查询: https://tensorflow.google.cn/install/source#tested_build_configurations https://tensorflow.google.cn/install/source_windows#tested_build_configurations查看cuda和cudnn版本对应关系,则可以访问:https://developer.nvidia.com/rdp/cudnn-archive#a-collapse742-10
4. 其他疑问
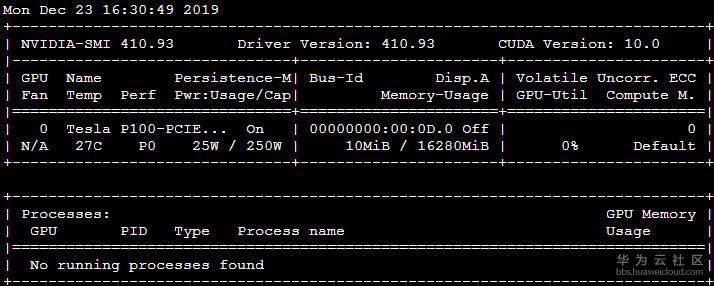
我们还经常用到nvidia-smi命令,使用该命令会有如下输出:(nvidia-smi命令可以查看GPU的具体使用情况,同时也会列出 CUDA Version。)
如果nvidia-smi命令列出的CUDA版本与nvcc -V列出的版本号不一致,可能是由以下原因之一引起的:
- 安装多版本cuda后,还没有刷新环境变量,刷新即可;
- CUDA有两种API,分别是运行时API和驱动API,即所谓的Runtime API与Driver API,nvidia-smi的结果除了有GPU驱动版本型号,还有CUDA Driver API的版本号,这里是10.0,而nvcc的结果是对应CUDA Runtime API
补充说明:
在安装CUDA 时候会安装3大组件,分别是 NVIDIA 驱动(driver)、toolkit和samples。
- NVIDIA驱动是用来控制GPU硬件,CUDADriver API是依赖于NVIDIA驱动安装的。
- toolkit里面包括nvcc编译器等,CUDA Runtime API 是通过CUDA toolkit安装的。
- samples或者说SDK 里面包括很多样例程序包括查询设备、带宽测试等等。
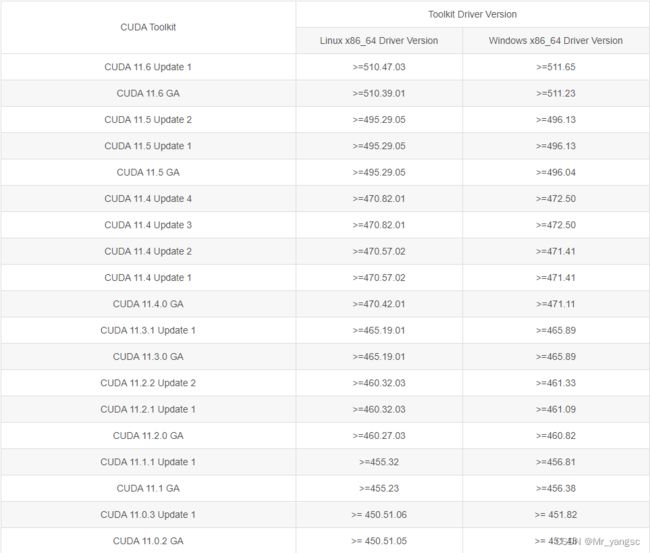
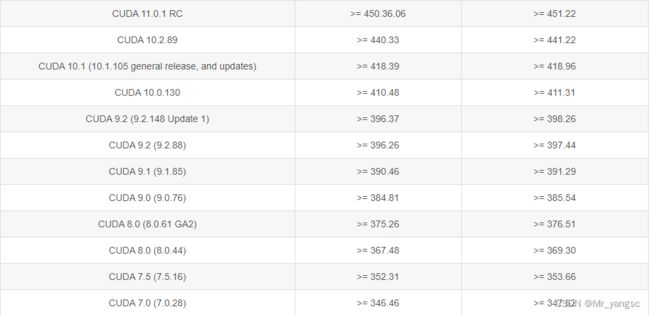
注:查看nvidia驱动版本和toolkit对应的版本的要求:
官网地址:Release Notes :: CUDA Toolkit Documentation
参考链接:
nvidia-smi 和 nvcc 结果的版本为何不一致_JasonLiu1919的博客-CSDN博客
https://www.cnblogs.com/yhjoker/p/10972795.html
5. NVIDIA驱动版本与CUDA版本对应关系_lengmo1996的博客-CSDN博客_cuda和nvidia驱动的版本关系
#############################################################################
补:关于windows下的cuda环境配置
虽未实现,但是收集了些资料
(40条消息) windows 下 CUDA 并行编程环境搭建_吃跳跳糖没的博客-CSDN博客_cuda编程 windows
下面介绍一种,参考:https://zhuanlan.zhihu.com/p/488518526
记录两种CUDA开发环境的配置过程。
一、Visual Studio 2022 + CUDA 11.6 (Windows10)
(参考:win10+cuda11.0+vs2019安装教程)
1、Visual Studio community 2022的安装
1). 下载Visual Studio community 2022 版本。下载连接
2). 安装”使用c++的桌面开发“,安装的路径可以自定义

2、NVIDIA驱动的安装
1)检查驱动是否安装:在cmd命令窗口中输入nvidia-smi:
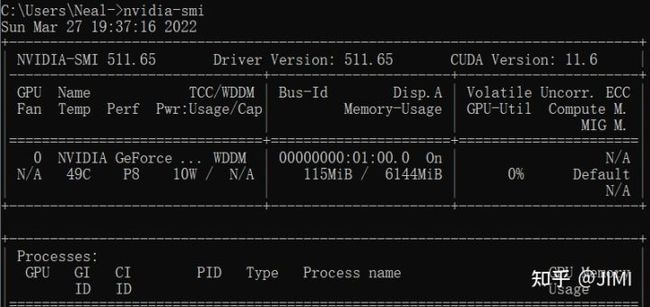
同时可以查看驱动的版本号
2)如果没有安装,则可以进入NVIDIA官网选择相应的显卡进行下载,并安装驱动。如能显示上图信息,则驱动安装成功。NVIDIA驱动下载地址
3、CUDA 11.6的安装
1). 进入CUDA Toolkit官网进行下载。下载后直接运行exe文件,默认安装即可。CUDA 11.6下载地址
2). 安装结束后,查看系统变量中已经加入了cuda的两个路径:

3). 继续添加其它的环境变量:
在系统变量中加入下面的路径,点击确定:
CUDA_BIN_PATH: %CUDA_PATH%\bin
CUDA_LIB_PATH: %CUDA_PATH%\lib\x64
CUDA_SDK_PATH: C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.6
CUDA_SDK_BIN_PATH: %CUDA_SDK_PATH%\bin\win64
CUDA_SDK_LIB_PATH: %CUDA_SDK_PATH%\common\lib\x64在系统变量path中加入下面的的变量:
%CUDA_BIN_PATH%
%CUDA_LIB_PATH%
%CUDA_SDK_BIN_PATH%
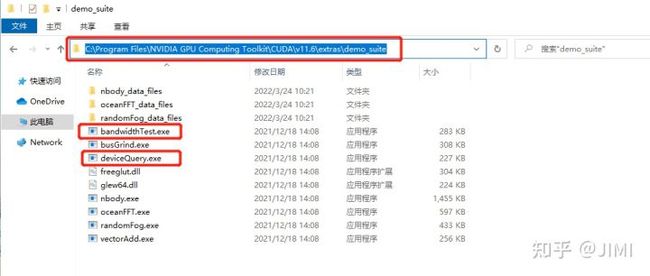
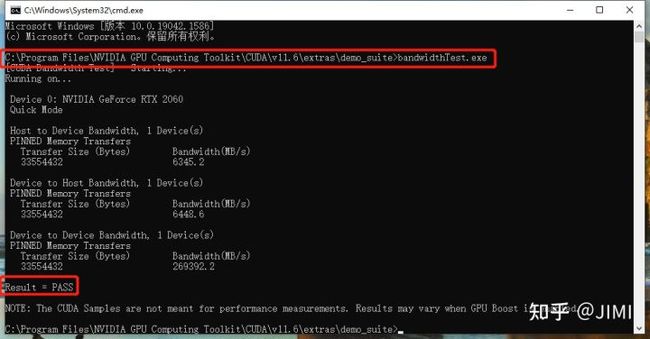
%CUDA_SDK_LIB_PATH%4). 检查是否安装成功:
打开cmd,定位到图示位置。分别运行这两个程序deviceQuery.exe、bandwidthTest.exe ,result=pass则安装成功,否则就重新安装:

4、Visual Studio 配置与测试
1). 启动VS2022,新建一个工程,点击CUDA11.6 runtime。
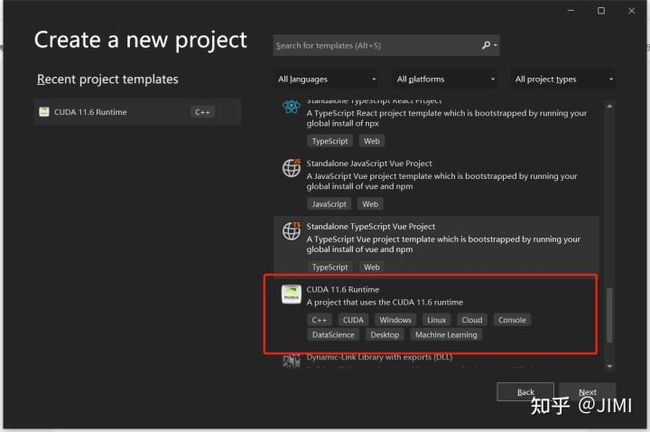
2). 新建工程。

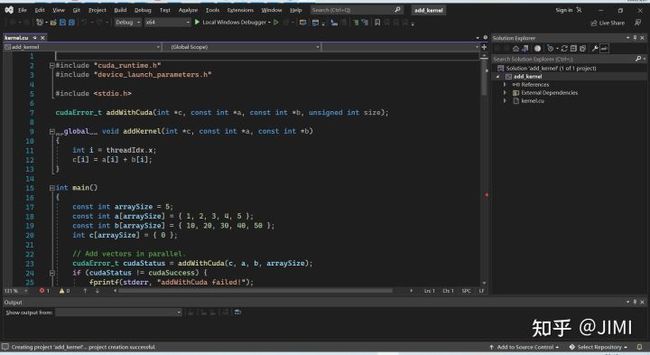
3). 新建完成后,会出现一个示例,具体内容为kernel.cu (程序分析)
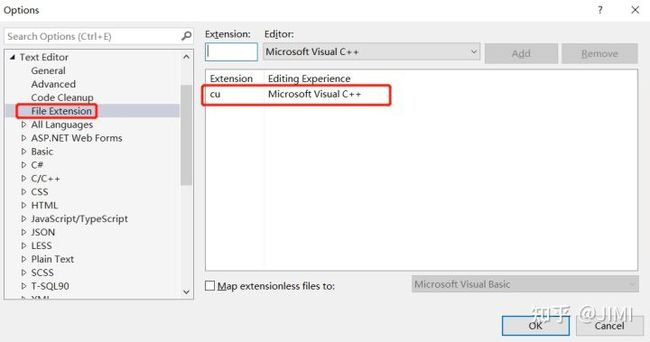
4). 添加.cu 到编辑器和扩展名:
(工具–>选项–>文本编辑器–>文件拓展名, 新增扩展名 .cu 并将编辑器设置为:Microsoft Visual C++。)
(工具–>选项–>项目和解决方案–>VC++项目设置,添加要包括的扩展名".cu")
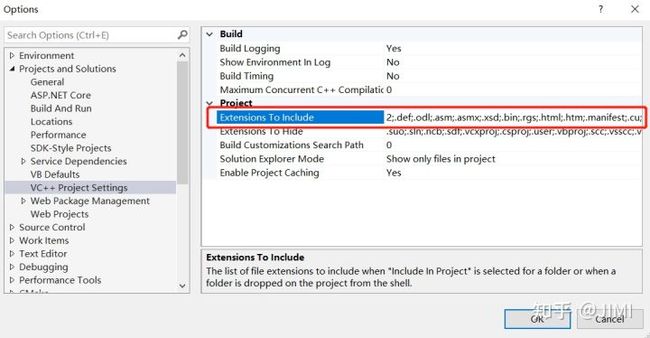
(右键打开的项目–>生成依赖项–>生成自定义–>勾选CUDA v11.6)

(右键.cu文件–>文件属性设置为 CUDA c/c++)
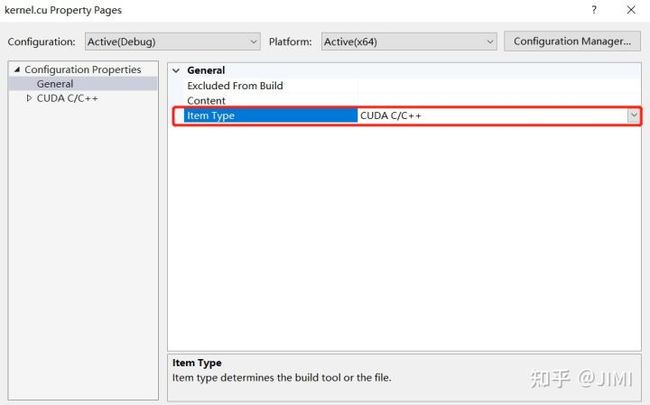
5). 测试。点击运行,得到下面结果。

5、debug
1). Visual Studio中默认是CPU代码的调试,如果需要调试GPU上的代码,需要使用extension中的Nsight (strat CUDA debugging).
(工具栏->插件->Nsight->start CUDA debugging)。同时勾选break on luanch。

进入GPU调试
二、Visual Studio Code + CUDA 11.6 (远程连接Ubuntu)
目前VS code中支持linux的CUDA-debug,暂不支持windows。
1、VS code 的安装。(省略)
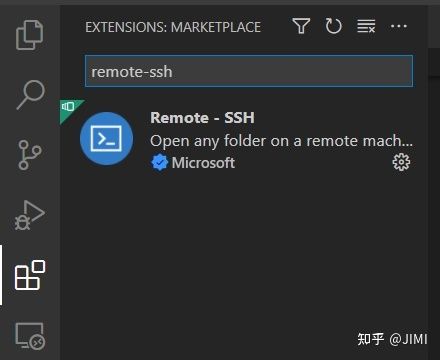
2、VS code ssh远程连接(可参考其他详细教程,这里只记录主要步骤)
安装Renote-SSH插件:
点击 ”+“,并在输入ssh登录命令:ssh root@ip -p xxxx

选择.ssh/config。

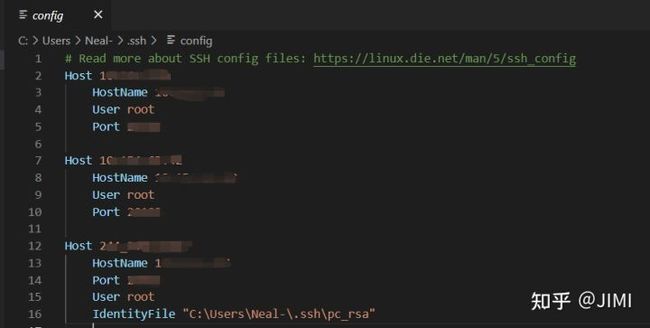
config文件记录了服务器的IP和端口号。
这里有两种登录方式,一种每次登录都需要输入密码,另一种是使用密钥登录。
1)输入密码登录:
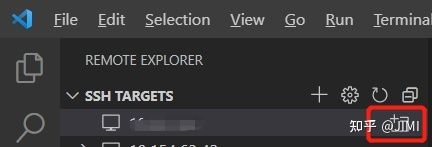
点击在新窗口中连接主机
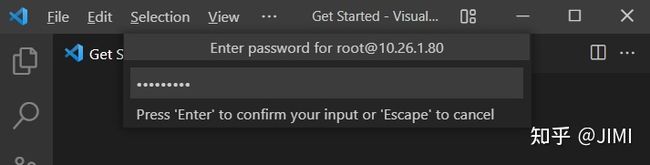
在新的窗口中,选择需要打开的文件路径,并输入密码
2)免密登录:
在本地打开cmd,输入ssh-keygen,
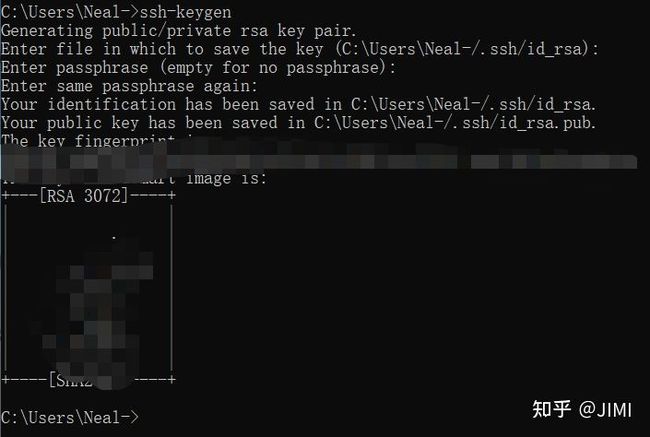
接着在C:\Users\(username)\.ssh中生成了两个文件:

在本地的.ssh/config文件中,加入密钥id_rsa路径。
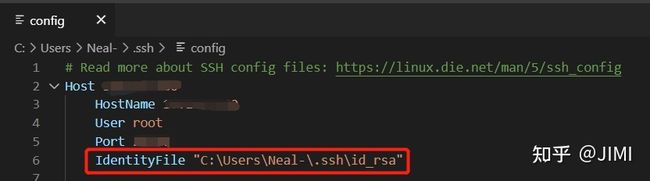
加入密钥地址
然后将公钥id_rsa.pub拷贝到服务器.ssh路径中,并在终端输入:
mkdir .ssh
mv id_rsa.pub .ssh
cd .ssh
cat id_rsa.pub >> authorized_keys
sudo chmod 600 authorized_keys
service sshd restart重启即可免密连接。
3、安装相关插件
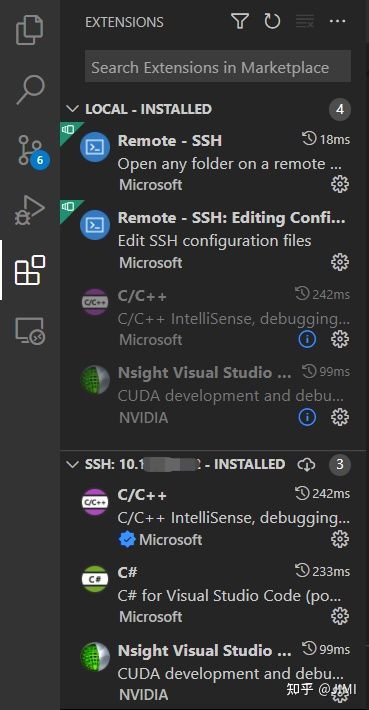
1). 在本地端和远程端安装C++和Nsight插件:
4). 安装CUDA 11.6
安装和更新相关依赖库,在终端中输入:
sudo apt update # 更新 apt
sudo apt install gcc g++ make # 安装 gcc g++ make
sudo apt install libglu1-mesa libxi-dev libxmu-dev libglu1-mesa-dev freeglut3-dev # 安装依赖库选择合适CUDA版本,并获取下载命令,官网地址。在终端输入获取的命令,自动下载和安装。
# 这里是安装CUDA11.6
wget https://developer.download.nvidia.com/compute/cuda/11.6.2/local_installers/cuda_11.6.2_510.47.03_linux.run
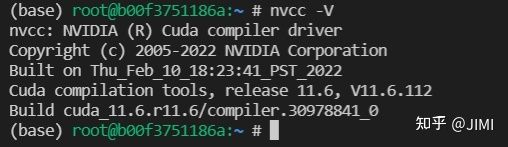
sudo sh cuda_11.6.2_510.47.03_linux.run验证是否安装成功:输入nvcc-V,得到下面的信息。
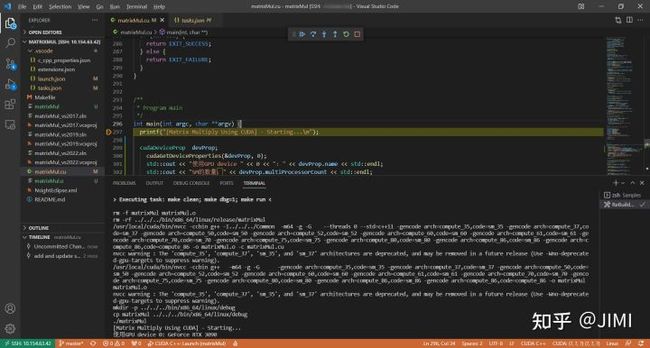
4、编译和调试(以matrixMul为例)
1). 打开例程matrixMul:
(cuda11.6中的例程在github中,需要手动git clone 下载。这里将Samples下载到/usr/local/cuda-11.6/samples/cuda_samples/Samples路径中)
2).编写 c_cpp_properties.json
{
"configurations": [
{
"name": "Linux",
"includePath": [ # 头文件路径
"${workspaceFolder}/**",
"${workspaceFolder}/../../../Common"
],
"defines": [],
"compilerPath": "/usr/local/cuda/bin/nvcc", # 编译器路径
"cStandard": "gnu17",
"cppStandard": "gnu++14",
"intelliSenseMode": "linux-gcc-x64",
"configurationProvider": "ms-vscode.makefile-tools"
}
],
"version": 4
}
3). 编写launch.json (用于debug)
# 点击run and debug --> create a luanch.json -->选择CUDA C++(CUDA-GDB)
# 将luanch.json 修改如下:
{
"version": "0.2.0",
"configurations": [
{
"name": "CUDA C++: Launch",
"type": "cuda-gdb",
"request": "launch",
"program": "${workspaceFolder}/matrixMul", # 程序所在路径
"debuggerPath":"/usr/local/cuda-11.6/bin/cuda-gdb", # 调试器所在的路径
"preLaunchTask": "ReBuild" # 程序所在路径
}
]
}4). 编写 tasks.json(用于build)
# 共编写了两个task,分别是build 和 rebuild
{
"version": "2.0.0",
"tasks": [
{
"label": "Build",
"type": "shell",
"command": "make dbg=1",
"problemMatcher": ["$nvcc"],
"group": {
"kind": "build"
}
},
{
"label": "ReBuild",
"type": "shell",
"command": "make clean; make dbg=1; make run",
"problemMatcher": ["$nvcc"],
"group": {
"kind": "build",
"isDefault": true
}
}
]
}5). 编译和调试:按F5。