【StyleGAN代码学习】StyleGAN损失函数与训练过程
完整StyleGAN笔记:http://www.gwylab.com/pdf/Note_StyleGAN.pdf
基于StyleGAN的一个好玩的网站:www.seeprettyface.com
—————————————————————————————————
第二章 StyleGAN代码解读(下)
2.3 损失函数代码解读
StyleGAN的损失函数写在training/loss.py下,包括了三种损失:WGAN/WGAN-GP损失,Hinge判别损失,以及StyleGAN倡导的logistic损失。最终StyleGAN选择了添加了简单梯度惩罚项的Logistic损失。
2.3.1 WGAN、WGAN-GP损失
· Loss_G(line 26-32)

生成器希望假样本的得分越高越好,故Loss_G = -D(G(z))。
· Loss_D不含梯度惩罚(line 34-48)
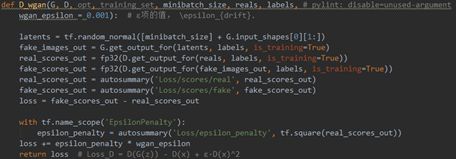
判别器希望假样本的得分越低越好同时真样本的得分越高越好,并且通过正则项限制真样本得分不宜过高否则易导致G失去学习的梯度,故Loss_D=D(G(z))-D(x)+ε·D(x)^2。
· Loss_D含梯度惩罚(line 50-78)

WGAN-GP中的判别损失多增添了一项梯度惩罚项,它的作用是让判别函数尽量符合1-lipschitz范数限制,即梯度的模始终小于1,这样才能让判别器的求解结果逼近Wasserstein距离,但是WGAN-GP并未达到严格的1-lipschitz范数限制,真正实现这一限制的是SNGAN中的谱归一化方法。最终WGAN-GP的判别损失为:
Loss_D=D(G(z))-D(x)+η·(||∇_T ||-1)^ 2+ε·D(x)^2
2.3.2 Hinge判别损失
· Loss_D不含梯度惩罚(line 84-92)
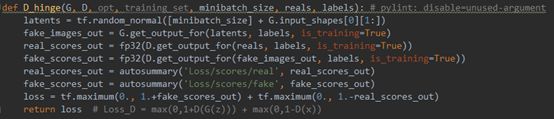
Hinge损失也是非常经典的一种损失,它限制判别函数的值只处在(-1,1)间有效,其表达式为:Loss_D=max(0,1+D(G(z)))+max(0,1-D(x))。
· Loss_D含梯度惩罚(line 94-117)

带有GP的Hinge损失添加的梯度惩罚项与WGAN-GP中的完全一致,都是逼迫所有位于惩罚区域中的样本梯度都尽量逼近1(或不超过1),最终Hinge-GP的判别损失为:
Loss_D=max(0,1+D(G(z)))+max(0,1-D(x))+η·(||∇_T ||-1)^2
2.3.3 StyleGAN提倡损失——Logistic损失
· Loss_G饱和逻辑斯谛(line 124-130)

选用饱和逻辑斯谛损失时,Loss_G=-log(exp(D(G(z)))+1)
· Loss_G非饱和逻辑斯谛(line 132-138)

选用非饱和逻辑斯谛损失时,Loss_G=log(exp(-D(G(z)))+1)
· Loss_D不含梯度惩罚(line 140-149)

不含梯度惩罚时,Loss_D=log(exp(D(G(z)))+1)+log(exp(-D(x))+1)
· Loss_D含梯度惩罚(line 151-176)

含梯度惩罚时,可能受到梯度惩罚的样本有两种:第一种是来自真实分布的样本,其梯度绝对值过高时会受到惩罚;第二种是来自生成分布的样本,其梯度绝对值过高时也会受到惩罚。StyleGAN中默认保留了对真实样本的梯度惩罚(r1_gamma=10),而舍弃了对生成样本的梯度惩罚(r2_gamma=0)。含有梯度惩罚的判别损失为:
Loss_D=log(exp(D(G(z)))+1)+log(exp(-D(x))+1)+r1_gamma0.5∑∇_(T_real )^ 2 +r2_gamma0.5∑∇_(T_fake )^2
最终,StyleGAN官方代码采用的损失为G_logistic_nonsaturating与D_logistic_simplegp。
2.4 训练过程代码解读
StyleGAN的训练调用接口写在train.py下,训练过程写在training/training_loop.py下。本节主要讲述在这两个代码文件中分别定义了哪些训练设置,以及简要说明training_loop的训练流程,从而方便我们在自定义训练时做出更合适的设置。
· train.py主要设置(line 21-55)
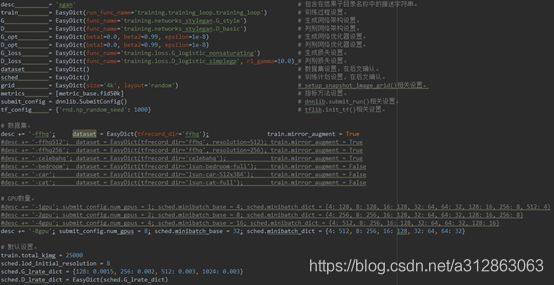
在训练StyleGAN的初始接口train.py下定义了一些主要的设置,包括生成网络和判别网络各自的架构、优化和损失的设置,以及训练计划、数据集和GPU的设置等。配置完成之后,通过调用dnnlib.submit_run(**kwargs)就能进入到StyleGAN的训练过程中。
在我们自定义训练时,通常需要手动调整数据集设置(名称和分辨率)、GPU设置(GPU数量和batch大小(它取决于GPU缓存大小))以及默认设置(总迭代数和学习率),而网络架构的设置则视情况而定,一般不建议修改。
· training/training_loop.py训练计划设置(line 56-71)
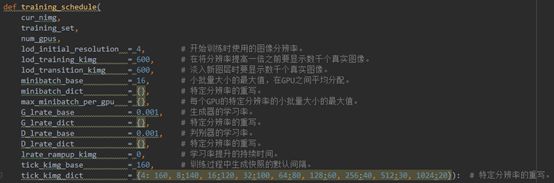
在training_schedule()函数中可以定义一些训练计划的设置,内容如上图所示。
· ★training/training_loop.py训练过程设置(line 113-139)
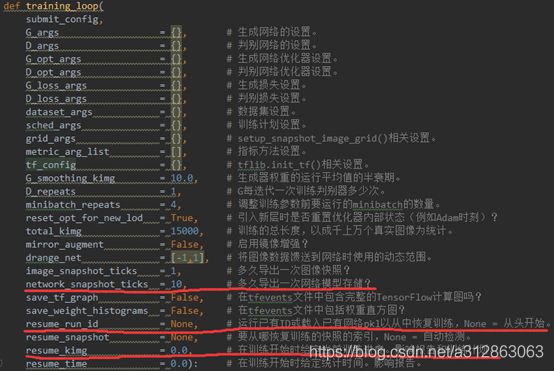
training_loop()包含最详细的训练设置,它也是在训练过程中被实时调用的函数。training_loop()既有由train.py传递过来的主要设置的参数(上图前11行),也包含一些更精细的训练过程设置,具体内容如上图所示。其中有三个比较常用的选项(上图红线部分),第一个是network_snapshot_ticks,它决定多久导出一次网络模型存储;第二个是resume_run_id,它可以导入之前存储的模型以继续训练;第三个是rusume_kimg,它可以自定义当前的训练进度和状态,一般在微调模型时被使用。
· ★training/training_loop.py训练过程流程(line 142-276)
训练的具体流程如下图所示,主要包括8个部分:初始化dnnlib和TensorFlow->载入训练集->构建网络->构建计算图与优化器->设置快照图像网格->建立运行目录->训练->保存最终结果。
由于这部分代码是StyleGAN作者依据自身的需求编写的,学习价值不是很大,我就不再细述了,感兴趣的读者可以自行阅读掌握。