StyleGAN v2:对StyleGAN v1的思考与改进
StyleGAN v2在v1的基础上进行了改进,着重处理的伪影问题,被CVPR2020收录,能够生成质量更好的图像数据。其在style mixing策略,progressive growing生成方式、插值方式等方面对v1进行了改进。
StyleGAN v2论文地址
工程地址
StyleGAN v1 一步一步地生成人工的图像,从非常低的分辨率 4 × 4 4×4 4×4开始,一直到高分辨率 1024 × 1024 1024×1024 1024×1024。通过分别地修改网络中每个级别的输入,它可以控制在该级别中所表示的视觉特征,从粗糙的特征(姿势、面部形状)到精细的细节(头发颜色),而不会影响其它的级别(通过非线性映射消除特征纠缠)。但是其有一个明显的缺陷——生成的图像有时包含斑点似的伪影(artifacts),未解决这个问题,提出了StyleGAN v2。
论文重新设计了生成器,结构如下所示:

- (a)是原始的StyleGAN,其中A表示从W学习的仿射变换,产生了一个style
- (b)展示了原始StyleGAN架构的细节。在这里,将AdaIN分解为先显式归一化再调制的模式,对每个特征图的均值和标准差进行操作。
- ©,对原始架构做了几处改动,包括在开始时删除了一些冗余操作,将b和B的添加移动到style的活动区域之外,并只调整每个feature map的标准差。
- (d)是修改后的架构,使方法能够用“demodulation”操作代替 AdaIN,并将demodulation操作应用于与每个卷积层相关的权重。
- (e)normalization中不再需要mean,只计算std即可。并将noise模块移除style box中
总的来看,styleGAN v2相比v1的几点改进主要在于:
1 Weight Demodulation
v1使用AdaIN来控制source vector w w w对生成人脸的影响程度,同BN层类似,其目的是对网络中间层的输出结果进行scale和shift,以增加网络的学习效果,避免梯度消失。相对于BN是学习当前batch数据的mean和variance,Instance Norm则是采用了单张图片。AdaIN则是使用learnable的scale和shift参数去对齐特征图中的不同位置,该方法能够显著地解耦(remarkable disentanglement) low-level的"style"特征和high-level的"content"特征,AdaIN的出现使得风格迁移任务从受限于一种风格或者需要lengthy optimization process的情况中摆脱了出来,仅通过归一化统计就可以将**风格(style)和内容(content)**结合起来。
生成器(Generator)通过将信息sneaking在这些层中来克服信息丢失的问题,但是这却带来了水印问题(water-droplet artifacts),但是判别器却无法判别出来,为了解决伪影的问题,v2将AdaIN重构为Weight Demodulation,处理流程如下:
- Conv 3x3前面的Mod std被用于对卷积层的权重进行scaling(缩放)
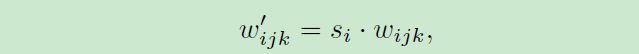
- 接着对卷积层的权重进行demod,并得到新的卷积层权重:


加一个小的 ϵ \epsilon ϵ是为了避免分母为0,保证数值稳定性。尽管这种方式与Instance Norm并非在数学上完全等价,但是weight demodulation同其它normalization 方法一样,使得输出特征图有着standard的unit和deviation。此外,将scaling参数挪为卷积层的权重使得计算路径可以更好的并行化,这种方式使得训练加速了约40%(从每秒处理37张图片到每秒处理61张图片)。
2 Progressive growth
StyleGAN图像由于progressive growing training (PGGAN)对鼻子和眼睛等面部特征有很强的位置偏好。Progressive growing指的是先训一个小分辨率的图像,训好了之后再逐步过渡到更高分辨率的图像。然后稳定训练当前分辨率,再逐步过渡到下一个更高的分辨率,是一种比较直观的对高分辨率图像合成的coarse-to-fine的方式。一般的GAN直接在训练超高分辨率( 102 4 2 1024^2 10242) 的图像生成上面相当不稳定
The discriminator will easily distinguish real and fake images, resulting in the generator unable to learn anything during training.
不同于StyleGAN第一代使用progressive growing的策略,StyleGAN2开始寻求其它的设计以便于让网络更深,训练更加稳定。对Resnet结构而言,网络加深是通过skip connection实现的。所以StyleGAN2采用了类似ResNet的残差连接结构(residual block)。使用双线性滤波对前一层进行上/下采样,并尝试学习下一层的残差值(residual value)。
受MSG-GAN的启发,StyleGAN2设计了一个新的架构来利用图像生成的多个尺度信息(不需要像progressive growing那样麻烦了),他们通过一个resnet风格的跳跃连接在低分辨率的特征映射到最终生成的图像。
3 Path Length Regularization
Path Length Regularization的意义是使得latent space的插值变得更加smooth和线性。简单来说,当在latent space中对latent vector进行插值操作时,我们希望对latent vector的等比例的变化直接反映到图像中去。即:“在latent space和image space应该有同样的变化幅度(线性的latent space)”。文中通过对生成器(Generator) 增加了一个loss项来达到这个目标。

简单来说就是计算生成器生成的图像对其latent vector的梯度(Jacobian矩阵), ∣ ∣ J w T y ∣ ∣ 2 ||J_w^Ty||_2 ∣∣JwTy∣∣2就是代码中 p l l e n g t h s pl_lengths pllengths, a a a为 p l m e a n v a r pl_mean_var plmeanvar的移动平均:
p l _ m e a n _ v a r = p l _ m e a n _ v a r + 0.01 × ( m e a n ( p l _ l e n g t h s ) − p l _ m e a n _ v a r ) pl\_mean\_var=\\ pl\_mean\_var + 0.01 \times (mean(pl\_lengths) - pl\_mean\_var) pl_mean_var=pl_mean_var+0.01×(mean(pl_lengths)−pl_mean_var)
这种方法"dramatically facilitates projecting images back into the latent space"(让图像得到更加线性的对应latent vector)。
#----------------------------------------------------------------------------
# Non-saturating logistic loss with path length regularizer from the paper
# "Analyzing and Improving the Image Quality of StyleGAN", Karras et al. 2019
def G_logistic_ns_pathreg(G, D, opt, training_set, minibatch_size, pl_minibatch_shrink=2, pl_decay=0.01, pl_weight=2.0):
_ = opt
latents = tf.random_normal([minibatch_size] + G.input_shapes[0][1:])
labels = training_set.get_random_labels_tf(minibatch_size)
fake_images_out, fake_dlatents_out = G.get_output_for(latents, labels, is_training=True, return_dlatents=True)
fake_scores_out = D.get_output_for(fake_images_out, labels, is_training=True)
loss = tf.nn.softplus(-fake_scores_out) # -log(sigmoid(fake_scores_out))
# Path length regularization.
with tf.name_scope('PathReg'):
# Evaluate the regularization term using a smaller minibatch to conserve memory.
if pl_minibatch_shrink > 1:
pl_minibatch = minibatch_size // pl_minibatch_shrink
pl_latents = tf.random_normal([pl_minibatch] + G.input_shapes[0][1:])
pl_labels = training_set.get_random_labels_tf(pl_minibatch)
fake_images_out, fake_dlatents_out = G.get_output_for(pl_latents, pl_labels, is_training=True, return_dlatents=True)
# Compute |J*y|.
pl_noise = tf.random_normal(tf.shape(fake_images_out)) / np.sqrt(np.prod(G.output_shape[2:]))
pl_grads = tf.gradients(tf.reduce_sum(fake_images_out * pl_noise), [fake_dlatents_out])[0]
pl_lengths = tf.sqrt(tf.reduce_mean(tf.reduce_sum(tf.square(pl_grads), axis=2), axis=1))
pl_lengths = autosummary('Loss/pl_lengths', pl_lengths)
# Track exponential moving average of |J*y|.
with tf.control_dependencies(None):
pl_mean_var = tf.Variable(name='pl_mean', trainable=False, initial_value=0.0, dtype=tf.float32)
pl_mean = pl_mean_var + pl_decay * (tf.reduce_mean(pl_lengths) - pl_mean_var)
pl_update = tf.assign(pl_mean_var, pl_mean)
# Calculate (|J*y|-a)^2.
with tf.control_dependencies([pl_update]):
pl_penalty = tf.square(pl_lengths - pl_mean)
pl_penalty = autosummary('Loss/pl_penalty', pl_penalty)
# Apply weight.
#
# Note: The division in pl_noise decreases the weight by num_pixels, and the reduce_mean
# in pl_lengths decreases it by num_affine_layers. The effective weight then becomes:
#
# gamma_pl = pl_weight / num_pixels / num_affine_layers
# = 2 / (r^2) / (log2(r) * 2 - 2)
# = 1 / (r^2 * (log2(r) - 1))
# = ln(2) / (r^2 * (ln(r) - ln(2))
#
reg = pl_penalty * pl_weight
return loss, reg
#-------------------------------------------------------------------------
小结
由于在GAN领域钻研的还不够深入,对于StyleGAN这种无论是工程上还是学术上都很有价值的大作,还是有些吃力,只能做一些生硬的阅读理解,可能还是跑代码比较简单吧哈哈~
欢迎关注 深度学习与数学 [获取免费的大数据、AI等相关的学习资源、经典和最新的深度学习相关的论文研读,算法和其他互联网技能的学习,概率论、线性代数等高等数学知识的回顾]
