【041】决策树相关算法实验

内容目录
一、数据集介绍二、决策树相关算法使用1、查看数据2、数据预处理3、决策树模型4、 tree.feature_importances_¶5、随机森林模型6、网格搜索找最好的参数三、决策树可视化
一、数据集介绍
•本数据集是采集于葡萄牙北部“Vinho Verde”葡萄酒的数据。由于隐私和物流问题,只有理化变量特征是可以进行使用的(例如,数据集中没有关于葡萄品种、葡萄酒品牌、葡萄酒销售价格等的数据)。
数据链接:https://pan.baidu.com/s/1LKdH6HuhQul0FFEq0Zgt-w
提取码:nmvz
数据集可探索、研究的方向?
•葡萄酒质量的分布情况如何?
•如何根据现有数据预测新的葡萄酒的质量?
•是否所有理化特征都与葡萄酒的质量相关?
二、决策树相关算法使用
1、查看数据
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score,precision_recall_fscore_support
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV,cross_val_score,train_test_split
import warnings
warnings.filterwarnings('ignore')#忽略各种报红警告
pd.set_option('display.max_columns', None)#显示所有列
pd.set_option('display.max_rows', None)#显示所有行
#设置value的显示长度为100,默认为50
pd.set_option('max_colwidth',100)
pd.set_option('display.width', 5000) #dataframe不换行
# k-means无监督的机器学习算法
df = pd.read_csv('.\winequality-white.csv')
print(df.head())
df.info()
RangeIndex: 4898 entries, 0 to 4897
Data columns (total 12 columns):
fixed acidity 4898 non-null float64
volatile acidity 4898 non-null float64
citric acid 4898 non-null float64
residual sugar 4898 non-null float64
chlorides 4898 non-null float64
free sulfur dioxide 4898 non-null float64
total sulfur dioxide 4898 non-null float64
density 4898 non-null float64
pH 4898 non-null float64
sulphates 4898 non-null float64
alcohol 4898 non-null float64
quality 4898 non-null int64
dtypes: float64(11), int64(1)
memory usage: 459.3 KB
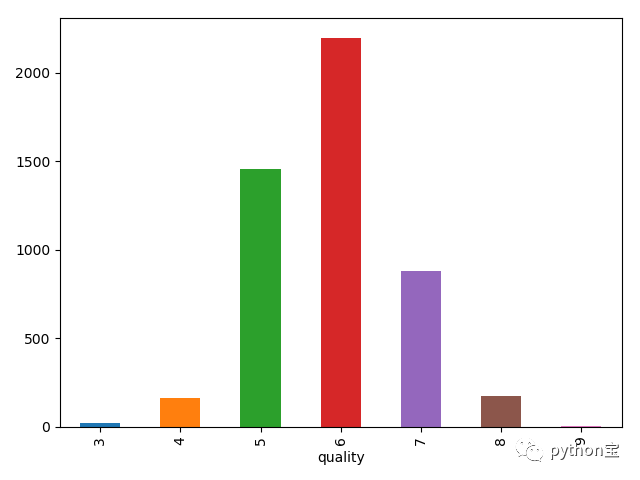
研究的目标为质量,以质量水平对葡萄酒进行分类。绘图观察类别:
df[['quality']].groupby('quality').size().plot(kind='bar')
plt.show()
2、数据预处理
X = df.drop(['quality'],axis=1)
from sklearn.preprocessing import StandardScaler
scale = StandardScaler()
x = scale.fit_transform(X)
y = df[['quality']]
x_train,x_test,y_train,y_test = train_test_split(X,y,test_size = 0.3)
3、决策树模型
DecisionTreeClassifier参数
criterion:gini或者entropy,前者是基尼系数,后者是信息熵。
splitter:best or random 前者是在所有特征中找最好的切分点 后者是在部分特征中,默认的”best”适合样本量不大的时候,而如果样本数据量非常大,此时决策树构建推荐”random” 。
max_features:None(所有),log2,sqrt,N 特征小于50的时候一般使用所有的
max_depth:int or None, optional (default=None) 设置决策随机森林中的决策树的最大深度,深度越大,越容易过拟合,推荐树的深度为:5-20之间。
min_samples_split:设置结点的最小样本数量,当样本数量可能小于此值时,结点将不会在划分。
min_samples_leaf:这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。
min_weight_fraction_leaf:这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝默认是0,就是不考虑权重问题。
max_leaf_nodes:通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。
class_weight:指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重,如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。
min_impurity_split:这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值则该节点不再生成子节点。即为叶子节点 。
#使用决策树模型
tree = DecisionTreeClassifier(criterion='entropy',max_depth=4,min_samples_leaf=5)
tree.fit(x_train,y_train)
pre_train = tree.predict(x_train)
pre_test = tree.predict(x_test)
train_acc = accuracy_score(y_train,pre_train)
print(train_acc ) #0.5364644107351225表明模型的预测能力很差
train_acc = accuracy_score(y_test,pre_test)
train_acc #0.5156462585034014表明模型的预测能力很差
从结果可以看出,分类效果不好,可以从数据本身特征找原因。决策树会用到feature_importances_ 做特征筛选。
4、 tree.feature_importances_¶
在用sklearn的时候经常用到feature_importances_ 来做特征筛选,那这个属性到底是啥呢。
importances = tree.feature_importances_
indices = np.argsort(importances)[::-1]
indices
# array([10, 1, 5, 7, 8, 2, 4, 0, 9, 6, 3], dtype=int64)
num_features = len(importances)
num_features # 11
5、随机森林模型
选择随机森林,发现训练集的分类结果有所提高,到时测试集提高不明显。
#随机森林
forse = RandomForestClassifier(max_depth= 10,min_samples_leaf=8,n_estimators=20,
criterion='entropy')
forse.fit(x_train,y_train)
pred_test = forse.predict(x_test)
pred_train = forse.predict(x_train)
train_accs = accuracy_score(y_train,pred_train)
test_accs = accuracy_score(y_test,pred_test)
train_accs,test_accs # (0.7184947491248541, 0.5952380952380952)
特征筛选
importances = forse.feature_importances_
std = np.std([tree.feature_importances_ for tree in forse.estimators_], axis=0)
indices = np.argsort(importances)[::-1]
indices#[10, 1, 5, 7, 4, 3, 8, 6, 2, 0, 9]
num_features = len(importances)
num_features#11
6、网格搜索找最好的参数
从模型结果,可以看出,网格搜索后分类结果更好了。
# 创建网格参数
param_grid = {
'bootstrap': [True],
'max_depth': [10, 20, 50],
'max_features': [len(features)],
'min_samples_leaf': [3, 4, 5],
'min_samples_split': [4, 8],
'n_estimators': [5, 10, 50] # of trees
}
#初始化森林
forest = RandomForestClassifier()
grid_search = GridSearchCV(estimator=forest,param_grid=param_grid,
n_jobs=-1,verbose=1,cv = 3)
grid_search.fit(x_train,y_train)
grid_search.best_params_
best_forse = grid_search.best_estimator_
best_forse.fit(x_train,y_train)
pretest = best_forse.predict(x_test)
pretrain = best_forse.predict(x_train)
btrain_accs = accuracy_score(y_train,pretrain)
btrain_accs#0.927362893815636
btest_accs = accuracy_score(y_test,pretest)
btest_accs#0.6333333333333333
三、决策树可视化


About Me:小婷儿
● 本文作者:小婷儿,专注于python、数据分析、数据挖掘、机器学习相关技术,也注重技术的运用
● 作者博客地址:https://blog.csdn.net/u010986753
● 本系列题目来源于作者的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
● 微信:tinghai87605025 联系我加微信群
● QQ:87605025
● QQ交流群py_data :483766429
● 公众号:python宝 或 DB宝
● 提供OCP、OCM和高可用最实用的技能培训
● 题目解答若有不当之处,还望各位朋友批评指正,共同进步

如果你觉得到文章对您有帮助,欢迎赞赏哦!有您的支持,小婷儿一定会越来越好!