校内实训项目经验
校内实训项目经验
-
-
- 《基于⽬标检测的交通标志识别》(采⽤yolov4模型)
-
-
- 1.数据集制作,
- 2.语音包制作
- 3.训练模型
- 4.图片识别转视频识别
- 5.实时识别并调用语音包功能
-
- 《AI图⽚篡改检测》(基于faster-rcnn模型)
-
-
- 1.重构voc2007、voc2012数据集
- 2.更换网络,服务器运行
- 3.flask框架了解
- 4.语义分割
-
- 深度学习--Pytorch构建栈式自编码器实现以图搜图任务(以cifar10数据集为例)
-
三个项目都是在校内实训时进行的,担任核心开发人员。
《基于⽬标检测的交通标志识别》(采⽤yolov4模型)
是实现五十五种类别的交通标志识别小程序,并进行语言提示,帮助驾驶人员更安全的驾驶。
1.数据集制作,
基于CCTSDB数据集,原来是三分类的包括:指示、禁止、警告。
基于三分类模型的97%的正确率转为尝试多分类识别。
我学习labelImg,制作所需的VOC格式数据集,修改xml文件形成五十五类别,再生成所需的类别标签以及文件路径,对于xml文件里面找到标签生成标注的交通标志的位置的文件(四个角的位置坐标)。
在后期解决类别不均衡的问题,我们更换了损失函数(二值交叉熵、均方误差等)并采用类别均衡方法,对TT100K数据集做了尝试,对于同类进行类别合并,提高精度。
加权交叉熵:对于样本数目较多的类别,除以一个数字n,按大小排序与之前的序列一样,仍然很大。然后取倒数,作为损失权重系数。所以样本数目多的类别,乘的权重系数小,对损失函数的贡献就小,削弱作用;此时样本数量小的权重系数就大,加强了对损失函数贡献。(中间的那些类别,权重系数就接近1,不受影响。![]()
二分类采用了sigmoid激活函数:多分类采用softmax来输出每一类概率值,在送入交叉熵损失函数。
通过ex 的函数曲线,可以看出将大于0的值扩大(x到y的映射)
多分类概率问题:softmax+交叉熵代价函数
作用:输出二分类或多分类任务中某一类的概率。
2.语音包制作
根据当时的类别标签制作语音包,通过pyttsx3库+百度API+pygame库制作成功。
pyttsx3库的语音比较生硬,然后尝试换百度api,直接调用生成。
先尝试playground库,编码异常,无法解决,更换了pygame库成功。
3.训练模型
计算图片输出格式
先定义几个参数
输入图片大小 W×W
Filter大小 F×F
步长 S
padding的像素数 P
于是我们可以得出
N = (W − F + 2P )/S+1
输出图片大小为 N×N
基于yolo模型,学习了其中darknet53网络。采用了预训练权重,每次训练采用前几轮训练好的模型参数进行训练,降低了loss值。
总共有 53 个卷积层,输入 image size 为 256(没有 fc 层,显然可以随意修改输入 size),最后得到的 feature map size 为 8x8,stride(步幅) 为 32(值得注意的是 5 次下采样,都不是通过 pooling 做的,而是通过 stride 为 2 的卷积层实现的,上图中蓝色框标出的位置,darknet-19 中是通过 max pooling)。

在检测任务中,将图中C0后面的平均池化、全连接层和Softmax去掉,保留从输入到C0部分的网络结构,作为检测模型的基础网络结构,也称为骨干网络。
4.图片识别转视频识别
基于opencv模块,增加对于视频进行交通标志识别的功能,对于录制的视频按帧截取识别,确定出候选框,筛选保留置信度最高的框,采用ffmpeg库在拼接成一个视频。
非极大值抑制
1)、假设有ABCDEF这么多个得分框(已经按照得分从小到大排序)。从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
2)、假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
3)、从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
4)、一直重复这个过程,找到所有曾经被保留下来的矩形框。
5.实时识别并调用语音包功能
调取摄像头,每3秒抓取一张图片,传入我们训练好的模型,返回候选框的坐标,在视频流上进行标注,同时返回类别,调用我们生成好的语音包提示。
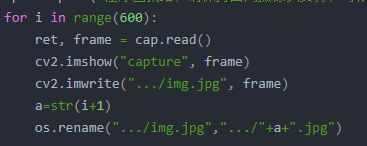
cap = cv2.VideoCapture(0)
cap.release()
0代表打开电脑内置摄像头,1代表打开usb插口摄像头。
当使用完之后,还需要一个关闭摄像头的函数。
ret, frame = cap.read()
read() 函数返回的ret是一个bool量,成功读取是true,否则返回false
frame返回的是读取到的图片,以数组的形式贮存
展示图片
cv2.imshow("capture", frame)
cv2.destroyAllWindows()
imshow() :是一个将数组形式的数据转化为图片并展示的函数。它会建立一个窗口,用于展示图片。
destroyAllWindows() :同样的,使用完成之后我们还需要一个关闭窗口的函数
想每隔10秒截取一帧,那么就相当于你要每隔( FPS * 10 )帧截取一帧图像!
因此,首先你需要知道你的视频的帧率(FPS)是多少:通过 openCV 获取一下即可:
cap = cv2.VideoCapture("./query_video/test_video_0.mp4")
FPS = cap.get(5) # 这个是获取视频帧率 参数为0-18
比如cap.get(0)是获取当前位置以毫秒为单位。
最后将两段代码结合起来就可以根据时间间隔来截取视频帧了:
import cv2
cap = cv2.VideoCapture("./query_video/test_video_0.mp4") #读一个视频
c = 1
timeRate = 10 # 截取视频帧的时间间隔(这里是每隔10秒截取一帧)
while(True):
ret, frame = cap.read()
FPS = cap.get(5)
if ret:
frameRate = int(FPS) * timeRate # 因为cap.get(5)获取的帧数不是整数,所以需要取整一下(向下取整用int,四舍五入用round,向上取整需要用math模块的ceil()方法)
if(c % frameRate == 0):
print("开始截取视频第:" + str(c) + " 帧")
# 这里就可以做一些操作了:显示截取的帧图片、保存截取帧到本地
cv2.imwrite("./capture_image/" + str(c) + '.jpg', frame) # 这里是将截取的图像保存在本地
c += 1
cv2.waitKey(0)
else:
print("所有帧都已经保存完成")
break
cap.release()
《AI图⽚篡改检测》(基于faster-rcnn模型)
该项目是基于智能图片篡改检测及还原技术的网站,包括图片篡改检测(支持jpg、png各种格式,不限制尺寸)、图片去除水印、视频篡改检测三个功能。
1.重构voc2007、voc2012数据集
将二分类细分成三分类,篡改分为copymove、splicing类别
生成所需的复制数据集,学习了canny边缘提取算法中的非极大值抑制和双阈值法筛选,对数据集进行处理。
2.更换网络,服务器运行
熟练的在服务器上搭建环境执行代码,同时基于faster-rcnn模型更换里面的vgg16网络换成reset50网络模型,模型速度由9s/iter提升到0.5s/iter
VGG16的卷积核
卷积层全部都是33的卷积核,用上图中conv3-xxx表示,xxx表示通道数。其步长为1,用padding=same填充。
池化层的池化核为22
卷积计算
1)输入图像尺寸为224x224x3,经64个通道为3的3x3的卷积核,步长为1,padding=same填充,卷积两次,再经ReLU激活,输出的尺寸大小为224x224x64
2)经max pooling(最大化池化),滤波器为2x2,步长为2,图像尺寸减半,池化后的尺寸变为112x112x64
3)经128个3x3的卷积核,两次卷积,ReLU激活,尺寸变为112x112x128
4)max pooling池化,尺寸变为56x56x128
5)经256个3x3的卷积核,三次卷积,ReLU激活,尺寸变为56x56x256
6)max pooling池化,尺寸变为28x28x256
7)经512个3x3的卷积核,三次卷积,ReLU激活,尺寸变为28x28x512
8)max pooling池化,尺寸变为14x14x512
9)经512个3x3的卷积核,三次卷积,ReLU,尺寸变为14x14x512
10)max pooling池化,尺寸变为7x7x512
11)然后Flatten(),将数据拉平成向量,变成一维51277=25088。
11)再经过两层1x1x4096,一层1x1x1000的全连接层(共三层),经ReLU激活
12)最后通过softmax输出1000个预测结果
3.flask框架了解
学习flask,实现网页上传图片功能,搭建人机交互界面。
它是一个用python语言基于Werkzeug工具箱编写的轻量级web开发框架,它主要面向需求简单,项目周期短的小应用。
所有Flask程序必须有一个程序实例。
Flask调用视图函数后,会将视图函数的返回值作为响应的内容,返回给客户端。一般情况下,响应内容主要是字符串和状态码。
用户向浏览器发送http请求,web服务器把客户端所有请求交给Flask程序实例,程序用Werkzeug来做路由分发,每个url请求,找到具体的视图函数。路由的实现是通过route装饰器实现的,调用视图函数,获取数据后,把数据传入模块中,模块引擎渲染响应的数据,由Flask返回给浏览器。
flask数据库:Web应用中普遍使用的是关系模型的数据库,关系型数据库把所有的数据都存储在表中,表用来给应用的实体建模,表的列数是固定的,行数是可变的。它使用结构化的查询语言。关系型数据库的列定义了表中表示的实体的数据属性。
用户在浏览器上请求地址,浏览器将请求发送给视图层,视图层根据请求地址分配对应的视图函数,视图函数通过模型层查找数据,并将数据传送给模板,最后模板层将数据响应在网页上。
4.语义分割
学习了语义分割,但是数据集文字类别训练较少,不能较好的框出文字修改区域。
图像语义分割(semantic segmentation),从字面意思上理解就是让计算机根据图像的语义来进行分割,例如让计算机在输入下面左图的情况下,能够输出右图。