bert4keras、transformers 加载预训练bert模型、句向量cls,字向量提取;tokenizer使用
1、bert4keras
分词器 Tokenizer

from bert4keras.models import build_transformer_model
from bert4keras.tokenizers import Tokenizer
import numpy as np
config_path = '/Users/lonng/Desktop/v+/xl/chinese_L-12_H-768_A-12/bert_config.json'
checkpoint_path = '/Users/lonng/Desktop/v+/xl/chinese_L-12_H-768_A-12/bert_model.ckpt'
dict_path = '/Users/lonng/Desktop/v+/xl/chinese_L-12_H-768_A-12/vocab.txt'
tokenizer = Tokenizer(dict_path, do_lower_case=True) # 建立分词器
model = build_transformer_model(config_path, checkpoint_path) # 建立模型,加载权重
# 编码测试
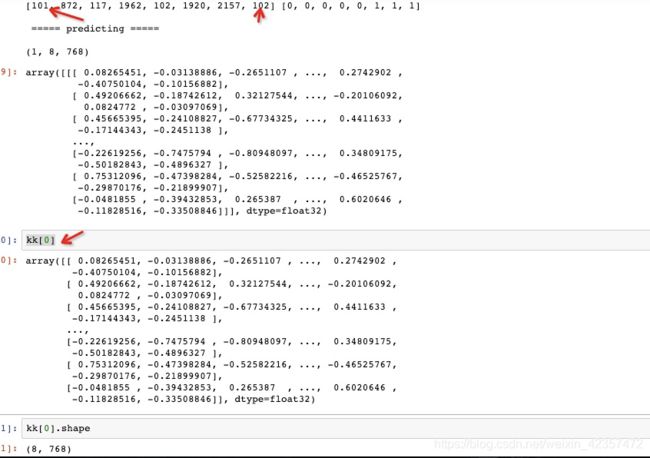
token_ids, segment_ids = tokenizer.encode('语言模型')
print('\n ===== predicting =====\n')
print(model.predict([np.array([token_ids]), np.array([segment_ids])]))
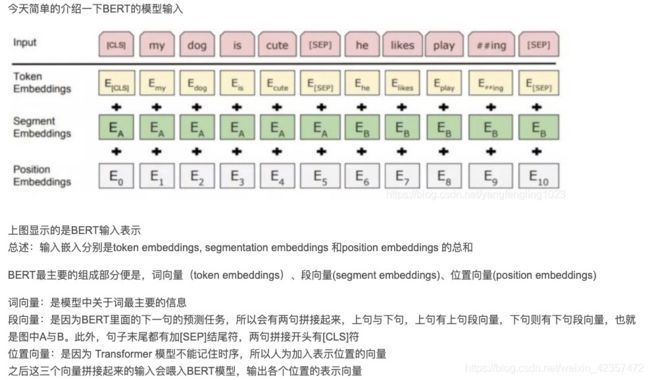
同时输入连续句,token_ids 词表对应index, segment_ids 段向量用于预测下一句nsp
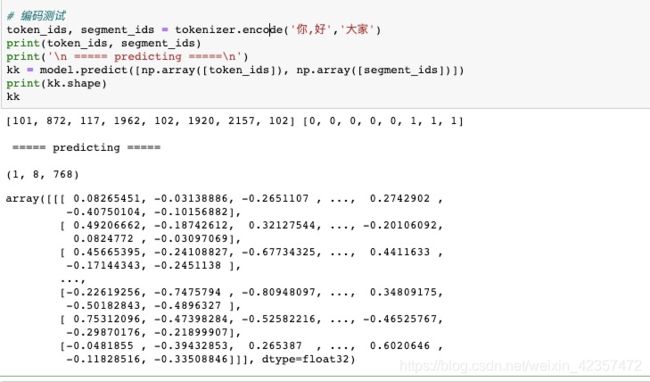
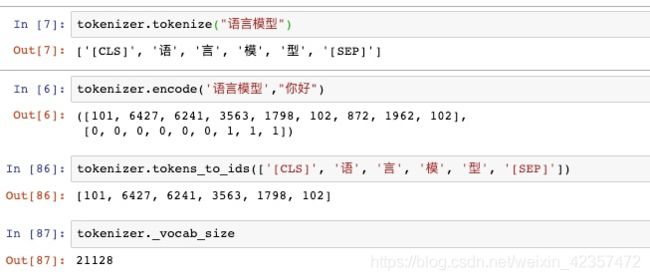
句向量cls,字向量提取(101 cls表示句向量,其他字向量也可以对应取出)
cls句向量:kk[:,0,:]、 kk[:,0]或者kk[0][0,:]
加载t5-pegasus
参考:https://github.com/ZhuiyiTechnology/t5-pegasus
import json
import numpy as np
from tqdm import tqdm
from bert4keras.backend import keras, K
from bert4keras.layers import Loss
from bert4keras.models import build_transformer_model
from bert4keras.tokenizers import Tokenizer
from bert4keras.optimizers import Adam
from bert4keras.snippets import sequence_padding, open
from bert4keras.snippets import DataGenerator, AutoRegressiveDecoder
from keras.models import Model
# from rouge import Rouge # pip install rouge
from nltk.translate.bleu_score import sentence_bleu, SmoothingFunction
import jieba
jieba.initialize()
# 基本参数
max_c_len = 256
max_t_len = 32
batch_size = 32
epochs = 40
# 模型路径
config_path = r'D:\sie\chinese_t5_pegasus_small\config.json'
checkpoint_path = r'D:\sie\chinese_t5_pegasus_small\model.ckpt'
dict_path = r'D:\se\chinese_t5_pegasus_small\vocab.txt'
# 构建分词器
tokenizer = Tokenizer(
dict_path,
do_lower_case=True,
pre_tokenize=lambda s: jieba.cut(s, HMM=False)
)
t5 = build_transformer_model(
config_path=config_path,
checkpoint_path=checkpoint_path,
model='t5.1.1',
return_keras_model=False,
name='T5',
)
encoder = t5.encoder
decoder = t5.decoder
model = t5.model
c_token_ids, _ = tokenizer.encode("你好世界人民", maxlen=max_c_len)
c_encoded = encoder.predict(np.array([c_token_ids]))[0]

2、transformers
transformers安装需要安装好tf和torch,tf这里选择2X
tensorflow 2.2.0
torch 1.9.0
transformers 4.10.2
读取hub使用:
参考:https://huggingface.co/bert-base-uncased
这里tf是指tf格式,pt是指pytorch格式
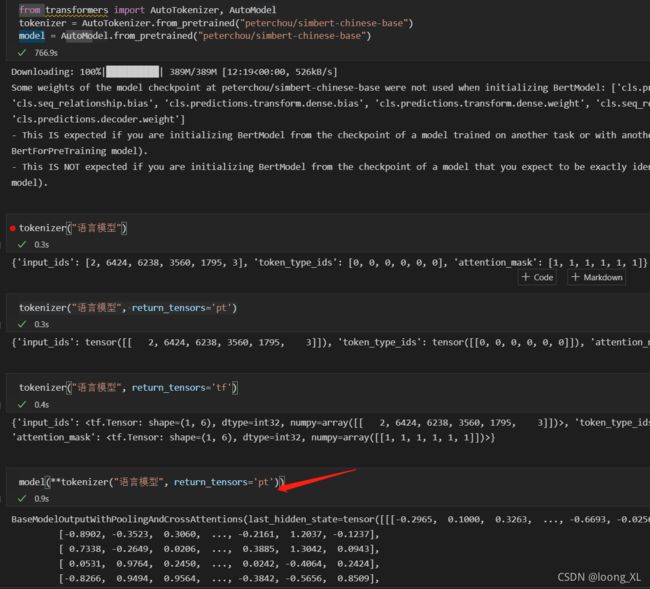
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("peterchou/simbert-chinese-base")
model = AutoModel.from_pretrained("peterchou/simbert-chinese-base")
tokenizer("语言模型", return_tensors='pt')
#tokenizer("语言模型", return_tensors='tf')
model(**tokenizer("语言模型", return_tensors='pt'))
输出:last_hidden_state:tokenizer后每个字的向量
pooler_output:cls向量
参考:https://github.com/huggingface/transformers/tree/v3.4.0

***读取pytorch 训练的预训练模型

tokenizer
1)encode



2)decode
