机器学习模型正则化与岭回归、LASSO回归
文章目录
- 模型正则化
- 岭回归
-
- 使用多项式回归模型
- 使用岭回归模型
- LASSO回归
-
- 岭回归与LASSO回归区别
模型正则化
为了解决机器学习中方差过大问题,常用的手段是模型正则化,其原理是限制多项式模型中特征系数 θ \theta θ,不让其过大,导致过拟合。
在线性回归模型中,目标是使得损失函数尽可能小
J ( θ ) = ∑ i = 1 m ( y ( i ) − θ 0 − θ 1 X 1 ( i ) − … … − θ n X n ( i ) ) 2 J(\theta)=\sum_{i=1}^m (y^{(i)}-\theta_0-\theta_1X^{(i)}_1-……-\theta_nX_n^{(i)})^2 J(θ)=i=1∑m(y(i)−θ0−θ1X1(i)−……−θnXn(i))2
当模型过拟合时, θ \theta θ就会非常大,当损失函数 J ( θ ) J(\theta) J(θ)加上
α 1 2 ∑ i = 1 n θ i 2 \alpha \frac{1}{2} \sum_{i=1}^n \theta^2_i α21i=1∑nθi2
此时要使得损失函数尽可能小,就要考虑到 θ \theta θ 尽可能小,损失函数加上了 α 1 2 ∑ i = 1 n θ i 2 \alpha \frac{1}{2} \sum_{i=1}^n \theta^2_i α21∑i=1nθi2 即为加入正则化项。
岭回归
损失函数加正则化模型 α 1 2 ∑ i = 1 n θ i 2 \alpha \frac{1}{2} \sum_{i=1}^n \theta^2_i α21∑i=1nθi2 的方式,这种模型称为岭回归。
使用多项式回归模型
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
x = np.random.uniform(-3,3,size=100)
y = 0.5*x +3 +np.random.normal(0,1,size=100)
X = x.reshape(-1,1)
plt.scatter(x,y)
x_train,x_test,y_train,y_test = train_test_split(X,y)
def plt_model(model):
plt_x = np.linspace(-3,3,100).reshape(100,1)
y_predict = model.predict(plt_x)
plt.scatter(x,y)
plt.plot(plt_x[:,0],y_predict)
plt.show()
def PolynomialDegression(degree):
return Pipeline([
("poly_reg",PolynomialFeatures(degree)),
("std",StandardScaler()),
("liner_reg",LinearRegression())
])
poly_reg = PolynomialDegression(degree=20)
poly_reg.fit(x_train,y_train)
plt_model(poly_reg)
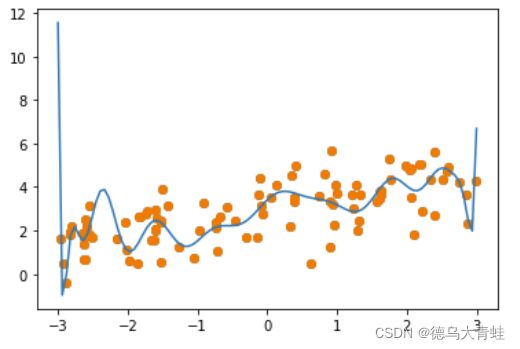
使用岭回归模型
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge
x = np.random.uniform(-3,3,size=100)
y = 0.5*x +3 +np.random.normal(0,1,size=100)
X = x.reshape(-1,1)
plt.scatter(x,y)
x_train,x_test,y_train,y_test = train_test_split(X,y)
def plt_model(model):
plt_x = np.linspace(-3,3,100).reshape(100,1)
y_predict = model.predict(plt_x)
plt.scatter(x,y)
plt.plot(plt_x[:,0],y_predict)
plt.show()
def RidgeRegression(degree,aplpha):
return Pipeline([
("poly_reg",PolynomialFeatures(degree)),
("std",StandardScaler()),
("ridge",Ridge())
])
ridge = RidgeRegression(20,10000)
ridge.fit(x_train,y_train)
plt_model(ridge)
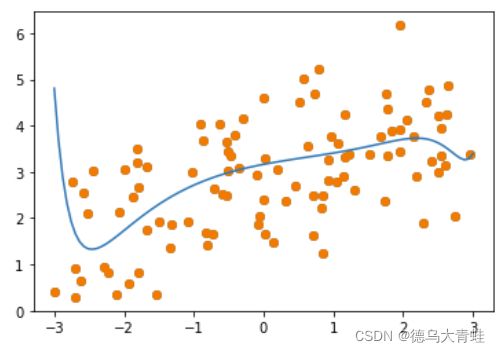
从结果可以看出,使用岭回归模型训练,超参数 a l p h a alpha alpha取值非常重要,当 a l p h a alpha alpha取适合的值时,能非常有效的降低方差。
LASSO回归
LASSO回归与岭回归不同点是使得下面的目标函数尽可能小
J ( θ ) = ∑ i = 1 m ( y ( i ) − θ 0 − θ 1 X 1 ( i ) − … … − θ n X n ( i ) ) 2 + α ∑ i = 1 n ∣ θ ∣ J(\theta)=\sum_{i=1}^m (y^{(i)}-\theta_0-\theta_1X^{(i)}_1-……-\theta_nX_n^{(i)})^2 + \alpha \sum_{i=1}^n |\theta| J(θ)=i=1∑m(y(i)−θ0−θ1X1(i)−……−θnXn(i))2+αi=1∑n∣θ∣
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Lasso
x = np.random.uniform(-3,3,size=100)
y = 0.5*x +3 +np.random.normal(0,1,size=100)
X = x.reshape(-1,1)
x_train,x_test,y_train,y_test = train_test_split(X,y)
def plt_model(model):
plt_x = np.linspace(-3,3,100).reshape(100,1)
y_predict = model.predict(plt_x)
plt.scatter(x,y)
plt.plot(plt_x[:,0],y_predict,color='r')
plt.show()
def LassoRegression(degree,alpha):
return Pipeline([
("poly_reg",PolynomialFeatures(degree)),
("std",StandardScaler()),
("lasso",Lasso(alpha=alpha))
])
lasso = LassoRegression(20,0.1)
lasso.fit(x_train,y_train)
plt_model(lasso)
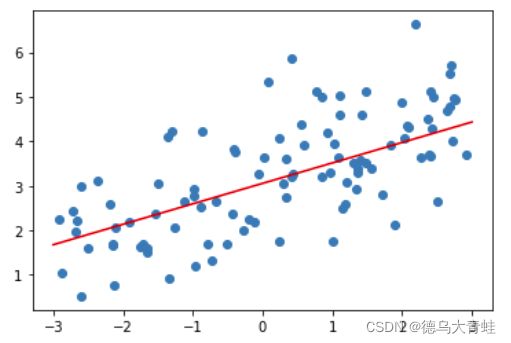
岭回归与LASSO回归区别
- 岭回归训练得到的模型很难得到一条直线,始终是保持弯曲的形状,而LASSO回归,更趋向是一条直线
- 岭回归是使得每个 θ \theta θ趋于0,但不等于0,所以岭回归训练得到的模型始终保持弯曲形状;LASSO趋向于使得一部分的 θ \theta θ值为0,所以LASSO训练出来的模型趋向于一条直线