单目RGB人脸识别
单目RGB人脸识别
一、简介
人脸识别在业内已经算是比较成熟的了,但是单目rgb活体,除了配合式的方法,其实是一个比较难的问题,这篇文章尽量总结开源的人脸检测、人脸识别、单目rgb活体的多种算法,与君共勉。
二、人脸检测算法
如下是目前比较常用的人脸检测算法的对比分析:
| 算法 | 发表时间 | 精度(mAP) | 预测输出 | 特点 | 论文地址 |
|---|---|---|---|---|---|
| MTCNN | 2016年 | 94.4%(fddb), 85.1%(wider_face,test,easy) | 人脸框+五个关键点 | 三层级联方式预测 | https://arxiv.org/ftp/arxiv/papers/1604/1604.02878.pdf |
| FaceBoxes | 2017年 | 96.0%(fddb), 83.9%(wider_face,test,easy) | 人脸框 | 对小尺寸人脸检测不佳,速度不受人脸数量影响 | https://arxiv.org/pdf/1708.05234.pdf |
| CenterFace | 2019年 | 98.0%(fddb), 93.2%(wider_face,test,easy) | 人脸框+五个关键点 | 相比其他算法,低性能cpu检测速度急剧下降 | https://arxiv.org/ftp/arxiv/papers/1911/1911.03599.pdf |
| RetinaFace | 2019年 | 96.3%(wider_face,test,easy) | 人脸框+五个关键点 | 关键点预测作为辅助分支,引入自监督 | https://arxiv.org/pdf/1905.00641.pdf |
三、人脸识别算法
如下是目前比较常用的人脸识别算法的对比分析:
| 算法 | 发表时间 | 精度(mAP) | 特点 | 论文地址 |
|---|---|---|---|---|
| ArcFace | 2018年 | 99.83%(LFW) | 性能高,复杂性低,训练效率高 | https://arxiv.org/pdf/1801.07698.pdf |
| MobileFaceNet | 2018年 | 99.28%(LFW) | 模型只有4M, 准确率高 | https://arxiv.org/ftp/arxiv/papers/1804/1804.07573.pdf |
四、单目RGB活体检测算法
单目RGB活体检测包含两种方案:基于RGB单帧活体检测,基于RGB视频/连续多帧活体检测。
4.1 数据集
活体检测研究方向在最近几年才火,且活体数据收集难度较大,导致很多数据集的数据单一,数据量较小,如下是已有的部分数据集:

ECCV20|北交、商汤、港中文发布大型人脸反欺诈数据集CelebA-Spoof,好像还没有完全开源,期待中。
活体检测性能评判指标:等错误率(EER),攻击呈现分类错误率(APCER),善意呈现分类错误率(BPCER)和ACER =(APCER + BPCER)/ 2。 交叉测试评估:HTER。
4.2 Face Spoofing Detection Using Colour Texture Analysis(单帧RGB),2016
Oulu CMVS的产物,算是传统方法中的战斗机。原理是活体与非活体,在RGB空间里比较难区分,但在其他颜色空间里的纹理有明显差异,即使用HSV空间人脸多级LBP特征 + YCbCr空间人脸LPQ特征,进行多通道特征融合分析,最后使用SVM进行分类。

Replay-Attack, CASIA, MSU数据集上测试结果如下:
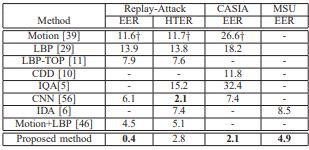
由于数据集太小,测试结果并不能很好地反映实际算法性能。
论文地址:https://www.researchgate.net/profile/Jukka_Komulainen/publication/301571761_Face_Spoofing_Detection_Using_Colour_Texture_Analysis/links/5c028dfa92851c63cab31bda/Face-Spoofing-Detection-Using-Colour-Texture-Analysis.pdf
4.3 Face Anti-Spoofing: Model Matters, so Does Data(单帧视频),2019
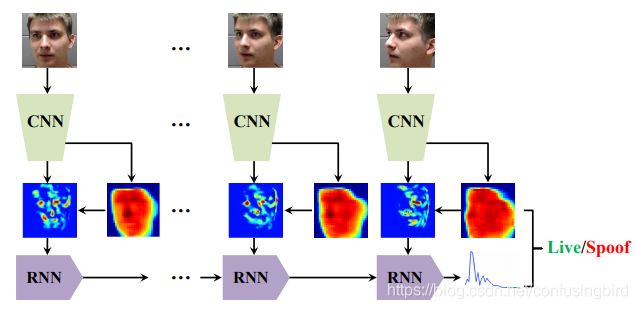
腾讯AI发表在CVPR2019的工作:1)提出一个很容易操作的收集大量数据的方法,包含人工伪造攻击样本和在伪造的基础上扩增;2)提出新模型,用时空+注意力机制来融合全局时域信息和局部空间信息,用于分析模型的可解释行为;3)明显提升了多个AS数据集的SOTA。
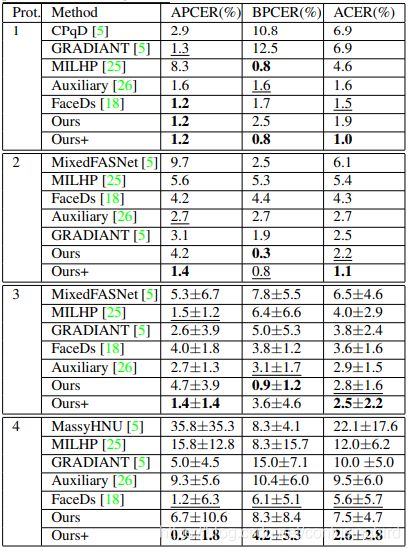
Oulu测试集上测试结果如下:
论文链接:https://openaccess.thecvf.com/content_CVPR_2019/papers/Yang_Face_Anti-Spoofing_Model_Matters_so_Does_Data_CVPR_2019_paper.pdf
4.4 CVPR2020单模态冠军CeFA(单帧视频):Creating Artificial Modalities to Solve RGB Liveness
在本文工作中,通过引入具有丰富特征的人工形态,如光流和等级池化等,将视频序列分类问题简化为图像分类问题。并提出了一种序列扩增,将真实轨迹转换为虚假轨迹,从而增加假样本的数量。最后,使用一个非常简单的融合神经网络架构与浅骨干结合不同的模式在一起。

测试集CASIA-SURF CeFa上测试结果如下:
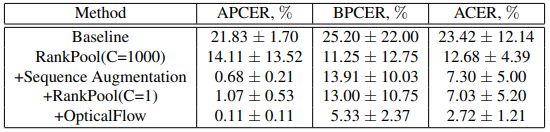
论文链接:https://arxiv.org/pdf/2006.16028v1.pdf
4.5 工业级开源活体(单帧RGB):小视科技工业级静默活体检测算法
小视科技团队开源的基于 RGB 图像的活体检测模型,是专门面向工业落地场景,兼容各种复杂场景下的模型。该自研的剪枝轻量级模型,运算量为 0.081G,在麒麟 990 5G 芯片上仅需 9ms。同时基于 PyTorch 训练的模型能够灵活地转化成 ONNX 格式,实现全平台部署。
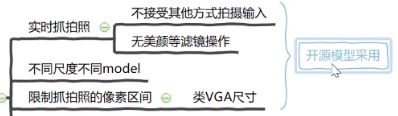
作者训练集为1500万,且拍摄的数据有如下图依赖,预测时使用多模型联合的方式增大准确率,开源模型包含mobilenet, MiniFASNetV1, MiniFASNetV2。
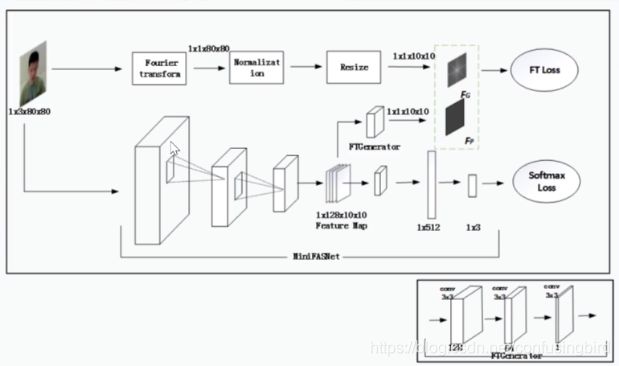
算法框架如下:
自备测试集上测试结果如下:

小视科技的工业级活体检测方案讲解:https://www.bilibili.com/video/av371471482/
五、分析
5.1 人脸检测算法+人脸识别算法分析
上述提到的4种人脸检测算法和2种识别算法,尽管在不同数据集的mAP上存在一定差距,但是由于丰巢柜机拍摄的照片的特点(人脸数目少,人脸尺寸较大),可以随意选取其中一种人脸检测算法和一种人脸识别算法进行组合完成人脸识别方案。如下是上述论文RetinaFace里面验证的算法性能:

5.2 单目RGB活体检测算法分析
调研过程中的RGB单帧方案(4.4)对比视频方案(4.3)如下:
| 方案 | 输入 | 约束条件 | 训练数据量 | 活体检测速度 | 针对攻击种类 |
|---|---|---|---|---|---|
| RGB单帧方案 | 单张实时拍摄的RGB图片 | 多 | 上千万(小视科技1500万) | 速度快,最快9ms | 侧重打印和屏幕攻击 |
| RGB视频/连续多帧方案 | 实时视频的多帧 | 较少 | 大多是上万个视频 | 较慢,需要多帧人脸检测 | 所有常见攻击 |
根据3D目标检测方向的论文,曾经思考过单帧RGB图像估计深度图,结合估计深度图和RGB图像进行活体检测的方案。但是通过调研发现,单帧RGB图像估计深度图太不准确,这也是单目3D目标检测问题一直以来精度在10%左右的原因,具体调研报告链接:https://blog.csdn.net/confusingbird/article/details/109677674
六、总结
- 推荐人脸检测算法和人脸识别算法方案:
RetinaFace + ArcFace
源码链接insightface:https://github.com/deepinsight/insightface
- 单目RGB活体检测算法的选取需根据摄像头的实际情况来决定,可选方案:
- 类似上述报告中4.3论文,基于RGB视频/连续多帧的活体检测方案
- 类似上述报告中4.4小视科技的工业级方案,基于RGB单帧的活体检测方案,但要符合多种约束条件。
活体检测数据集CASIA-Surf-CeFA下载见: https://blog.csdn.net/confusingbird/article/details/111250457