Intel Movidius神经元计算棒加速-Object Detection API训练MobileNet-SSD模型全流程记录
这篇文章记录在台式机ubuntu18.04下搭建Object Detection API框架,以及Intel Movidius神经元计算棒2代环境,并使用自己的训练集对MobileNet-SSD网络进行训练调参与测试,以及VPU加速推理的全过程。这里对过程中遇到的各种血泪深坑以及奇葩问题进行完整记录,便于后续归档与复现。
Object Detection API训练MobileNet-SSD模型,以及使用Intel Movidius神经元计算棒加速完整步骤
-
-
- 一/ 搭建Object Detection API 框架与相关环境
-
- 1)Anaconda3 安装与配置
- 2)Cuda和Cudnn 安装与配置
-
- 2.1)Cuda9.0安装
- 2.2)Cudnn7.1.4安装
- 3)Tensorflow-gpu 安装与配置
-
- 3.1)创建Conda虚拟环境
- 3.2)安装Tensorflow-gpu
- 4)Object Detection API 框架搭建
- 二/ 制作训练-测试数据集,训练MobileNet-SSD网络模型
-
- 1)按照VOC数据集格式制作训练-测试数据集
-
- 1.1)制作VOC格式数据集
- 1.2).record格式的样本生成
- 2)训练MobileNet-SSD网络模型
-
- 2.1)配置.config文件
- 2.2)启动训练
- 2.3)测试训练效果
- 三/ 搭建OpenVINO™ toolkit 框架与相关环境,以及VPU加速推理
-
- 1)搭建OpenVINO™ toolkit 框架与环境
-
- 1.1)安装OpenVINO™ toolkit
- 1.2)配置神经元计算棒2代硬件驱动
- 1.3)测试安装
- 2)使用VPU加速推理训练好的tensorflow模型
-
- 2.1)将自己训练好的Tensorflow模型转换为IR模型
- 2.2)将IR推理模型转换为二进制blob文件格式
- 2.3)使用VPU进行实际加速推理测试
-
我这里PC端基础环境为
Ubuntu 18.04,OpenCV 3.4.13,python 3.6.8。
之前原本一直用的都是Caffe环境,结果系统升级到18.04后,重新编译caffe一直没能编译成功,试便了国内外各种论坛里的帖子,耗时整整一星期,把boost依赖库都编出花了还是没能解决…主要的问题在于编译到最后一步会报如下错误,这里记录一下:
.build_release/lib/libcaffe.so: undefined reference to boost::re_detail_106501::cpp_regex_traits_implementation::transform(char const*, char const*) const
因此最后就放弃Caffe环境改用Tensorflow了,但可能是运气不大行,tf的坑貌似我也全部踩遍…
真心建议,不要轻易升级系统,从16.04升级后真的很多深坑,血泪的教训QAQ…
正文开始之前先总结一下我在Ubuntu18.04系统下安装依赖包时遇到的相关问题:
问题记录-01 -------------------------------------------------------------------------------------------------------
当我升级系统后安装新的依赖包非常慢,于是我更换了国内的阿里源,更换步骤为:
(1)备份原来的源,将以前的源备份一下,以防以后可以用的。
sudo cp /etc/apt/sources.list /etc/apt/sources_init.list
(2)更换源:
sudo gedit /etc/apt/sources.list
使用gedit打开文档,将下边的阿里源复制进去,然后点击保存关闭。阿里官方源 (Ubuntu 18.04):
# See http://help.ubuntu.com/community/UpgradeNotes for how to upgrade to
# newer versions of the distribution.
deb http://cn.archive.ubuntu.com/ubuntu/ bionic main restricted
## Major bug fix updates produced after the final release of the
## distribution.
# deb-src http://cn.archive.ubuntu.com/ubuntu/ bionic-updates main restricted
## N.B. software from this repository is ENTIRELY UNSUPPORTED by the Ubuntu
## team. Also, please note that software in universe WILL NOT receive any
## review or updates from the Ubuntu security team.
deb http://cn.archive.ubuntu.com/ubuntu/ bionic universe
# deb-src http://cn.archive.ubuntu.com/ubuntu/ bionic universe
# deb-src http://cn.archive.ubuntu.com/ubuntu/ bionic-updates universe
## N.B. software from this repository is ENTIRELY UNSUPPORTED by the Ubuntu
## team, and may not be under a free licence. Please satisfy yourself as to
## your rights to use the software. Also, please note that software in
## multiverse WILL NOT receive any review or updates from the Ubuntu
## security team.
deb http://cn.archive.ubuntu.com/ubuntu/ bionic multiverse
# deb-src http://cn.archive.ubuntu.com/ubuntu/ bionic multiverse
# deb-src http://cn.archive.ubuntu.com/ubuntu/ bionic-updates multiverse
## N.B. software from this repository may not have been tested as
## extensively as that contained in the main release, although it includes
## newer versions of some applications which may provide useful features.
## Also, please note that software in backports WILL NOT receive any review
## or updates from the Ubuntu security team.
# deb-src http://cn.archive.ubuntu.com/ubuntu/ bionic-backports main restricted universe multiverse
## Uncomment the following two lines to add software from Canonical's
## 'partner' repository.
## This software is not part of Ubuntu, but is offered by Canonical and the
## respective vendors as a service to Ubuntu users.
# deb http://archive.canonical.com/ubuntu bionic partner
# deb-src http://archive.canonical.com/ubuntu bionic partner
# deb-src http://security.ubuntu.com/ubuntu bionic-security main restricted
# deb-src http://security.ubuntu.com/ubuntu bionic-security universe
# deb-src http://security.ubuntu.com/ubuntu bionic-security multiverse
deb http://security.ubuntu.com/ubuntu/ bionic-security restricted multiverse main universe
deb http://cn.archive.ubuntu.com/ubuntu/ bionic-updates restricted multiverse main universe
deb http://archive.ubuntu.com/ubuntu/ trusty main universe restricted multiverse
# deb-src http://archive.ubuntu.com/ubuntu/ trusty main universe restricted multiverse
(3)更新源:
sudo apt-get update
修复损坏的软件包,尝试卸载出错的包,重新安装正确版本:
sudo apt-get -f install xxxxxxx
问题记录-02 -------------------------------------------------------------------------------------------------------
无法获得锁 /var/lib/dpkg/lock-frontend - open (11: 资源暂时不可用)
如果在apt get安装依赖包时报这个错误,首先查看:
ls /var/lib/dpkg/lock-frontend
然后将其删除:
sudo rm -r -f /var/lib/dpkg/lock-frontend
如果依然报错,删除:
sudo rm -r -f /var/lib/dpkg/lock
问题记录-03 -------------------------------------------------------------------------------------------------------
ubuntu18.04 处理依赖包问题,遇到 Depends: python3-software-properties (= 0.96.20.9)
应该是因为源本身有问题,例如我升级为Ubuntu 18.04后,如果替换为国内16.04的阿里源就是遇到上述问题,查阅相关文档后替换为Ubuntu 18.04的阿里官方源问题得以解决。
问题记录-04 -------------------------------------------------------------------------------------------------------
pip安装依赖包时,报错ModuleNotFoundError: No module named 'pip._internal'
当安装了Python3.6后,我通过修改默认为Python3.6,结果pip就不能用了,一直报错如下:
Traceback (most recent call last):
File "/usr/local/bin/pip", line 7, in <module>
from pip._internal import main
ModuleNotFoundError: No module named 'pip._internal'
输入pip更新指令python -m pip install --upgrade pip,问题得以解决。
如果输入运行后依旧继续出现错误“no module named pip”,则运行以下指令:
python -m ensurepip
easy_install pip
继续报错:No module named “ensurepip” “ easy_install ”
则可以通过源码编译安装,命令行如下:
wget https://bootstrap.pypa.io/get-pip.py --no-check-certificate
sudo python get-pip.py
pip --version
------------------------------------------------------------------------------------------------------------------------
一/ 搭建Object Detection API 框架与相关环境
1)Anaconda3 安装与配置
(1)下载安装包,官网下载地址:https://www.anaconda.com/download/#linux
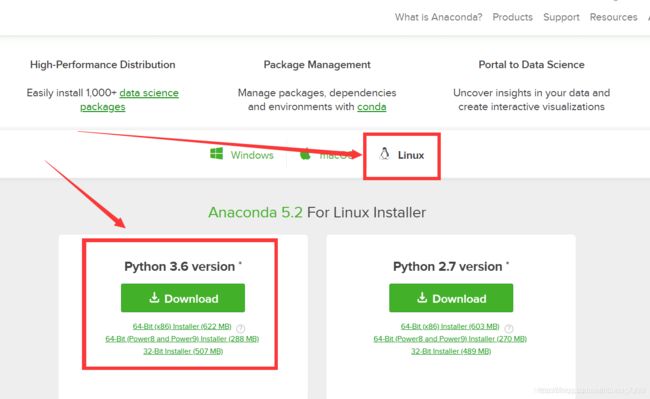 (2)下载完之后是后缀.sh文件,在终端输入:
(2)下载完之后是后缀.sh文件,在终端输入:
bash Anaconda3-5.1.0-Linux-x86_64.sh

点击回车按钮进行后续安装。
(3)终端输入python查看版本,如果默认不是python3,则在终端输入:
sudo update-alternatives --install /usr/bin/python python /usr/bin/python2 100
sudo update-alternatives --install /usr/bin/python python /usr/bin/python3 150
执行完上述两行命令之后在终端输入python,如果第一行信息是3.6,则成功。效果图如下:
 如果要切换到Python2,执行:
如果要切换到Python2,执行:
sudo update-alternatives --config python
(4)将Python添加到环境变量中,如果在安装Anaconda的过程中没有将安装路径添加到系统环境变量中,需要在安装后手工添加。
打开bashrc文件:sudo gedit ~/.bashrc,在文件末尾处添加以下语句:
export PATH=/home/XXX/anaconda3/bin:$PATH XXX为自己的用户名
最后在终端输入source ~/.bashrc,使环境变量立即生效。
至此,输入conda -V显示版本号即为安装成功。如果没有成功,重启系统即可。
也可以在终端输入ecoh $PATH查看已有的环境变量 ,确认输出是否已经有Anaconda路径。
2)Cuda和Cudnn 安装与配置
最终我这里安装了
Cuda9.0与Cudnn7.1.4,这里遇到了很多的问题。
总结一下就是首先cuda的版本一定要和驱动的版本相匹配,不然一切都是白做。我的驱动版本安装的是390,对应的cuda应该是9.1,但是Cuda9.1版本的tensorflow-gpu只有部分版本的轮子,并且很多博文都说其实Cuda9.1对tensorflow-gpu并不支持。
我安装到后面Object Detection API那里测试时也验证了这个说法,所以我又回来卸载了Cuda9.1,重新安装了cuda9.0版本。

问题记录-05 -------------------------------------------------------------------------------------------------------
如何卸载CUDA旧版本:
sudo apt-get remove cuda
sudo apt-get autoclean
sudo apt-get remove cuda*
cd /usr/local/
sudo rm -r cuda-9.1
此外,如果是采用deb格式文件的安装方式,需要在源中将旧版本的CUDA取消勾选,例如当卸载完CUDA9.1后需要将下图这个界面与CUDA9.1相关的驱动删掉,否则后续安装新的CUDA版本时会直接链接到旧版本驱动中,导致无法正确安装新版本。

----------------------------------------------------------------------------------------------------------------------------
2.1)Cuda9.0安装
Ubuntu18.04自带了NVIDIA驱动,但是它没有安装完整,不能在终端使用nvidia-smi命令查看,在之后的CUDA编译测试里面也会出现问题,因此需要重新安装。重新安装的方式如下:
首先,检测NVIDIA图形卡和推荐的驱动程序的模型,在终端输入:ubuntu-drivers devices

从中可以看到,这里有一个设备是GTX 1070,对应的驱动是NVIDIA -390,所以安装390版本的驱动。选择安装所有推荐的驱动:
sudo ubuntu-drivers autoinstall
执行完命令后,在终端输入:nvidia-smi 可以得到相关信息。
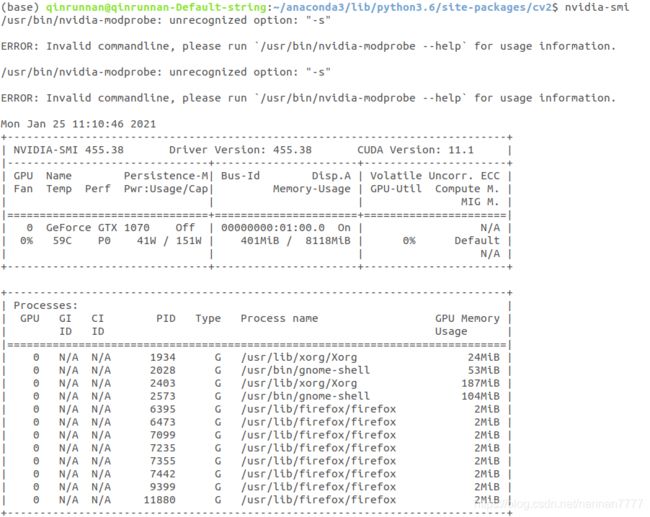
问题记录-06 -------------------------------------------------------------------------------------------------------
注意,这里一定要把驱动安装成功后再重启,否则会出现无法进入图形界面的问题,例如:
linux(ubuntu)16.04 开机报错“Stopping User Manager for UID 123”
一直黑屏,连命令行界面也进不去,吓出一身冷汗,差点就想删库跑路了…(危)
参考链接(强烈感谢这位大佬):https://blog.csdn.net/u012150360/article/details/90244858
解决思路:
Run mount -o rw,remount / to mount the drive in Read-Write mode.
Run sudo apt-get purge nvidia-* to purge the NVIDIA driver.
You may also need to purge xserver-xorg and reinstall it, which will require you to enable networking in Recovery.(apt-get purge xserver-xorg)
reboot 重启一下。
问题记录-07 -------------------------------------------------------------------------------------------------------
我在安装驱动时候采用命令行sudo ubuntu-drivers autoinstall没能安装成功,遇到问题:正试图覆盖...它同时被包含于软件包...在处理时有错误发生...,以及问题:
下列软件包有未满足的依赖关系:nvidia-driver-390 : 依赖:...... 但是它将不会被安装
后来将cuda重新卸载干净,添加显卡驱动源sudo add-apt-repository ppa:graphics-drivers/ppa。
之后更新附加驱动sudo apt-get updata,再次安装惊喜的发现成功了。
最后我这里的附加驱动界面如下所示:

---------------------------------------------------------------------------------------------------------------------------
因为Ubuntu18.04默认gcc7.0,而CUDA9.0只支持gcc6.0及以下版本,因此需要降级,这里选择降级到的版本是gcc5.5版本。
首先查看自己的版本:gcc –version,如果版本高于6.0,则需要降级版本并激活。
在终端输入:
sudo apt-get install gcc-5 g++-5
sudo update-alternatives --install /usr/bin/gcc gcc/usr/bin/gcc-5 50
sudo update-alternatives --install /usr/bin/g++ g++/usr/bin/g++-5 50
gcc –version
之后安装依赖库,在终端输入:
sudo apt-get install freeglut3-dev build-essential libx11-dev libxmu-dev
sudo apt-get install libxi-dev libgl1-mesa-glx libglu1-mesa libglu1-mesa-dev
之后在CUDA官网下载相关的CUDA版本,地址:
https://developer.nvidia.com/cuda-90-download-archive?target_os=Linux&target_arch=x86_64&target_distro=Ubuntu&target_version=1704&target_type=runfilelocal

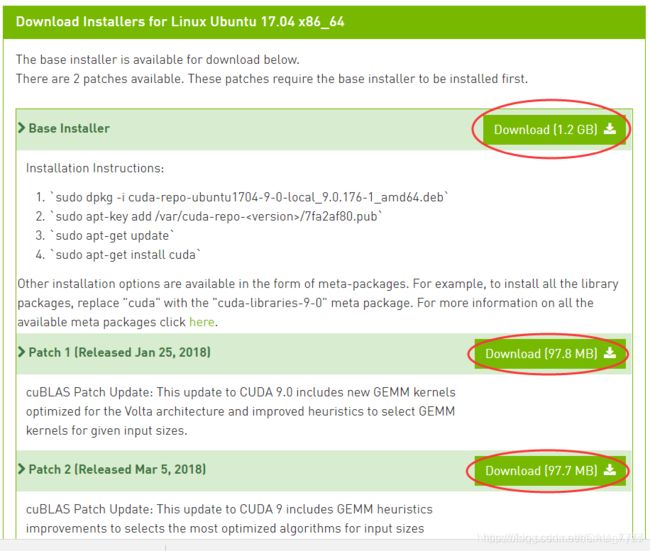
在安装包存放目录处打开终端输入:
sudo dpkg -i cuda-repo-ubuntu1704-9-0-local_9.0.176-1_amd64.deb
sudo apt-key add /var/cuda-repo-9-0-local/7fa2af80.pub
sudo dpkg -i cuda-repo-ubuntu1704-9-0-local-cublas-performance-update_1.0-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu1704-9-0-local-cublas-performance-update-2_1.0-1_amd64.deb
sudo apt-get update
继续在终端输入:
sudo apt-get install cuda
问题记录-08 -------------------------------------------------------------------------------------------------------
下列软件包有未满足的依赖关系: cuda : 依赖: cuda-9-0 (>= 9.0.176) 但是它将不会被安装
发现是因为自己关闭了更新。
如果你也遇到问题的话,请按步骤:系统设置-软件和更新-更新设置为下图即可:
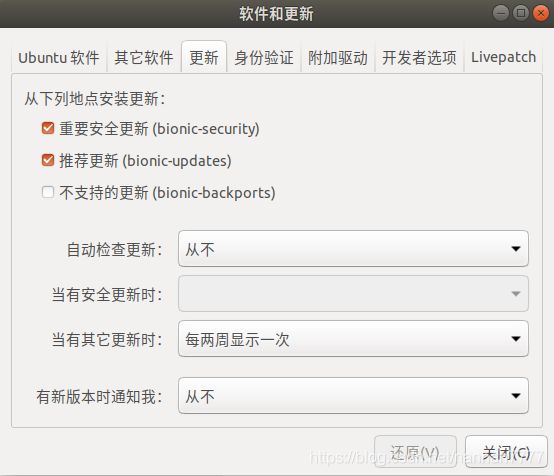
-------------------------------------------------------------------------------------------------------------------------
进入/usr/local目录下可以看到cuda和cuda-9.0两个文件夹,表明安装成功。
安装成功,接下来进行环境变量配置,步骤如下:
打开终端输入:sudo gedit ~/.bashrc
在打开的配置文件中,将以下内容写入末尾处.
export CUDA_HOME=/usr/local/cuda-9.0
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64:/usr/local/cuda-9.0/extras/CUPTI/lib64:$LD_LIBRARY_PATHs
export PATH=/usr/local/cuda-9.0/bin:$PATH
export LD_LIBRARY_PATH="/usr/local/cuda-9.0/lib64:/usr/local/cuda-9.0/extras/CUPTI/lib64:/usr/local/cuda-9.0/lib64:/usr/local/cuda-9.0/lib64"
使环境变量立即生效:source ~/.bashrc
最后对CUDA进行测试,可以进入例子的文件夹:cd /usr/local/cuda-9.0/samples/1_Utilities/deviceQuery,然后执行make命令:sudo make,最后运行Demo:./deviceQuery,如果结果有GPU的信息,说明安装成功,自此CUDA9.0安装配置完成。
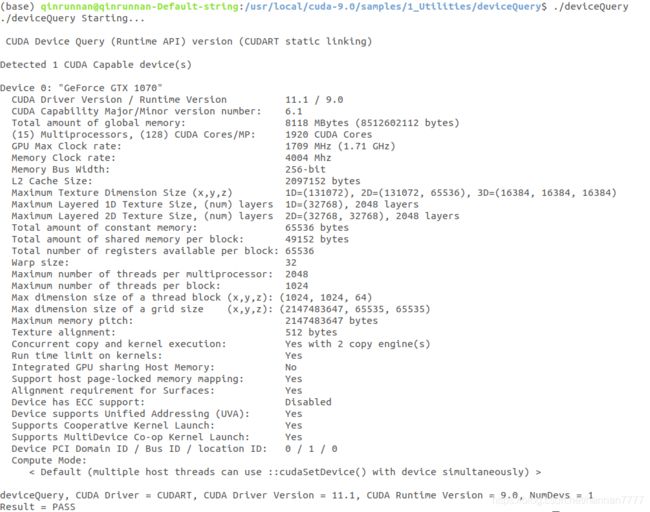
命令行输入nvcc -V可以查看CUDA的安装版本。
2.2)Cudnn7.1.4安装
官网下载链接:https://developer.nvidia.com/rdp/cudnn-archive
为适应Cudn9.0,这里下载的是CuDnnv7.1.4。下载的是.solitairetheme8格式的文件。安装步骤如下:
tar -xvzf cudnn-9.0-linux-x64-v7.solitairetheme8
#解压后的文件夹名称为cuda ,将对应文件复制到 /usr/local中的cuda内。
sudo cp cuda/include/cudnn.h /usr/local/cuda/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
#建立软连接
cd /usr/local/cuda/lib64/
sudo chmod +r libcudnn.so.7.6.4
sudo ln -sf libcudnn.so.7.6.4 libcudnn.so.7
sudo ln -sf libcudnn.so.7 libcudnn.so
sudo ldconfig
Cudnn安装成功,这里记录几个问题:
问题记录-09 -------------------------------------------------------------------------------------------------------
/usr/local/cuda-9.0/targets/x86_64-linux/lib/libcudnn.so.7 is not a symbolic link
如果后续在使用CUDA加速时遇到这个问题,首先打开libcudnn.so.7所在的目录:
cd /usr/local/cuda-9.0/lib64/
发现Libcudnn.so.7 和libcudnn.so.7.1.4 两个文件,但 理论上只有一个libcudnn.so.7.1.4。
重新链接库即可,在终端执行:
sudo ln -sf /usr/local/cuda-9.0/lib64/libcudnn.so.7.1.4 /usr/local/cuda-9.0/lib64/libcudnn.so.7
问题记录-10 -------------------------------------------------------------------------------------------------------
其实一开始我的Cudnn版本安装的是7.0.5,后续在import tensorflow as tf时遇到如下错误:
Loaded runtime CuDNN library: 7.0.5 but source was compiled with: 7.1.4.
CuDNN library major and minor version needs to match or have higher minor version in case of CuDNN 7.0 or later version.
If using a binary install, upgrade your CuDNN library.
因为tensorflow-gpu的库版本和Cudnn不匹配,要求cudnn版本为7.1.4,而我之前安装的版本是7.0.5,因此需要对cudnn进行升级,升级方法很简单,而且不会对现有安装环境造成破坏,升级完之后tensorflow还可以正常使用。
首先使用以下指令查看现有Cudnn的版本:
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
删除旧版本:
sudo rm -rf /usr/local/cuda/include/cudnn.h
sudo rm -rf /usr/local/cuda/lib64/libcudnn*
之后根据cuda和系统环境,在官网下载Cudnn的新版本,按照上文Cudnn的安装步骤重新安装。安装后再次查看Cudnn版本发现已更新,且调用不报错。
------------------------------------------------------------------------------------------------------------------------
3)Tensorflow-gpu 安装与配置
tensorflow-gpu的安装简直吐血,吐吐吐,尝试了1.5.0,1.8.0,1.13.0,1.14.0,最终我这里安装了
Tensorflow-gpu==1.12.0,踩坑无数。主要问题还是版本问题,要与CUDA版本匹配,同时要与后文Object Detection API版本匹配,否则就是删号重来的操作…
3.1)创建Conda虚拟环境
创建Conda虚拟环境并激活:
conda create -n tf=1.12 python=3.6
conda activate tf=1.12
问题记录-11 -------------------------------------------------------------------------------------------------------
“No module named conda”
python版本不小心被改变是产生这个错误的主要原因,我之前因为要安装ROS切换回了python2.7,后来再使用Anaconda就出现了上述问题。
解决方案:
如果之前的Anaconda安装包还在的话,执行直 bash -u 命令重新安装anaconda一遍,这种方法可以保存之前创建的虚拟环境:
bash Anaconda3-5.1.0-Linux-x86_64.sh -u
如果以上方法解决不了的话,直接下载最新的安装包(python版本对应上),安装Anaconda后,将之前的envs文件替换即可。
问题记录-12 -------------------------------------------------------------------------------------------------------
CondaHTTPError: HTTP 000 CONNECTION FAILED for url
可能的原因是版权问题,anaconda的国内镜像源停止anaconda的镜像服务。
解决方案:
在home文件夹下按下Ctrl+h,找到隐藏的文件.condarc
删除里面所有的内容,把下面的内容复制进去:
channels:
- defaults
show_channel_urls: true
ssl_verify: false
report_errors: false
问题记录-13 -------------------------------------------------------------------------------------------------------
CommandNotFoundError: Your shell has not been properly configured to use ‘conda activate‘
解决方案:
# 激活 anaconda 环境
source activate
# 退出 anaconda 环境
source deactivate
激活成功后在命令行的前面会出现:(base) [root@xxxx] #
------------------------------------------------------------------------------------------------------------------------
3.2)安装Tensorflow-gpu
就是在这里我发现CUDA9.1版本没有支持的Tensorflow-gpu,具体错误信息为
import tensorflow as tf时报错:ImportError: libcublas.so.9.0: cannot open shared object file: No such file or directory
虽然tiny mind开发了mind/wheels,即为Linux准备的特殊版本tensorflow,里面确实包含了支持CUDA9.1的tensorflow,参考链接:https://blog.csdn.net/gaoyu1253401563/article/details/82808269?utm_source=blogxgwz3
但实际上虽然我按照指引正确安装了支持CUDA9.1的tensorflow-gpu版本,但后面在测试Object Detection API时还是发现了很多版本不兼容的问题,因此全部卸载干净,使用了CUDA9.0与Tensorflow-gpu=1.12.0版本。
source activate tf=1.12
pip install tensorflow-gpu==1.12
安装完成后进入python环境,导入tensorflow查看是否安装成功:
import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!')
sess = tf.Session()
print(sess.run(hello))
要测试是否启用了GPU加速,可以用以下两行代码测试:
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
如果输出中有GPU的信息,说明GPU加速已经启用:
Sample Output
[name: "/cpu:0" device_type: "CPU" memory_limit: 268435456 locality { } incarnation: 4402277519343584096,
name: "/gpu:0" device_type: "GPU" memory_limit: 6772842168 locality { bus_id: 1 } incarnation: 7471795903849088328 physical_device_desc: "device: 0, name: GeForce GTX 1070, pci bus id: 0000:05:00.0" ]
问题记录-14 -------------------------------------------------------------------------------------------------------
ImportError: Something is wrong with the numpy installation.
While importing we detected an older version of numpy in [‘D:\Anaconda3\envs\tensorflow\lib\site-packages\numpy’].
One method of fixing this is to repeatedly uninstall numpy until none is found, then reinstall this version.
解决方案:
pip uninstall numpy
选择y确认卸载,重复命令,直到显示找不到时才为卸载干净。之后下载numpy:
pip install numpy
问题记录-15 -------------------------------------------------------------------------------------------------------
No module named 'absl'
解决方案:
方案一:指定版本安装:
pip install absl-py==0.1.10
方案二:删除后使用pip3进行安装:
1、删除site-packages文件夹中与absl-py相关的文件夹
2、输入以下命令:
pip3 install absl-py -i https://pypi.tuna.tsinghua.edu.cn/simple
问题记录-16 -------------------------------------------------------------------------------------------------------
之前在安装tensorflow-gpu其他版本时还遇到了如下几个问题:
ImportError: cannot import name 'keras_export'
ImportError: cannot import name 'tf_utils'
后来安装了tensorflow-gpu=1.12.0版本后问题得以解决,或者把tensorflow cpu的版本卸载后也会大力出奇迹。
------------------------------------------------------------------------------------------------------------------------
4)Object Detection API 框架搭建
血泪教训,这里一定不要直接git clone https://github.com/tensorflow/models.git获取源代码,而是去官网上的Releases板块中下载与tensorflow-gpu版本对应的源码版本,一定要对应否则会出现很多问题。
官网链接:https://github.com/tensorflow/models/releases
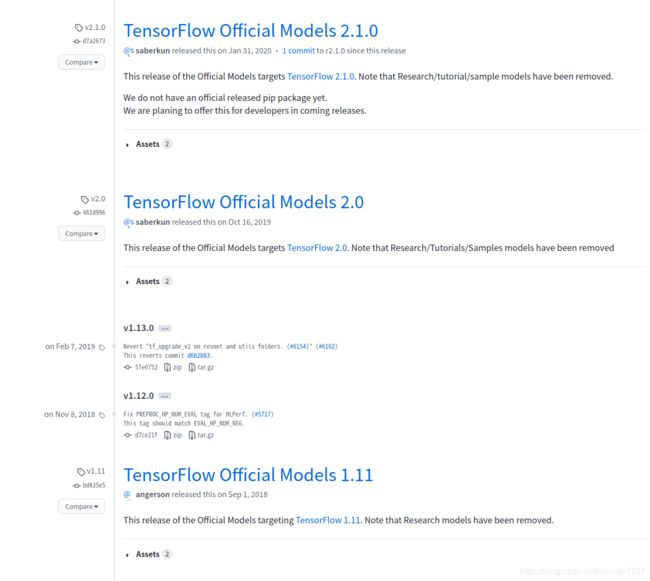
下载后放置在新建的tensorflow文件夹中,例如
之后按照如下命令行指令依次安装:
conda activate tf=1.12
# -------------------------------------------------
sudo apt-get install protobuf-compiler python-pil python-lxml python-tk
pip install --user Cython
pip install --user contextlib2
pip install --user pillow
pip install --user lxml
pip install --user jupyter
pip install --user matplotlib
# -------------------------------------------------
# COCO API installation
git clone https://github.com/cocodataset/cocoapi.git
cd cocoapi/PythonAPI
make
cp -r pycocotools <path_to_tensorflow>/models/research/
# -------------------------------------------------
# From tensorflow/models/research/
protoc object_detection/protos/*.proto --python_out=.
# -------------------------------------------------
# Add Libraries to PYTHONPATH
sudo gedit ~/.bashrc
export PYTHONPATH=$PYTHONPATH:/home/.../tensorflow/models/research/slim
source ~/.bashrc
# -------------------------------------------------
python setup.py build
python setup.py install
安装结束后,在/home/.../tensorflow/models/research/路径下执行测试代码:
python object_detection/builders/model_builder_test.py
如果正确显示如下信息,则证明Object Detection API 框架搭建成功,否则有问题一定要解决问题不能跳过,后面使用的时候才不会出现别的bug。
................
----------------------------------------------------------------------
Ran 16 tests in 0.112s
OK
问题记录-17 -------------------------------------------------------------------------------------------------------
Error: No module named 'tf_slim'
解决方案:跳转到/models/research/slim目录下安装:
python setup.py install
问题记录-18 -------------------------------------------------------------------------------------------------------
如果protobuf出现了问题,需要重新安装protobuf。虽然我这里没有用上,但依旧记录一下安装步骤:
首先安装相关的依赖包:
sudo apt-get install autoconf automake libtool curl make g++ unzip
下载protobuf安装包:https://github.com/google/protobuf/releases/
之后进入下载的protobuf安装包目录下面,依次执行以下命令:
./autogen.sh
./configure
make
make check
sudo make install
sudo ldconfig
测试安装:protoc --version,如果安装正确会输出版本号。
之后安装protobuf的python模块,进入protobuf安装包下的python文件目录,执行以下命令:
python setup.py build
python setup.py test
python setup.py install #(如果在这一步没有权限执行的话,就用sudo python setup.py install )
测试安装:
sudo python -c 'import google.protobuf;print google.protobuf.__version__'
----------------------------------------------------------------------------------------------------------------------
二/ 制作训练-测试数据集,训练MobileNet-SSD网络模型
1)按照VOC数据集格式制作训练-测试数据集
训练MobileNet-SSD网络模型时,官方的训练脚本采用的是读取VOC数据集,因此如果自己要制作新的数据集,仿照VOC数据集格式进行制作是最为便捷的方式。
1.1)制作VOC格式数据集
按照VOC数据集的要求,创建VOC2021文件夹,并在文件夹中创建如下子文件夹:
Annotations:用于存放标注后的xml文件,文件命名000000六位格式;
ImageSets/Main:用于存放训练集、测试集、验收集的文件列表;
JPEGImages:用于存放原始图像,图像命名000000六位格式。
注意标签文件和图片集文件路径中不要存在中文路径,不然训练可能会报相关utf-8 gbk的编码错误。
ImageSets/Main中存放的train.txt,val.txt, trainval.txt,test.txt的获取方法为:
import os
import random
trainval_percent = 0.5 #训练全集
train_percent = 0.5 #训练集
xmlfiles_path= 'Annotations'
txtsavepath = 'ImageSets/Main'
all_xmlfiles = os.listdir(xmlfiles_path)
num=len(all_xmlfiles)#图片xml总数
xmlfiles_list=range(num) #列表
num_val=int(num*trainval_percent)#训练全集数
num_tra=int(num_val*train_percent)#训练全集中训练集数
trainval= random.sample(xmlfiles_list,num_val)#在全部图片xml中随机取训练全集数
train=random.sample(trainval,num_tra)#在训练全集中随机取训练集数
trainval_file = open(txtsavepath+'/trainval.txt', 'w')
test_file = open(txtsavepath+'/test.txt', 'w')
train_file = open(txtsavepath+'/train.txt', 'w')
val_file= open(txtsavepath+'/val.txt', 'w')
for i in xmlfiles_list:
name=all_xmlfiles[i][:-4]+'\n' #[:-4]从0开始到倒数第4个但不包括该位 此时为6位数图片名称.即文件名称000000.xml去掉.xml保留数字
if i in trainval:
trainval_file.write(name)
if i in train:
train_file.write(name)
else:
val_file.write(name)
else:
test_file.write(name)
trainval_file.close()
train_file.close()
val_file.close()
test_file.close()
1.2).record格式的样本生成
*将object_detection/dataset_tools/create_pascal_tf_record.py中Line164和Line165:
examples_path = os.path.join(data_dir, year, 'ImageSets', 'Main',
'aeroplane_' + FLAGS.set + '.txt')
修改为:
examples_path = os.path.join(data_dir, year, 'ImageSets', 'Main', FLAGS.set + '.txt')
## 'aeroplane_' + FLAGS.set + '.txt')
并在Line56中添加数据集所在的文件夹名称:
YEARS = ['VOC2007', 'VOC2012', 'VOC2021', 'merged']
将/research/object_detection/data/pascal_label_map.pbtxt备份一个到别的路径下,例如object_detection/ssd_model/路径下,之后将里面的内容替换为自己数据集里的标签与类别数量。
最后执行如下命令行分别生成.record格式的训练集与验证集:
python object_detection/dataset_tools/create_pascal_tf_record.py --label_map_path=/home/.../tensorflow/models/research/object_detection/ssd_model/pascal_label_map.pbtxt --data_dir=/home/.../tensorflow/models/research/object_detection/ssd_model/VOCdevkit --year=VOC2021 --set=train --output_path=/home/.../tensorflow/models/research/object_detection/ssd_model/pascal_train.record
python object_detection/dataset_tools/create_pascal_tf_record.py --label_map_path=/home/.../tensorflow/models/research/object_detection/ssd_model/pascal_label_map.pbtxt --data_dir=/home/.../tensorflow/models/research/object_detection/ssd_model/VOCdevkit --year=VOC2021 --set=val --output_path=/home/.../tensorflow/models/research/object_detection/ssd_model/pascal_val.record
2)训练MobileNet-SSD网络模型
2.1)配置.config文件
将object_detection\samples\configs\ssd_mobilenet_v2_coco.config另存为ssd_mobilenet_v2_pascal.config,并备份一个到别的路径下,例如object_detection/ssd_model/路径下,之后对该文件进行修改:
修改1: 将Line9修改为自己数据集的类别数目:
num_classes: 9
修改2: 如果GPU加速性能较弱,需要将Line43中的网络输入尺寸调小:
image_resizer {
fixed_shape_resizer {
height: 128
width: 128
}
}
修改3: 如果GPU加速性能较弱,需要将Line141中的批处理大小调小:
batch_size: 8
修改4: Line156为预训练权重路径,可以将其注释,从头开始训练:
fine_tune_checkpoint: "/home/lqs/models/ssd_mobilenet_v2_coco_2018_03_29/model.ckpt"
修改5: Line173,修改训练集train_input_reader路径:
train_input_reader: {
tf_record_input_reader {
input_path: "/home/.../tensorflow/models/research/object_detection/ssd_model/pascal_train.record"
}
label_map_path: "/home/.../tensorflow/models/research/object_detection/ssd_model/pascal_label_map.pbtxt"
}
修改6: Line182,修改验证集val_input_reader路径:
val_input_reader: {
tf_record_input_reader {
input_path: "/home/.../tensorflow/models/research/object_detection/ssd_model/pascal_val.record"
}
label_map_path: "/home/.../tensorflow/models/research/object_detection/ssd_model/pascal_label_map.pbtxt"
shuffle: false
num_readers:1
}
2.2)启动训练
执行如下命令行启动训练过程:
python object_detection/legacy/train.py --train_dir object_detection/ssd_model/train --pipeline_config_path object_detection/ssd_model/ssd_mobilenet_v2_pascal.config
可以执行如下命令行进行训练过程的Loss损失可视化:
tensorboard --logdir=/home/.../tensorflow/models/research/object_detection/ssd_model/train/
将终端输出的http://xxxxxx网址复制到浏览器中打开即可查看。

训练结束后可以固化权重,获得标准的.pb格式文件。
python object_detection/export_inference_graph.py --input_type image_tensor --pipeline_config_path object_detection/ssd_model/ssd_mobilenet_v2_pascal.config --trained_checkpoint_prefix object_detection/ssd_model/train/model.ckpt-100000 --output_directory object_detection/ssd_model/model/
问题记录-19 -------------------------------------------------------------------------------------------------------
tensorboard ValueError: Duplicate plugins for name projector
在查看训练过程可视化时发现如上错误,解决办法为:
在Conda虚拟环境的目录site-packages文件夹下, 删掉tensorboard--1.x.xdist-info 即可。
问题记录-20 -------------------------------------------------------------------------------------------------------
''tensorflow.python.framework.errors_impl.ResourceExhaustedError: OOM when allocating tensor with shape[?]''
这是tensorflow 一个经常性错误,错误的原因在于:显卡内存不够。
解决方法就是降低显卡的使用内存,途径有以下几种措施:
1 减少Batch 的大小;
2 分析错误的位置,在哪一层出现显卡不够,比如在全连接层出现的,则降低全连接层的维度;
3 增加pool 层,降低整个网络的维度;
4 修改输入图片的大小。
问题记录-21 -------------------------------------------------------------------------------------------------------
ImportError: No module named cv2
在进行图像测试时遇到了这个问题,解决这个问题首先确保OpenCV安装正确,之后安装python-opencv:
sudo apt-get install python-opencv
查看是否解决,如果没有解决执行后续步骤:
如果没有用anaconda,找到cv2.so文件find / -name "cv2.so",复制到usr/local/lib/python2.7/site-packages文件夹下。
如果用的是anaconda2,复制cv2.so到home/anaconda2/lib/python2.7/site-packages文件夹下;如果使用的是anaconda3,找到cv2.cpython-36m-x86_64-linux-gnu.so,复制v2.cpython-36m-x86_64-linux-gnu.so到home/anaconda3/lib/python3.6/site-packages文件夹。
然后在终端cd到home,输入python然后输入import cv2,此时如果没有提示错误就证明已经解决了这个问题。
----------------------------------------------------------------------------------------------------------------------
2.3)测试训练效果
依旧在/home/…/tensorflow/model/research/路径下执行如下命令行,调用官方提供的测试脚本进行测试评估:
python object_detection/legacy/eval.py --logtostderr --checkpoint_dir=object_detection/ssd_model/train --eval_dir=object_detection/ssd_model/eval --pipeline_config_path=object_detection/ssd_model/ssd_mobilenet_v2_pascal.config
问题记录-22 -------------------------------------------------------------------------------------------------------
ModuleNotFoundError: No module named 'pycocotools'
如果遇到这个问题,表明Object Detection API搭建过程中pycocotools工具未成功搭建,重新执行:
# COCO API installation
git clone https://github.com/cocodataset/cocoapi.git
cd cocoapi/PythonAPI
make
cp -r pycocotools <path_to_tensorflow>/models/research/
问题记录-23 -------------------------------------------------------------------------------------------------------
File "/home/qinrunnan/tensorflow/models/research/object_detection/utils/object_detection_evaluation.py", line 307, in evaluate
category_name = unicode(category_name, 'utf-8')
NameError: name 'unicode' is not defined
这个问题与python版本有关,可以将object_detection_evaluation.py文件中的307行修改为:
category_name = category_name
----------------------------------------------------------------------------------------------------------------------
三/ 搭建OpenVINO™ toolkit 框架与相关环境,以及VPU加速推理
1)搭建OpenVINO™ toolkit 框架与环境
OpenVINO toolkit分为开源版与Intel版,其中Intel版是Intel发布的专注于推理的深度学习框架,其特点是可将TensorFlow、caffe、ONNX等模型转换为Intel系列硬件兼容的模型,包括Movidius与Movidius NCS 2。
Intel官网下载toolkit for linux 安装包,下载地址:
https://software.intel.com/en-us/openvino-toolkit/choose-download/free-download-linux
官方安装教程:https://docs.openvinotoolkit.org/latest/openvino_docs_install_guides_installing_openvino_linux.html
我这里购买的是神经元计算棒2代,记录一下在台式机下搭建intel神经元计算棒开发环境的完整过程。
1.1)安装OpenVINO™ toolkit
首先进入下载地址,选择Linux版,点击注册与下载,会收到一封邮件,里面有激活码与下载地址。
在官网可以下载到toolkit:l_openvino_toolkit_.tgz,我这里用的版本是2020.2.120,在所在目录下解压:
tar xvf l_openvino_toolkit_2018.4.420.tgz
解压后进入文件夹:cd l_openvino_toolkit_2018.4.420
安装依赖环境:
./install_cv_sdk_dependencies.sh
打开安装的GUI界面:
./install_GUI.sh
此时会出现如下界面,按照一般安装软件的步骤运行即可。

之后OpenVino平台在CPU、GPU、计算棒VPU上都能够提供加速推理支持。
1.2)配置神经元计算棒2代硬件驱动
更新udev规则使工具套件能够与神经计算棒通信。
为此,在终端窗口运行以下命令:cd ~/Downloads,然后一次性复制以下一大块代码到命令行中:
cat < 97-usbboot.rules
SUBSYSTEM=="usb", ATTRS{idProduct}=="2150", ATTRS{idVendor}=="03e7", GROUP="users", MODE="0666", ENV{ID_MM_DEVICE_IGNORE}="1"
SUBSYSTEM=="usb", ATTRS{idProduct}=="2485", ATTRS{idVendor}=="03e7", GROUP="users", MODE="0666", ENV{ID_MM_DEVICE_IGNORE}="1"
SUBSYSTEM=="usb", ATTRS{idProduct}=="f63b", ATTRS{idVendor}=="03e7", GROUP="users", MODE="0666", ENV{ID_MM_DEVICE_IGNORE}="1"
EOF
之后,一行一行运行以下命令:
sudo cp 97-usbboot.rules /etc/udev/rules.d/
sudo udevadm control --reload-rules
sudo udevadm trigger
sudo ldconfig
rm 97-usbboot.rules
问题记录-24 -------------------------------------------------------------------------------------------------------
注:在运行到“sudo ldconfig”时可能会找不到链接文件,解决方法如下:
进入.so文件所在的路径,按以下命令建立链接:
再次执行“sudo ldconfig”就不会报错了。
----------------------------------------------------------------------------------------------------------------------
1.3)测试安装
将神经计算棒插入计算机的 USB 端口,第一次运行这些命令时,可能需要一些时间,因为脚本要安装软件依赖项并编译所有样本代码。
cd ~/opt/intel/computer_vision_sdk/deployment_tools/model_optimizer/install_prerequisites/
./install_prerequisites.sh
执行如下测试代码:
cd ~/opt/intel/computer_vision_sdk/deployment_tools/demo
sudo ./demo_squeezenet_download_convert_run.sh -d MYRIAD
这个demo是对于一幅汽车的图像进行分类检测,输出的预测类型与概率。参数文件来自caffe,模型是squeezeNet。执行过程中要下载模型参数,程序自动转换caffemodel到计算棒可以执行的graph文件,最后程序开始运行推理。
至此,demo已经可以在计算棒上运行了,验证安装无误。
问题记录-25 -------------------------------------------------------------------------------------------------------
[ ERROR ] Can not init Myriad device: NC_ERROR
首先查看是否是硬件问题,推荐一个大佬的技术博客:https://blog.csdn.net/weixin_42730667/article/details/99676804
如果测试后发现能够正常发现设备,说明PC和计算棒能够正常通信,不是硬件问题。最后发现这个问题是因为运行时需要输入管理员密码,应该是权限问题,重新运行:
sudo ./demo_security_barrier_camera.sh -d MYRIAD
-----------------------------------------------------------------------------------------------------------------------------
2)使用VPU加速推理训练好的tensorflow模型
上面的步骤都是在跑官方提供的已经编译好的模型文件。下面介绍一下如何加速推理一个自己训练的tensorflow模型。
2.1)将自己训练好的Tensorflow模型转换为IR模型
官方教程:
https://docs.openvinotoolkit.org/latest/openvino_docs_install_guides_installing_openvino_linux.html
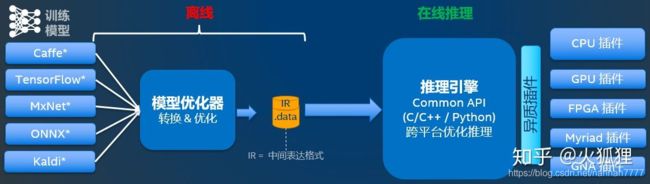
OpenVINO提供了深度学习推理套件(DLDT),该套件可以将各种开源框架训练好的模型进行线上部署。这里摘录一个原理概念图,描述的非常到位:
首先配置Tensorflow模型转换为IR模型所依赖的环境元素,在base环境下无需在conda的虚拟环境(否则会出现tensorflow版本冲突问题):
cd /opt/intel/openvino_2020.2.120/deployment_tools/model_optimizer/install_prerequisites
sudo ./install_prerequisites.sh
这个脚本能够安装支持 Caffe, TensorFlow 1.x, MXNet, Kaldi*, 以及 ONNX模型转换的所有基础环境依赖。
或者也可以仅安装支持Tensorflow模型转换的环境依赖:
cd /opt/intel/openvino_2020.2.120/deployment_tools/model_optimizer/install_prerequisites
sudo ./install_prerequisites_tf.sh #For TensorFlow 1.x:
sudo ./install_prerequisites_tf2.sh #For TensorFlow 2.x:
之后执行如下命令行进行.pb格式的Tensorflow模型转换工作,转为.bin与.xml格式文件:
sudo python mo_tf.py --input_model /opt/intel/openvino_2020.2.120/deployment_tools/model_optimizer/SSD_Mobilenet_V2_IR/tx2_model/frozen_inference_graph.pb --output=detection_boxes,detection_scores,num_detections -o /opt/intel/openvino_2020.2.120/deployment_tools/model_optimizer/SSD_Mobilenet_V2_IR/IR_Models/ --tensorflow_use_custom_operations_config /opt/intel/openvino_2020.2.120/deployment_tools/model_optimizer/extensions/front/tf/ssd_v2_support.json --tensorflow_object_detection_api_pipeline_config /opt/intel/openvino_2020.2.120/deployment_tools/model_optimizer/SSD_Mobilenet_V2_IR/tx2_model/pipeline.config -b 8 --data_type FP16 --reverse_input_channels
注:-b后填写Tensorflow模型在训练时的批处理batch_size大小。
不要参考官方给出的命令行,不能用,参考这里提炼的上述代码,亲测可行。
2.2)将IR推理模型转换为二进制blob文件格式
有时候IR推理模型在调用时会出现无法读取或不稳定的问题,这时候需要将IR推理模型转换为二进制blob文件格式。
执行如下代码,将OpenVINO的IR模型转成blob模型:
cd /opt/intel/openvino_2020.2.120/deployment_tools/inference_engine/lib/intel64
set +u
source /opt/intel/openvino_2020.2.120/bin/setupvars.sh
set -u
export MYRIAD_COMPILE=$(find /opt/intel/ -iname myriad_compile)
$MYRIAD_COMPILE -m /home/....../frozen_inference_graph.xml -ip U8 -VPU_MYRIAD_PLATFORM VPU_MYRIAD_2480 -VPU_NUMBER_OF_SHAVES 4 -VPU_NUMBER_OF_CMX_SLICES 4
同样的,不要参考官方给出的命令行,也不能用,参考这里提炼的上述代码,亲测可行。
注:.xml与.bin文件需要放在有管理员权限的路径下,并且两个文件需要在相同路径下,否则会报错:
1. blob file can not be opened for export
2. blob file can not be opened for export Unknown arguments: 0x200000000
solve: also need .bin file ->IR(bin,xml)
问题记录-26 -------------------------------------------------------------------------------------------------------
[Bug] myriad_compile fails with "Unexpected network type"
libinference_engine.so: cannot open shared object file
这个问题就是我按照官方文档给出的命令行测试时遇到的问题,替换为上述代码即可解决。
参考链接:https://github.com/openvinotoolkit/openvino/issues/3703
-----------------------------------------------------------------------------------------------------------------------------
2.3)使用VPU进行实际加速推理测试
初始化openvino环境:
source /opt/intel/openvino/bin/setupvars.sh
重新编译检测脚本:
/opt/intel/openvino_2020.2.120/inference_engine/samples/cpp
./build_samples.sh
使用MobileNet-SSD检测脚本对IR模型进行测试:
python /opt/intel/openvino_2020.2.120/deployment_tools/inference_engine/samples/python/object_detection_sample_ssd/object_detection_sample_ssd.py -i /home/.../test.png -m /opt/intel/openvino_2020.2.120/deployment_tools/model_optimizer/SSD_Mobilenet_V2_IR/IR_Models/frozen_inference_graph.xml -d CPU
我使用这个object_detection_sample_ssd.py py脚本调用测试没能成功,可能还是跟环境有关。
这里是通过C++文件编译后进行测试的:
cd /home/qinrunnan/inference_engine_cpp_samples_build/intel64/Release/
./object_detection_sample_ssd -i /home/.../1.png -m /opt/intel/openvino_2020.2.120/deployment_tools/model_optimizer/SSD_Mobilenet_V2_IR/IR_Models/frozen_inference_graph.xml -d CPU
最后插入神经网络加速棒,进行VPU推理加速测试:
./object_detection_sample_ssd -i /home/.../test.png -m /opt/intel/openvino_2020.2.120/deployment_tools/model_optimizer/SSD_Mobilenet_V2_IR/IR_Models/frozen_inference_graph.xml -d MYRIAD
-----------------------------------------------------------------------------------------------------------------------------
至此本部分内容已经全部结束,回家过年啦,新年快乐~~
最近沉迷人像摄影的乔木小姐
2021.02.03