利用随机森林算法对红酒数据集进行分类预测+对下载的人口数据集进行分类预测
随机森林算法可以很好的解决决策树算法的过拟合问题
def j2():
'''随机森林可以很好的解决决策树的过拟合问题'''
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
wine=load_wine()
#选择数据集的前两个特征
x=wine.data[:,:2]
y=wine.target
#
x_train, x_test, y_train, y_test = train_test_split(x, y)
#设定随机森林有10棵树
forest=RandomForestClassifier(n_estimators=6,random_state=3)
#n_estimators是控制决策树的数量, bootstrap=True放回抽样的意思,为了让每一个决策树都不一样。max_features越高,决策树越象。
#拟合数据
forest.fit(x_train,y_train)
#我们用图像直观的发现随即森林的过程
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
# 分别用样本的两个特征值去创建图像的横轴和纵轴
x_min, x_max = x_train[:, 0].min() - 1, x_train[:, 0].max() + 1
y_min, y_max = x_train[:, 1].min() - 1, x_train[:, 1].max() + 1
import numpy as np
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02), np.arange(y_min, y_max, .02))
z = forest.predict(np.c_[xx.ravel(), yy.ravel()])
# 给每个分类样本分配不一样的颜色
import matplotlib.pyplot as plt
z = z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, z, cmap=cmap_light)
# 用散点把样本表示出来
plt.scatter(x[:, 0], x[:, 1], c=y, cmap=cmap, edgecolors='k', s=20)
plt.xlim()
plt.ylim()
plt.title('Classifier:RandomForest') # 深度为1
plt.show()
'''最关键的一点是,随机森林支持多进程并行处理,n_jobs=1,可以全开CPU '''
'''针对超高维数据集和稀疏数据来说,线性模型要好很多'''
#'''找一个红酒数据,我们进行预测'''
wine_data=[[0,1]]#因为前面我们只选择数据集的两个特征值
predict=forest.predict(wine_data)
if predict==1:
print('这是一款好的红酒')
else:
print('这不是我们想要的红酒')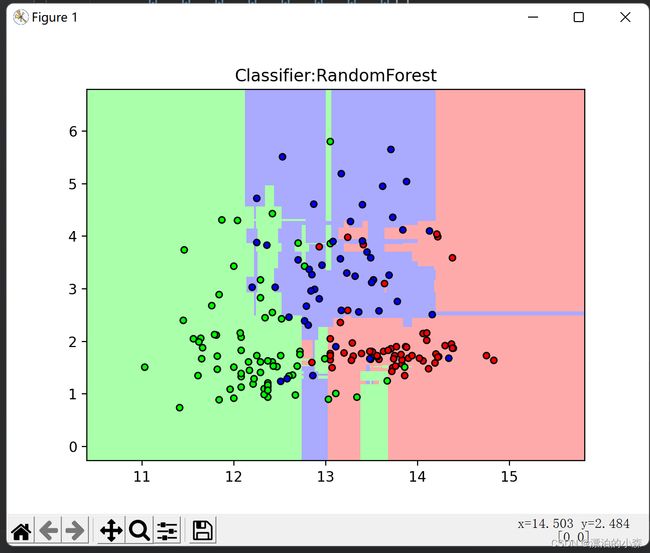
预测结果:这是一款好的红酒
下面对一个人口的数据集进行模拟预测:
def j3():#以1994年美国人口普查的数据集为例子,让决策树和随机森林模型对其进行分析
'我们从外部下载数据集,然后导入进去'
import pandas as pd
data=pd.read_csv('adult.csv',header=None,index_col=False,names=['年龄','单位性质','权重','学历','受教育时长','婚姻状况','职业','家庭情况','种族','性别','资产所得','资产损失','周工作时长','原籍','收入'])
data_list=data[['年龄','单位性质','学历','性别','周工作时长','职业','收入']]#只选取一部分数据
print(data_list.head())
'''我们会发现下载的数据都是字符串,不是我们要的整数型数值0和1,这就需要我们对数据进行处理'''
data_change=pd.get_dummies(data_list)#使用get_dummies将文本数据变成数值,就是在原有的数据集上添加了虚拟变量
#将对比原始特征和虚拟变量特征
print('样本的原始特征:\n',list(data_list.columns),'\n')
print('虚拟变量特征:\n',list(data_change.columns))
'显示数据集的前5行'
print(data_change.head())
'''我们接下来将数据值分配给特征向量X和分类标签y'''
#定义数据集的特征值
features=data_change.loc[:,'年龄':'职业_ Transport-moving']
#将特征数值赋予为x
x=features.values
#将收入大于50k作为预测目标
y=data_change['收入_ >50K'].values
print('特征形态:{} 标签形态;{}'.format(x.shape,y.shape))
'''对数据进行处理完之后就可以进行数据集的划分和模型的训练'''
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=0)
#用决策树拟合数据
from sklearn.tree import DecisionTreeClassifier
dt=DecisionTreeClassifier(max_depth=6)
dt.fit(x_train,y_train)
print('训练模型得分:', '%.2f' % dt.score(x_train, y_train))
print('测试模型得分:','%.2f'%dt.score(x_test,y_test))
'''然后我们可以通过这个模型来预测一个数据是不是我们需要的'''
#将一个人的数据放入进去
Mr_hua=[[24,40,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,1,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0]]
datig=dt.predict(Mr_hua)#预测是标签值
if datig==1:
print('这是我们需要的精英顶端人才')
else:
print('这不是我们需要的人才')
'''当然,我们也可以用随机森林来进行预测结果'''
from sklearn.ensemble import RandomForestClassifier
rf=RandomForestClassifier(n_estimators=10,random_state=0,n_jobs=1)
rf.fit(x_train,y_train)
print('训练模型得分:', '%.2f' % rf.score(x_train, y_train))
print('测试模型得分:', '%.2f' % rf.score(x_test, y_test))
Mr_hua = [
[24, 40, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]]
dating = rf.predict(Mr_hua) # 预测是标签值
if dating == 1:
print('这是我们需要的精英顶端人才')
else:
print('这不是我们需要的人才')
以上代码,大家可以当作学习练习,来理解决策树和随机森林对于我们机器学习处理数据集的一些知识。
如有错误敬请指正