(人工智能)线性分类的Jupyter实践
目录
- 一、准备工作
-
- 1、安装Anaconda
- 2、安装实验所需包
- 二、实验步骤
-
- 1、打开终端
- 2、取萼片的长宽作为特征进行分类
- 3、取花瓣的长宽作为特征进行分类
- 三、参考博客
一、准备工作
1、安装Anaconda
Anaconda
2、安装实验所需包
在安装好Anaconda后,可以在开始处打开
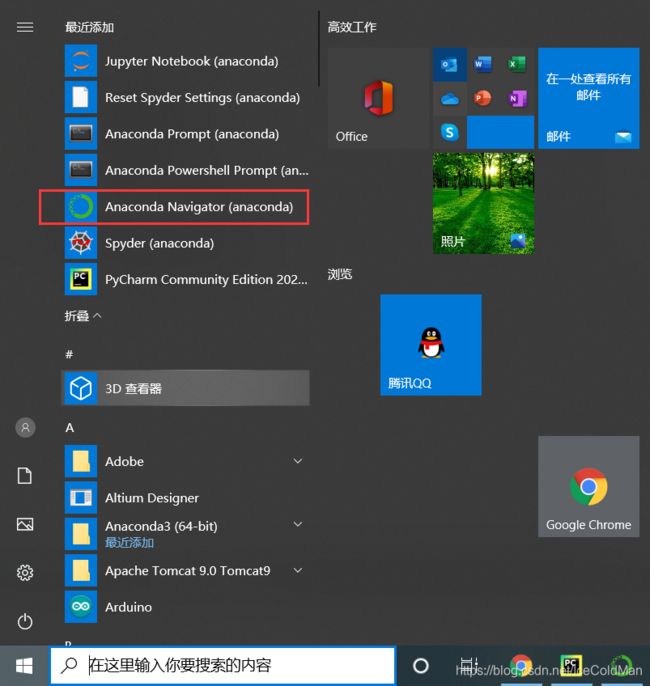
打开后创建一个命令虚拟环境
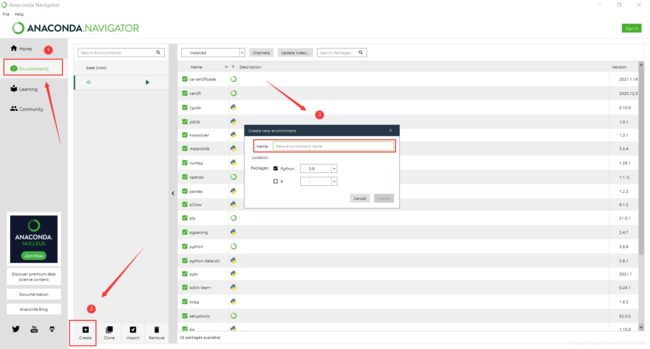
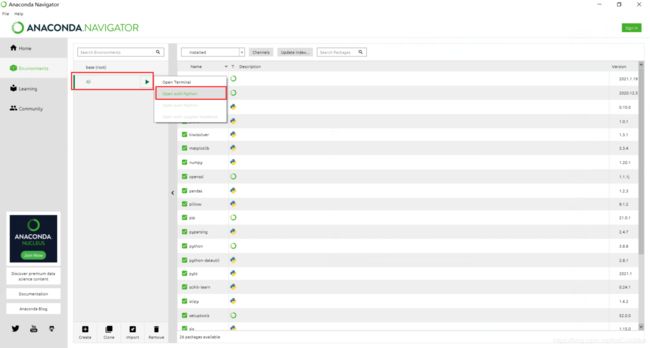
创建好后打开终端

在终端写入以下命令下载相关包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名
此处安装的包包括numpy、pandas、sklearn、matplotlib
二、实验步骤
1、打开终端
2、取萼片的长宽作为特征进行分类
以下命令可一次性全部复制,然后粘贴到终端,终端会自动一行一行处理
(1)、导入相关包
#导入相关包
import numpy as np
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn import datasets
from sklearn import preprocessing
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
(2)、获取数据集
# 获取所需数据集
iris=datasets.load_iris()
#每行的数据,一共四列,每一列映射为feature_names中对应的值
X=iris.data
print(X)
#每行数据对应的分类结果值(也就是每行数据的label值),取值为[0,1,2]
Y=iris.target
print(Y)
(3)、对数据进行处理
#归一化处理
X = StandardScaler().fit_transform(X)
print(X)
(4)、训练模型
lr = LogisticRegression() # Logistic回归模型
lr.fit(X, Y) # 根据数据[x,y],计算回归参数
(5)、绘制分类后的图像
N, M = 500, 500 # 横纵各采样多少个值
x1_min, x1_max = X[:, 0].min(), X[:, 0].max() # 第0列的范围
x2_min, x2_max = X[:, 1].min(), X[:, 1].max() # 第1列的范围
t1 = np.linspace(x1_min, x1_max, N)
t2 = np.linspace(x2_min, x2_max, M)
x1, x2 = np.meshgrid(t1, t2) # 生成网格采样点
x_test = np.stack((x1.flat, x2.flat), axis=1) # 测试点
cm_light = mpl.colors.ListedColormap(['#77E0A0', '#FF8080', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
y_hat = lr.predict(x_test) # 预测值
y_hat = y_hat.reshape(x1.shape) # 使之与输入的形状相同
plt.pcolormesh(x1, x2, y_hat, cmap=cm_light) # 预测值的显示
plt.scatter(X[:, 0], X[:, 1], c=Y.ravel(), edgecolors='k', s=50, cmap=cm_dark)
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.grid()
plt.show()

(6)、预测模型
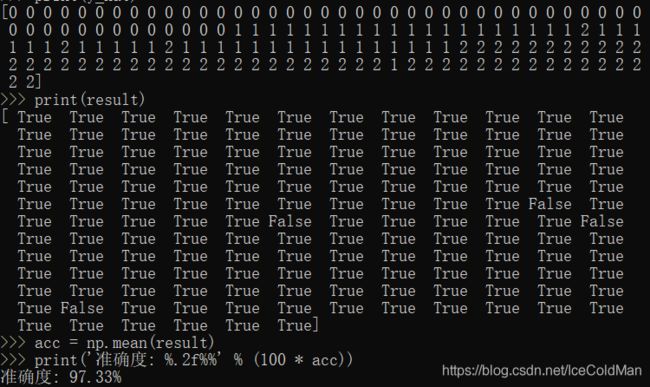
y_hat = lr.predict(X)
Y = Y.reshape(-1)
result = y_hat == Y
print(y_hat)
print(result)
acc = np.mean(result)
print('准确度: %.2f%%' % (100 * acc))
3、取花瓣的长宽作为特征进行分类
方法跟上面一样,主要是数据处理上,取后面两个特征值
X=X[:,2:]
三、参考博客
https://blog.csdn.net/qq_43279579/article/details/115120795